
Even though Apache Spark SQL provides an API for structured data, the framework sometimes behaves unexpectedly. It's the case of an insertInto operation that can even lead to some data quality issues. Why? Let's try to understand in this short article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Let's suppose you have a dataset and a table like in the next snippet:
sparkSession.sql(
"""
|CREATE TABLE numbers_with_letters (
| lower_case STRING,
| upper_case STRING,
| nr INT
|) USING delta
|""".stripMargin)
Seq(("C", "c", 3), ("D", "d", 4)).toDF("upper_case", "lower_case", "nr").write.format("delta")
.insertInto("numbers_with_letters")
After executing this code, you might be expecting to have something like that:
+----------+----------+---+ |lower_case|upper_case|nr | +----------+----------+---+ |c |C |3 | |d |D |4 | +----------+----------+---+
Unlucky you, the table will rather look that way:
+----------+----------+---+ |lower_case|upper_case|nr | +----------+----------+---+ |C |c |3 | |D |d |4 | +----------+----------+---+
As you can see, the upper_case letters from the DataFrame are written in the lower_case column. And it's by design! In fact, when you read the documentation or code comments, you will see the following warning about the insertInto:
/** * Inserts the content of the `DataFrame` to the specified table. It requires that * the schema of the `DataFrame` is the same as the schema of the table. * * @note Unlike `saveAsTable`, `insertInto` ignores the column names and just uses position-based * resolution.
The issue becomes even more apparent when you try to insert rows with mismatching types:
Seq((5, "e", "E"), (6, "f", "F")).toDF("nr", "lower_case", "upper_case").write.format("delta")
.insertInto("numbers_with_letters")
Applied to our example, the code above should lead to the following exception:
Exception in thread "main" org.apache.spark.sql.AnalysisException: [INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST] Cannot write incompatible data for the table `spark_catalog`.`default`.`numbers_with_letters`: Cannot safely cast `nr` "STRING" to "INT".
To understand why it happens, we need to deep delve into the implementation.
The insertInto internals - Delta Lake
To start, do not blame yourself. You don't explicitly asked Apache Spark to insert rows by position, after all your DataFrame is typed and you are expecting Apache Spark to respect the DataFrame's schema. Unfortunately, it doesn't happen as Apache Spark aliases your input columns. As a result, the Seq(("C", "c", 3), ("D", "d", 4)).toDF("upper_case", "lower_case", "nr") from the very first snippet translates into a logical plan like this:
AppendData RelationV2[lower_case#67, upper_case#68, nr#69] spark_catalog.default.numbers_with_letters spark_catalog.default.numbers_with_letters, false +- Project [_1#3 AS upper_case#10, _2#4 AS lower_case#11, _3#5 AS nr#12] +- LocalRelation [_1#3, _2#4, _3#5]
However, this plan is not final. As you know, Apache Spark applies logical rules to optimize the logical plan before the execution. One of the logical rules involved in Delta Lake is DeltaAnalysis. Look carefully at the Scaladoc:
/**
* Analysis rules for Delta. Currently, these rules enable schema enforcement / evolution with
* INSERT INTO.
*/
class DeltaAnalysis(session: SparkSession)
extends Rule[LogicalPlan] with AnalysisHelper with DeltaLogging {
Yes! That's where the engine prepares your DataFrame for insertion, either by enforcing the name-based, or position-based resolution. As the insertInto involves the position-based resolution, and because the name-based one will be the topic of another blog post, let's focus on the position-based inserts. When you call an insertInto method, the rule falls into this case:
override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsDown {
// INSERT INTO by ordinal and df.insertInto()
case a @ AppendDelta(r, d) if !a.isByName &&
needsSchemaAdjustmentByOrdinal(d, a.query, r.schema) =>
val projection = resolveQueryColumnsByOrdinal(a.query, r.output, d)
if (projection != a.query) {
a.copy(query = projection)
} else {
a
}
As you can see from the snippet, if your not optimized logical plan contains columns in wrong order, the rule will reorder them to match the order of the columns at the table level. Consequently, you'll get another projection in the plan, this time to alias input columns with table column names. In our example, it translates into:
AppendData RelationV2[lower_case#67, upper_case#68, nr#69] spark_catalog.default.numbers_with_letters spark_catalog.default.numbers_with_letters, false +- Project [upper_case#10 AS lower_case#70, lower_case#11 AS upper_case#71, nr#12 AS nr#72] +- Project [_1#3 AS upper_case#10, _2#4 AS lower_case#11, _3#5 AS nr#12] +- LocalRelation [_1#3, _2#4, _3#5]
Overall, the execution flow consists of these classes and methods:
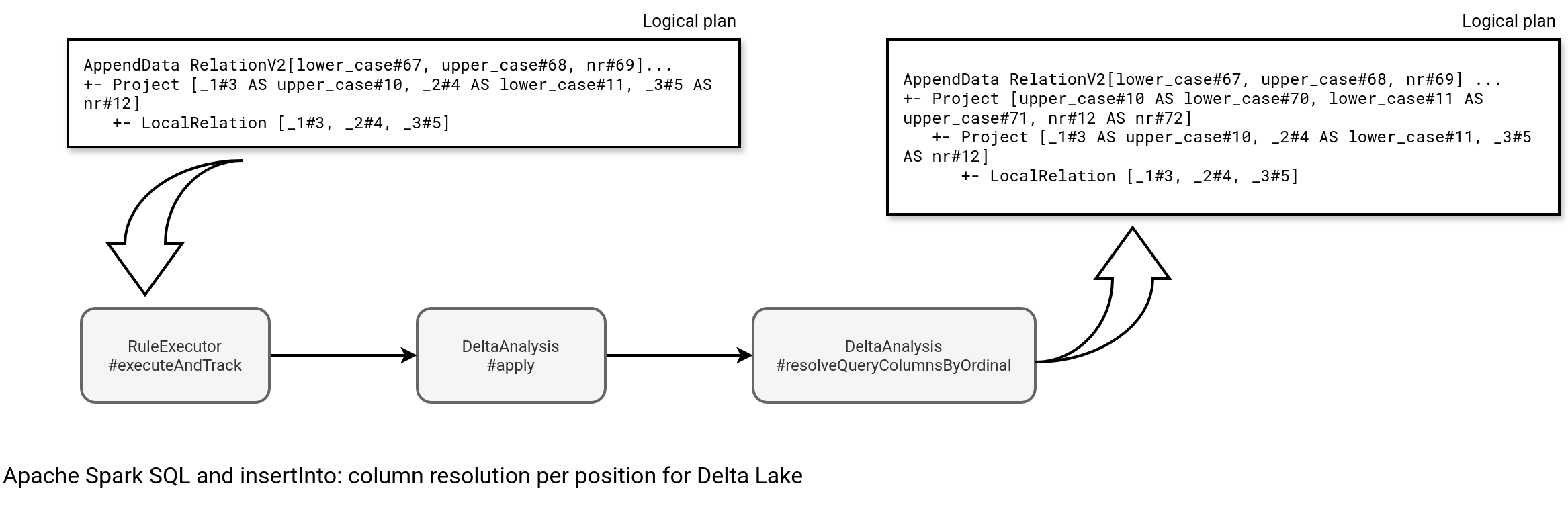
Now you certainly understand why Apache Spark inserted lower_case and upper_case rows to the wrong columns.
The insertInto by column
If you need, and it's ok with the scale of your dataset, you can also use a more classical insert-by-name which translates into a SQL operation like:
INSERT INTO numbers_with_letters (nr, upper_case) VALUES (5, 'E', 'e')
The following query translates into an AppendData logical node with a byName flag set to true. What does it mean? Apache Spark captures the INSERT INTO statement and transforms it into an AppendData node in ResolveInsertInto and adds a Project node aliasing columns from the local relation to the names expected by the table's schema:
case i @ InsertIntoStatement(r: DataSourceV2Relation, _, _, _, _, _, _)
// ..
val projectByName = if (i.userSpecifiedCols.nonEmpty) {
Some(createProjectForByNameQuery(r.table.name, i))
} else {
None
}
val isByName = projectByName.nonEmpty || i.byName
// ...
if (!i.overwrite) {
if (isByName) {
AppendData.byName(r, query)
} else {
AppendData.byPosition(r, query)
}
}
Consequently, the logical plan changes from:
'InsertIntoStatement RelationV2[lower_case#48, upper_case#49, nr#50] spark_catalog.default.numbers_with_letters spark_catalog.default.numbers_with_letters, [nr, upper_case, lower_case], false, false, false +- LocalRelation [col1#51, col2#52, col3#53]
...to:
AppendData RelationV2[lower_case#48, upper_case#49, nr#50] spark_catalog.default.numbers_with_letters spark_catalog.default.numbers_with_letters, true +- Project [col1#51 AS nr#54, col2#52 AS upper_case#55, col3#53 AS lower_case#56] +- LocalRelation [col1#51, col2#52, col3#53]
This is normal
Position-based resolution is normal for INSERT INTO statements in SQL. If you omit the columns in the operation, the database will consider the position-based insert with the columns declaration order in the table's schema. Below is an extract from PostgreSQL's documentation for the INSERT INTO operation:

Although a possibility to use the name-based resolution exists, it seems to be missing in the programmatic API which would be convenient to insert big DataFrames. For the record, the same problem exists for the UNION operation which also resolves the columns per position. However, Apache Spark solves this often error-prone approach with a dedicated method, unionByName, where DataFrames are combined directly by the column names instead of their positions. Maybe something similar could exist in Apache Spark SQL in the future? Anyway, in the meantime you need to deal with the problem via a different operation that I'll detail in the next blog post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩