
Very often an appropriate storage is as important as the data processing pipeline. And among different possibilities we can still store the data in files. Thanks to different formats, such as column-oriented ones, some of actions in reading path can be optimized.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is the first one devoted to Apache Parquet format. As purely theoretical and introductory post, it won't contain any code snippet. In place of that, it'll try to give some global ideas about Parquet's ecosystem (1st section) and the storage format (2nd section) without going really deep.
What is Apache Parquet ?
Apache Parquet is a columnar storage format using some of concepts defined in "Dremel: Interactive Analysis of Web-Scale Datasets" article. This inspiration concerns especially nested structures that Parquet is able to store efficiently. Thanks to optimized data organization, Parquet fits pretty well for analytics queries.
Columnar storage
In the column-oriented storage the data from specific columns is stored together in one or logically separated chunks. The benefits of this type of storage are:
- I/O reduction - if our query is targeted to 1 or 2 columns, the storage engine doesn't need to scan over all rows, decompress them, ignore not important columns. Instead, it decompress columns chunk directly and applies the filter on it.
- better compression - each column can be compressed differently
- encoding optimization - if the data cardinality in the column is low we can optimize the storage with sepcific encoding. For instance if the column stores only values for 2 countries idenentified by "US" and "DE" ISO codes, they can be optimized through the integers mapping. It could lead to store 0 for "US" and 1 for "DE" instead of "US" and "DE" strings each time.
The Apache Parquet project is composed of 3 main modules those meaning is not always obvious at first glance:
- parquet-format - this project defines the storage format. We can find there the mapping for Parquet data types, schema properties or statistics. This module also contains all Thrift definitions required to create readers and writes for Parquet files.
- parquet-mr - this module stores Java implementations for Parquet format. The name can seem misleading because it makes think about Map/Reduce integration. And this supposition is correct since the first releases of Parquet (e.g.Git history for the branch 1.1.0) shows the implementations almost exclusively reserved to Hadoop Map/Reduce world (Pig, Hive). Later, some not-Hadoop related data models were added, such as Arrow or Protobuf.
To resume, to simply define this model, we could tell that it has 2 purposes. The first one concerns everything required to convert files from other serialization formats (such as Avro, Protobuf) to Parquet format. The second feature is the integration with 3rd part engines, such as Hive or Pig. - parquet-compatibility - generally this module defines some tests about Parquet. It contains integration tests used to check compatibility between Java and C implementation, backward compatibility tests and performance tests.
Storage in Apache Parquet
Before introducing some storage details, let's clarify that Parquet files are immutable. So in order to change already created file, we need then open it, save in other place and remove at the end. This limitation is caused by the storage internals that contributes to Parquet efficiency.
The files written by Parquet are stored in a special format composed of the layers defined in the image below:
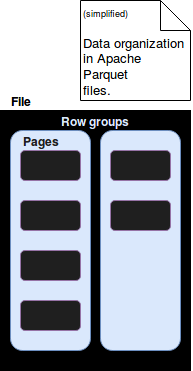
As you can see, a Parquet file is composed of row groups. Each row group stores subset of data in pages that grouped together compose a column chunk.
Parquet file contains also some metadata:
- the file metadata defines the schema and app specific metadata
- the columns chunks metadata contains the information about number of defined values, their size, the statistics (number of null values, min/max values)
The metadata is very helpful to optimize storage (efficient compression) and querying (e.g. filtering that can be optimized with min/max values).
Apache Parquet is a storage format well suited for queries not involving all columns. As shown in the first benchmarks at Twitter, the scanning time was up to 5 times smaller than in the case of Thrift storage. This efficiency is achieved not only thanks to column-oriented storage but also thanks to other optimization techniques are statistics or column-level compression discussed briefly in the 2nd part of this post. But all of that will be explained better in further posts.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Introduction to Apache Parquet here:
- Efficient Data Storage for Analytics with Apache Parquet 2.0 Apache Parquet documentation Parquet compatibility Parquet format Parquet MR
Related blog posts:
#ApacheParquet will be the topic for next weeks posts: short introduction https://t.co/kSUbkaj8Ap before the real exploration
— bardev (@waitingforcode) October 22, 2017