
Is there an easier way to address the insertInto position-based data writing in Apache Spark SQL? Totally, if you use a column-based method such as saveAsTable with append mode.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
From my previous blog post about the insertInto function in Apache Spark SQL you know the risk. Semantically the insertInto sounds pretty natural to append new rows to a table. However, it's a position-based operation and not the column name-based. Consequently, if you mistakenly reverse two columns sharing the same type, you can silently add wrong data. Thankfully, Apache Spark SQL has a more resilient way, albeit slightly verbose than the insertInto, to add new rows to a table. This method is the saveAsTable. As you can read in the Scaladoc, it addresses the position-based resolution of the insertInto:
* In the case the table already exists, behavior of this function depends on the * save mode, specified by the `mode` function (default to throwing an exception). * When `mode` is `Overwrite`, the schema of the `DataFrame` does not need to be * the same as that of the existing table. * * When `mode` is `Append`, if there is an existing table, we will use the format and options of * the existing table. The column order in the schema of the `DataFrame` doesn't need to be same * as that of the existing table. Unlike `insertInto`, `saveAsTable` will use the column names to * find the correct column positions. For example:
📝 Partitioned tables
As I explained in Overwriting partitioned tables in Apache Spark SQL, the saveAsTable doesn't work well with partitioned tables. That's why in the blog post you're currently reading, we're going to consider the not partitioned tables only.
Example
Let's see this saveAsTable magic in action. In the example, we're creating the following table with 3 columns:
CREATE TABLE numbers_with_letters ( lower_case STRING, upper_case STRING, nr INT) USING DELTA
The table has a simple structure composed of two string fields and one integer column. Let's see now what happens when we create a DataFrame with the columns declared in a different order than in the table:
Seq((3, "C", "c"), (4, "D", "d")).toDF("nr", "upper_case", "lower_case").write
.mode(SaveMode.Append).format("delta")
.saveAsTable("numbers_with_letters")
As you can notice, the nr column in the DataFrame is declared first while in the table, it's set in the last position. However, once you query the table, you'll see the columns returned in the correct order:
+---+----------+----------+ |nr |upper_case|lower_case| +---+----------+----------+ |3 |C |c | |4 |D |d | +---+----------+----------+
This is something that wouldn't happen if you used the insertInto statement, which remember, is position-based.
Internals
Now with all this context set up, it's time to understand why and how the saveAsTable performs this column-based resolution for Apache Parquet-based data sources, such as Delta Lake and Hive. Long story short, many places in the code base rely on position-based resolution but it doesn't necessarily mean risk of reversing fields. Let's begin with the ParquetWriteSupport which is used to write columns from Apache Spark's InternalRow into Apache Parquet files:
// ParquetWriteSupport
private def writeFields(
row: InternalRow, schema: StructType, fieldWriters: Array[ValueWriter]): Unit = {
var i = 0
while (i < row.numFields) {
if (!row.isNullAt(i)) {
consumeField(schema(i).name, i) {
fieldWriters(i).apply(row, i)
}
}
i += 1
}
}

As you can notice, the writeFields method iterates the input row and finds the corresponding field definition in the input schema by position. Technically, two different fields of the same data type, may be written inversely. But that's just a theory behind this write function. In practice, all boils down to who passes the schema: StructType.
For Delta Lake writer, the schema comes from the data itself. Does it mean, the Parquet writer can wrongly write columns if they were declared incorrectly in the select statement? Not really. In fact, Delta Lake writer performs an implicit projection that reorders columns if needed. The magic happens in ColumnWithDefaultExprUtils#addDefaultExprsOrReturnConstraints where the function uses table's schema declaration to add generated columns. As the schema comes from the table, if there is something wrong with the declaration order in the written DataFrame, it gets fixed:
def addDefaultExprsOrReturnConstraints(
deltaLog: DeltaLog, protocol: Protocol, queryExecution: QueryExecution,
schema: StructType, data: DataFrame, nullAsDefault: Boolean): (DataFrame, Seq[Constraint], Set[String]) = {
// ...
val topLevelOutputNames = CaseInsensitiveMap(data.schema.map(f => f.name -> f).toMap)
lazy val metadataOutputNames = CaseInsensitiveMap(schema.map(f => f.name -> f).toMap)
var selectExprs = schema.flatMap { f =>
GeneratedColumn.getGenerationExpression(f) match {
// ...
case _ =>
if (topLevelOutputNames.contains(f.name) ||
!data.sparkSession.conf.get(DeltaSQLConf.GENERATED_COLUMN_ALLOW_NULLABLE)) {
Some(SchemaUtils.fieldToColumn(f))
} else {
getDefaultValueExprOrNullLit(f, nullAsDefault).map(new Column(_))
}
// ...
val newData = queryExecution match {
case incrementalExecution: IncrementalExecution =>
selectFromStreamingDataFrame(incrementalExecution, data, selectExprs: _*)
case _ => data.select(selectExprs: _*)
}
recordDeltaEvent(deltaLog, "delta.generatedColumns.write")
(newData, constraints.toSeq, track.toSet)
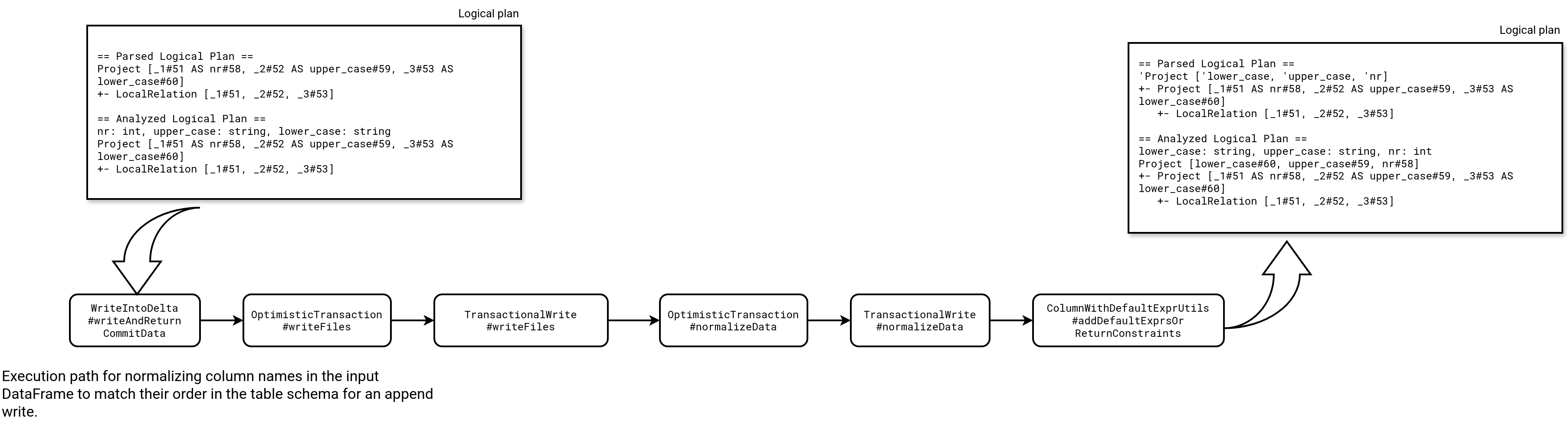
As you can see in the code snippet and the execution path presented above, at the end of the normalization the execution plan gets a new projection with the DataFrame fields matching the columns order in the table.
Do the other formats behave the same? The short answer is, no. For example, if we analyze the good and old Apache Hive tables, the normalization happens in an explicit way via a logical rule called PreprocessTableCreation that reorders column by name with an additional aliasing node as for Delta Lake:
// PreprocessTableCreation
// As we are inserting into an existing table, we should respect the existing schema and
// adjust the column order of the given dataframe according to it, or throw exception
// if the column names do not match.
val adjustedColumns = tableCols.map { col =>
query.resolve(Seq(col), resolver).getOrElse {
val inputColumns = query.schema.map(_.name).mkString(", ")
throw QueryCompilationErrors.cannotResolveColumnGivenInputColumnsError(col, inputColumns)
}
}
// ...
val newQuery = if (adjustedColumns != query.output) {
Project(adjustedColumns, query)
} else {
query
}
Long story short, if you use saveAsTable, Apache Spark gets you covered by performing implicit and explicit reordering on top of the written DataFrame. It's not the case of the insertInto operation that, albeit looking more intuitive than a combination of append mode and saveAsTable, requires columns in the expected order.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩