
I remember my first time with partitionBy method. I was reading data from an Apache Kafka topic and writing it into hourly-based partitioned directories. To my surprise, Apache Spark was generating always 1 file and my first thought... oh, it's shuffling the data. But I was wrong and in this post will explain why.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
For the story, the reason why I saw only 1 file written every time was that...my Apache Kafka topic had only 1 partition! After I looked at the code to see what happens when we use partitionBy method. You can find some words of explanation in the next 3 sections.
Before partitioning happens
Before explaining the physical partitioning execution, let's find out how it's triggered:
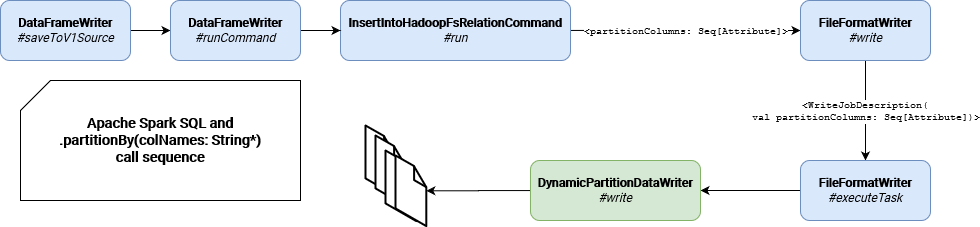
I put there on green the class responsible for the physical writing to the partitions. As you can see, before reaching this class, Apache Spark mostly passes the information about partitions from one place to another, transforming it in the last step into an instance of WriteJobDescription.
Partition information is almost used more like a "specification" for the write. "Almost" is quite important because at one point they're involved in the dataset schema construction. You can see it in FileFormatWriter's write method:
val dataColumns = outputSpec.outputColumns.filterNot(partitionSet.contains) val dataSchema = dataColumns.toStructType
What does it mean? Simply that the final dataset will not contain the partition columns. I wrote the following test to confirm that:
"partitionBy" should "not write partition columns in the dataset" in {
val outputDir = "/tmp/partitionby_test"
val rawNumbers = Seq(
(1, "a"), (2, "aa"), (1, "b"), (3, "c"), (1, "c"), (4, "c"), (1, "a"),
(5, "de"), (6, "e"), (1, "a")
)
rawNumbers.toDF("id", "word")
.write
.partitionBy("word")
.mode(SaveMode.Overwrite).json(outputDir)
val matchingFiles = FileUtils.listFiles(new File(outputDir), Array("json"), true)
import scala.collection.JavaConverters._
val writtenContent = matchingFiles.asScala.map(file => {
FileUtils.readFileToString(file)
})
writtenContent.mkString("\n") should not include "word"
}
On the other hand, if you read it back with Apache Spark, you will get the partition data in your dataset:
// The extension for the above test
val savedDataset = sparkSession.read.json(outputDir).select("word").as[String]
.collect()
savedDataset should contain allElementsOf(
rawNumbers.map(idWithWord => idWithWord._2)
)
When I executed this code for the first time, I had an error about not matching but I will cover this in the last section. Let's move now to the physical data writing.
DynamicPartitionDataWriter
How does the partitioned data writing work? First, it starts by extracting any variable part of the written path, so the partition but also the bucket information. Internally, DynamicPartitionDataWriter stores the information about currently used physical writer and partitions it was in charge of:
protected var currentWriter: OutputWriter = _ private var currentPartionValues: Option[UnsafeRow] = None
With every written row, the DynamicPartitionDataWriter checks whether the partitions are the same as the currentPartitionValues. If that's the case and the currentWriter has still some room for new rows, Apache Spark simply writes the row. Otherwise, it creates a new instance of currentWriter which for JSON files will be a JsonOutputWriter, directly from JsonFileFormat newInstance factory method.
Wait, you've just said a new instance? Indeed, there is no caching implemented and every time the read row has a different partition than the previous one, we create a new writer and close the previous one. Closing the previous one means that we flush the accumulated rows to file. So, it means that for a sequence of partitioning columns like (a, a, b, c, a, c, c), Apache Spark will write 5 files instead of 3? I was thinking so but after launching my test on a single partition, I saw that it was a wrong assumption:
I was amazed by that. How is it even possible? In fact, the answer is hidden in the code of FileFormatWriter, and more exactly in these lines:
// We should first sort by partition columns, then bucket id, and finally sorting columns.
val requiredOrdering = partitionColumns ++ bucketIdExpression ++ sortColumns
// the sort order doesn't matter
val actualOrdering = plan.outputOrdering.map(_.child)
val orderingMatched = if (requiredOrdering.length > actualOrdering.length) {
false
} else {
requiredOrdering.zip(actualOrdering).forall {
case (requiredOrder, childOutputOrder) =>
requiredOrder.semanticEquals(childOutputOrder)
}
}
As you can see, Apache Spark compares the query's ORDER BY clause with the clause required by the combination of partition and bucket columns. Later, this information is used to either directly execute the write or, if the data isn't sorted as expected, preceding it with a sort stage:
val rdd = if (orderingMatched) {
plan.execute()
} else {
// SPARK-21165: the `requiredOrdering` is based on the attributes from analyzed plan, and
// the physical plan may have different attribute ids due to optimizer removing some
// aliases. Here we bind the expression ahead to avoid potential attribute ids mismatch.
val orderingExpr = requiredOrdering
.map(SortOrder(_, Ascending))
.map(BindReferences.bindReference(_, outputSpec.outputColumns))
SortExec(
orderingExpr,
global = false,
child = plan).execute()
}
An important thing to notice, the sort is local, so within a partition. That's one of the reasons we don't need to shuffle for a partitionBy write.
Delete problems
During my tests, by mistake, I changed the schema of my input DataFrame. When I launched the pipeline, I logically saw an AnalysisException saying that "Partition column `id` not found in schema struct
"partitionBy" should "fail when the partitions don't match the dataset schema" in {
val outputDir = "/tmp/partitionby_test_not_matching_schema"
val rawNumbers = Seq(
(1, "a"), (2, "aa"), (1, "b"), (3, "c"), (1, "c"), (4, "c"), (1, "a"),
(5, "de"), (6, "e"), (1, "a"), (1, "a"), (1, "a"), (1, "a"), (2, "aa"),
(2, "aa"), (2, "de")
).toDF("id", "word")
val exception = the [AnalysisException] thrownBy {
rawNumbers.write
.partitionBy("number_id")
.mode(SaveMode.Overwrite).json(outputDir)
}
exception.getMessage() should startWith("Partition column `number_id` not found in " +
"schema struct<id:int,word:string>;")
}
Why does it happen? The answer is hidden in DataSource#planForWritingFileFormat(format: FileFormat, mode: SaveMode, data: LogicalPlan) method that generates the instance of InsertIntoHadoopFsRelationCommand, responsible for writing the data physically. This method validates the partitions with the help of PartitioningUtils validatePartitionColumn method.
validatePartitionColumn is responsible for ensuring that the partitions you specified are valid choices, so they have to exist in the input schema and must be atomic types like (string, integer, double, ...). My mistake was that I changed the input schema and not the partitioned column. Let's check now if, despite the existence of already partitioned data, we can write data partitioned by a different column:
"partitionBy" should "allow to use different partition columns in the same physical location" in {
val outputDir = "/tmp/partitionby_test_different_columns"
val rawNumbers = Seq(
(1, "a"), (2, "aa"), (1, "b"), (3, "c"), (1, "c"), (4, "c"), (1, "a"),
(5, "de"), (6, "e"), (1, "a"), (1, "a"), (1, "a"), (1, "a"), (2, "aa"),
(2, "aa"), (2, "de")
).toDF("id", "word")
rawNumbers.write
.partitionBy("id")
.mode(SaveMode.Overwrite).json(outputDir)
rawNumbers.write
.partitionBy("word")
.mode(SaveMode.Append).json(outputDir)
val matchingFiles = FileUtils.listFiles(new File(outputDir), Array("json"), true)
import scala.collection.JavaConverters._
val generatedFiles = matchingFiles.asScala.map(file => {
file.getAbsolutePath
})
val expectedPartitions = Seq("id=1", "id=2", "id=3", "id=4", "id=5", "id=6",
"word=a", "word=aa", "word=b", "word=c", "word=de", "word=e")
expectedPartitions.foreach(partition => generatedFiles.mkString("\n") should include(partition))
}
As you can see, the test passed which means that we can write different partitions into a single physical place. I'm not sure whether it's a good idea to put them in a single place but technically it's possible.
To return to my initial concern, shuffle or not shuffle, how do we know that the shuffle doesn't occur? Simply speaking, partitionBy is the operation of the writer which itself is more like a simple physical executor of the data processing logic on top of Spark partitions, so it doesn't involve any data distribution step. Shuffle can of course still happen, but more because of the data loading and processing logic like calling repartitionByRange method, and not partitionBy. Can it be dangerous? Indeed, you can have files with very few data inside if the task writing the file contains 99% of the rows for one partition and only 1% for the other one.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Spark SQL partitionBy - shuffle or not to shuffle? here:
Related blog posts:
In March I wrote about partition-based sort in #ApacheSpark #SparkSQL. This feature is used in partitionBy method I described in my today's post https://t.co/KKR4r3su1Q
— Bartosz Konieczny (@waitingforcode) May 3, 2020