
Previously we focused on types available in Parquet. This time we can move forward and analyze how the framework stores the data in the files.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post concentrates on the organization of Parquet files. It's divided in 2 theoretical sections. The first one present the structure of the file with a special zoom on metadata. The second section talks about row pages and column chunks, namely the parts storing data physically. The very last part of this post gives some code examples about Parquet files internals.
File organization
Parquet file is composed of several different parts. It begins by magic bytes number. This marker is mainly used to check if the file is really the file written in Parquet format. We can see plenty of checks using this information in ParquetFileReader class:
int FOOTER_LENGTH_SIZE = 4;
if (fileLen < MAGIC.length + FOOTER_LENGTH_SIZE + MAGIC.length) { // MAGIC + data + footer + footerIndex + MAGIC
throw new RuntimeException(filePath + " is not a Parquet file (too small)");
}
The next layer affects row groups, column chunks and pages data that will be described more in details in subsequent sections. For now simply remember that each row group includes column chunks and each column chunk includes data pages.
At the end of the file we retrieve footer. It contains plenty of useful information to read and process Parquet files efficiently called file metadata, such as:
- the schema of stored data
- metadata:
- custom metadata - this part contains the information that can be defined by the client writing application. It's the place where we'll find often the schemas of serializable librairies as Avro or Protobuf. The custom metadata is defined by the implementations of abstract WriteSupport class. After the definition is passed to the org.apache.parquet.hadoop.api.WriteSupport.WriteContext#WriteContext that is responsible to transform the map to its immutable representation. The representation is later saved in the footer part of the file.
- number of rows in the file
- list of row groups in the file where each of them has following information:
- total size in bytes
- number of rows in given group
- the information about column chunks included in the group:
- the path to the file storing the data. But when it's missing, it means that the data is stored in the same file as the metadata
- byte offset to column chunk metadata in the file containing the data
- column chunk metadata:
- the path in the schema - internally it's stored as a list because it can contain nested elements. For instance, for a field of list type, the path looks like [field_name, array]
- type of the field
- applied compression codec
- applied encodings
- total number of values (= not distinct values)
- total size in bytes for given column chunk (also for uncompressed fields)
- statistics - but note that the statistics aren't included for all fields. Because of corruption detected in PARQUET-251 JIRA ticket, the statistics use is controled by some conditions:
- for binary or fixed array length data type the statistics are ignored
- empty created_by also makes the stats to be ignored
- file created prior to Parquet 1.8.0 also invalidates the statistics
- offsets
- for the first data page in the chunk
- for the first byte in the chunk - because of the eventual presence of dictionary it can be different than the offset from the previous point
- for the dictionary if is defined
Thrift definition marks struct ColumnChunk as optional under RowGroup. However in the code, at least for the writers using org.apache.parquet.format.converter.ParquetMetadataConverter, column chunk metadata is always written in the footer:List<ColumnChunkMetaData> columns = block.getColumns(); List<ColumnChunk> parquetColumns = new ArrayList<ColumnChunk>(); for (ColumnChunkMetaData columnMetaData : columns) { ColumnChunk columnChunk = new ColumnChunk(columnMetaData.getFirstDataPageOffset()); // verify this is the right offset columnChunk.file_path = block.getPath(); // they are in the same file for now columnChunk.meta_data = new ColumnMetaData( getType(columnMetaData.getType()), toFormatEncodings(columnMetaData.getEncodings()), Arrays.asList(columnMetaData.getPath().toArray()), columnMetaData.getCodec().getParquetCompressionCodec(), columnMetaData.getValueCount(), columnMetaData.getTotalUncompressedSize(), columnMetaData.getTotalSize(), columnMetaData.getFirstDataPageOffset());
- optionally the sorting column(s)
- optionally the name of the application that wrote the file, for instance: parquet-mr version 1.9.0 (build 38262e2c80015d0935dad20f8e18f2d6f9fbd03c). It should follow the model: ${application_name} version ${application_version} (build ${build_hash})>
Data storage in the file
The row group is a structure with the data. To see its content, let's go to the org.apache.parquet.hadoop.InternalParquetRecordWriter#flushRowGroupToStore invoked every time when the threshold of bufferized data is reached:
if (recordCount > 0) {
parquetFileWriter.startBlock(recordCount);
columnStore.flush();
pageStore.flushToFileWriter(parquetFileWriter);
recordCount = 0;
parquetFileWriter.endBlock();
this.nextRowGroupSize = Math.min(
parquetFileWriter.getNextRowGroupSize(),
rowGroupSizeThreshold);
}
As you already know, the row group contains the column chunks that in their turn contain the pages. The pages are written with org.apache.parquet.column.page.PageWriter#writePageV2 method (or without V2 if it's the 1st version):
parquetMetadataConverter.writeDataPageV2Header(
uncompressedSize, compressedSize,
valueCount, nullCount, rowCount,
statistics,
dataEncoding,
rlByteLength,
dlByteLength,
tempOutputStream);
buf.collect(
BytesInput.concat(
BytesInput.from(tempOutputStream),
repetitionLevels,
definitionLevels,
compressedData)
);
By analyzing what this method does we can find that the following information is written to the pages:
- page header with:
- optional CRC checksum value
- compressed and uncompressed size
- number of rows
- number of null values
- number of values (nulls included)
- the length of repetition and definition levels used with nested structures - this concept will be explained in one of next posts
- applied encoding
- optionally the statistics
- optional flag indicating if the compression was used - if missed, it's considered that the compression was used
We can also write a page header for the V1 of the format but it's much poorer since it contains only: number of values, used encoding, used encodings for repetition and definition levels, optional statistics. - repetition levels
- definition levels
- the data
In brief we could summarize Parquet (simplified) file format as an image:
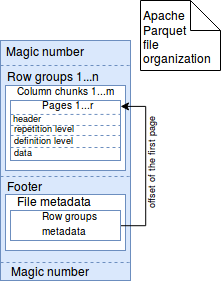
Parquet file internals by example
Below tests show some storage details explained in previous sections:
private static final String TEST_FILE = "/tmp/file_organization";
private static final Path TEST_FILE_PATH = new Path(TEST_FILE);
private static final Schema AVRO_SCHEMA = new Schema.Parser().parse("{\"type\":\"record\", \"name\":\"WorkingCitizen\"," +
"\"namespace\":\"com.waitingforcode.model\", \"fields\":[" +
"{\"name\":\"professionalSkills\",\"type\":{\"type\":\"array\",\"items\":\"string\"}}," +
"{\"name\":\"professionsPerYear\",\"type\":{\"type\":\"map\",\"values\":\"string\"}}," +
"{\"name\":\"civility\",\"type\":{\"type\":\"enum\",\"name\":\"Civilities\"," +
"\"symbols\":[\"MR\",\"MS\",\"MISS\",\"MRS\"]}}," +
"{\"name\":\"firstName\",\"type\":\"string\"}," +
"{\"name\":\"lastName\",\"type\":\"string\"}," +
"{\"name\":\"creditRating\",\"type\":\"double\"}," +
"{\"name\":\"isParent\",\"type\":\"boolean\"}]" +
"}");
@BeforeClass
public static void createContext() throws IOException {
new File(TEST_FILE).delete();
WorkingCitizen workingCitizen1 = getSampleWorkingCitizen(Civilities.MISS);
WorkingCitizen workingCitizen2 = getSampleWorkingCitizen(Civilities.MR);
ParquetWriter<WorkingCitizen> writer = AvroParquetWriter.<WorkingCitizen>builder(TEST_FILE_PATH)
.enableDictionaryEncoding()
.withSchema(AVRO_SCHEMA)
.withDataModel(ReflectData.get())
.withWriterVersion(ParquetProperties.WriterVersion.PARQUET_2_0)
.build();
writer.write(workingCitizen1);
writer.write(workingCitizen2);
writer.close();
}
@AfterClass
public static void deleteFile() {
new File(TEST_FILE).delete();
}
@Test
public void should_get_correct_row_group_information() throws IOException {
ParquetFileReader fileReader = ParquetFileReader.open(new Configuration(), TEST_FILE_PATH);
List<BlockMetaData> rowGroups = fileReader.getRowGroups();
assertThat(rowGroups).hasSize(1);
BlockMetaData rowGroup = rowGroups.get(0);
// We test only against several fields
ColumnChunkMetaData civility = getMetadataForColumn(rowGroup, "civility");
// It varies, sometimes it's 352, 356 or 353 - so do not assert on it
// Only show that the property exists
long offset = civility.getFirstDataPageOffset();
assertThat(civility.getFirstDataPageOffset()).isEqualTo(offset);
assertThat(civility.getStartingPos()).isEqualTo(offset);
assertThat(civility.getCodec()).isEqualTo(CompressionCodecName.UNCOMPRESSED);
assertThat(civility.getEncodings()).contains(Encoding.DELTA_BYTE_ARRAY);
assertThat(civility.getValueCount()).isEqualTo(2);
assertThat(civility.getTotalSize()).isEqualTo(60L);
assertThat(civility.getType()).isEqualTo(PrimitiveType.PrimitiveTypeName.BINARY);
// CHeck credit rating to see stats
ColumnChunkMetaData creditRating = getMetadataForColumn(rowGroup, "creditRating");
assertThat(creditRating.getStatistics()).isNotNull();
// Both have random values, so no to assert on exact values
assertThat(creditRating.getStatistics().genericGetMax()).isNotNull();
assertThat(creditRating.getStatistics().genericGetMin()).isNotNull();
assertThat(creditRating.getStatistics().hasNonNullValue()).isTrue();
assertThat(creditRating.getStatistics().getNumNulls()).isEqualTo(0);
}
private ColumnChunkMetaData getMetadataForColumn(BlockMetaData rowGroup, String columnName) {
return rowGroup.getColumns().stream()
.filter(columnChunkMetaData -> columnChunkMetaData.getPath().toDotString().contains(columnName))
.findFirst().get();
}
@Test
public void should_read_footer_of_correctly_written_file() throws IOException, URISyntaxException {
ParquetFileReader fileReader = ParquetFileReader.open(new Configuration(), TEST_FILE_PATH);
ParquetMetadata footer = fileReader.getFooter();
org.apache.parquet.hadoop.metadata.FileMetaData footerMetadata = footer.getFileMetaData();
assertThat(footerMetadata.getKeyValueMetaData()).containsKeys("parquet.avro.schema", "writer.model.name");
assertThat(footerMetadata.getCreatedBy())
.isEqualTo("parquet-mr version 1.9.0 (build 38262e2c80015d0935dad20f8e18f2d6f9fbd03c)");
StringBuilder schemaStringifier = new StringBuilder();
footerMetadata.getSchema().writeToStringBuilder(schemaStringifier, "");
assertThat(schemaStringifier.toString().replaceAll("\n", "").replaceAll(" ", "")).isEqualTo(
"message com.waitingforcode.model.WorkingCitizen {" +
"required group professionalSkills (LIST) {"+
"repeated binary array (UTF8);"+
"}"+
"required group professionsPerYear (MAP) {"+
"repeated group map (MAP_KEY_VALUE) {"+
"required binary key (UTF8);"+
"required binary value (UTF8);"+
"}"+
"}"+
"required binary civility (ENUM);"+
"required binary firstName (UTF8);"+
"required binary lastName (UTF8);"+
"required double creditRating;"+
"required boolean isParent;"+
"}");
}
The post explained data organization in the Parquet files. The first section focused on file metadata contained in the footer. As we could see, this part groups all information describing columns, such as offsets, encodings or used compression. The next part detailed better how the data is stored in pages that are included in column chunks that in their turn are included in row pages. The last section shown some tests proving what is stored in Parquet footer.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Next post about #ApacheParquet internals - focus on data storage https://t.co/BwA9ebiWJX
— bardev (@waitingforcode) November 5, 2017