
Seven (!) years have passed since my blog post about Join types in Apache Spark SQL (2017). Coming from a software engineering background, I was so amazed that the world of joins doesn't stop on LEFT/RIGHT/FULL joins that I couldn't not blog about it ;) Time has passed but lucky me, each new project teaches me something.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
One of my recent projects was about migrating an ETL layer and SQL Server tables into Databricks and Delta Lake. Despite what I had been thinking, the SQL dialect used in the queries were pretty close to the ANSI SQL of Apache Spark SQL. "Pretty close" because I encountered two new concepts to me, recursive CTEs and CROSS APPLY. Since I have already blogged about the CTE topic, aka hierarchical queries in 2018, I left this topic aside to focus on this mysterious CROSS APPLY.
Lateral join 101
In fact, the CROSS APPLY is a SQL Server-specific term to describe something which is more commonly known as LATERAL JOIN. Lateral join is a kind of correlated subquery evaluated once for each row whose columns can be referenced by the outer query. This special subquery can return many rows with many columns vs. a single row with a single column for the classical correlated subquery.
A lateral join is often compared to a foreach loop from programming languages meaning something like:
for each row from outer query: evaluate the lateral join
Let's try to understand it better with an example from PostgreSQL. Our database has two tables, orders and order items presented in the picture below:
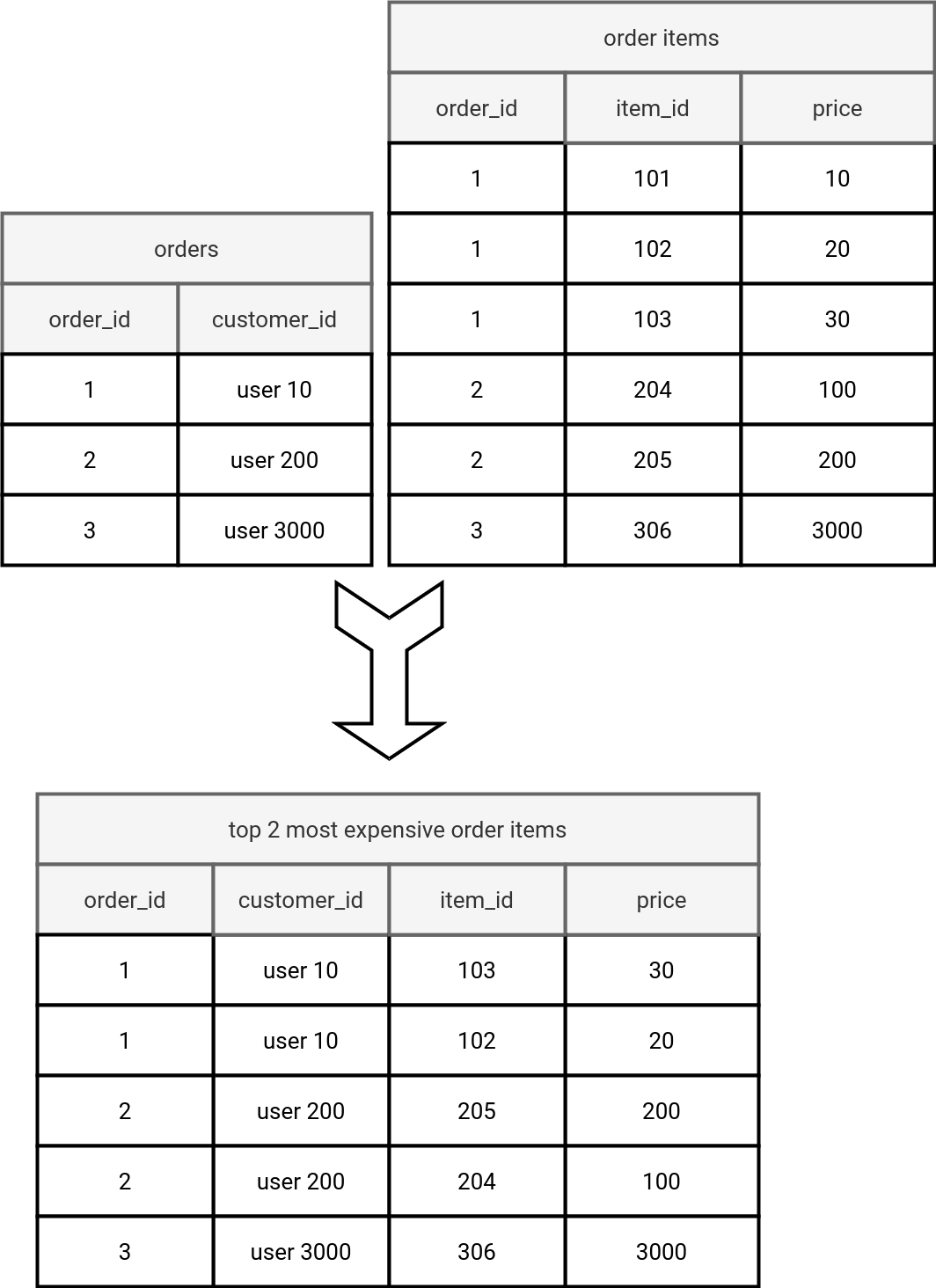
The goal of our query is to combine orders and order_items tables to get two most expensive items per order, plus the customer information. One approach to address this problem is to use the lateral join:
SELECT orders.order_id, orders.customer_id, items.item_id, items.price FROM wfc.orders orders, LATERAL ( SELECT item_id, price FROM wfc.order_items WHERE order_id = orders.order_id ORDER BY price DESC LIMIT 2 ) AS items
What does the query do? It selects order_id and customer_id from the orders table and explodes each selected row to at most 2 output rows containing two most expensive order items. Overall, the outcome will be:
order_id | customer_id | item_id | price
----------+-------------+---------+-------
1 | user 10 | 103 | 30
1 | user 10 | 102 | 20
2 | user 200 | 205 | 200
2 | user 200 | 204 | 100
3 | user 3000 | 306 | 3000
The lateral join could be understood as a correlated subquery. But as you already know from the short introduction of lateral joins, they can return multiple rows and columns while correlated subqueries can't. As a result, when you try to put the lateral join in the SELECT statement, PostgreSQL will return an error about multiple columns and multiple rows returned. Only when you keep a single output column and change the LIMIT 2 to LIMIT 1, thus you get only the most expensive item per order, the correlated subquery will work:
wfc=# SELECT
orders.order_id, orders.customer_id, (
SELECT item_id, price
FROM wfc.order_items
WHERE order_id = orders.order_id
ORDER BY price DESC
LIMIT 2
)
FROM
wfc.orders orders;
ERROR: subquery must return only one column
LINE 2: orders.order_id, orders.customer_id, (
^
wfc=# SELECT
orders.order_id, orders.customer_id, (
SELECT item_id
FROM wfc.order_items
WHERE order_id = orders.order_id
ORDER BY price DESC
LIMIT 2
)
FROM
wfc.orders orders;
ERROR: more than one row returned by a subquery used as an expression
wfc=# SELECT
orders.order_id, orders.customer_id, (
SELECT item_id
FROM wfc.order_items
WHERE order_id = orders.order_id
ORDER BY price DESC
LIMIT 1
)
FROM
wfc.orders orders;
order_id | customer_id | item_id
----------+-------------+---------
1 | user 10 | 103
2 | user 200 | 205
3 | user 3000 | 306
(3 rows)
That's only a glimpse of lateral joins. Hopefully, it's enough to start analyzing their implementation in Apache Spark SQL.
Lateral derived tables
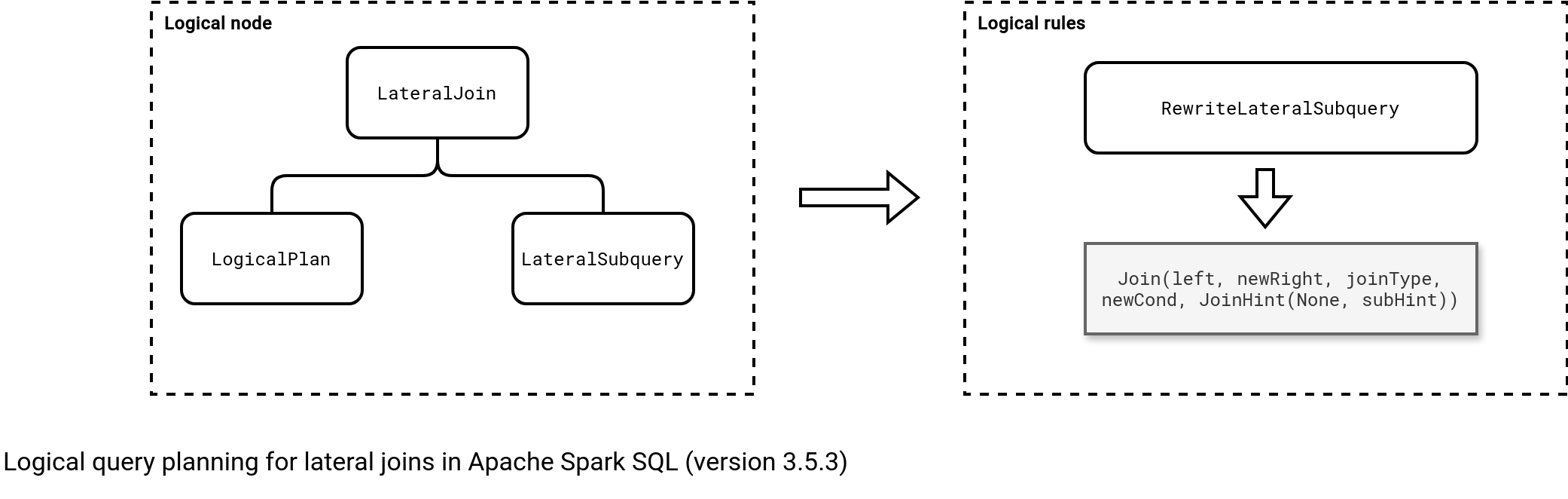
Apache Spark SQL implemented the lateral delivered tables in the 3.2.0 release thanks to Allison Wang's contribution. To understand the new components, let's analyze the following query:
SELECT * FROM order, LATERAL (SELECT COUNT(*) FROM orders_history AS oh WHERE order.user = oh.user GROUP BY oh.user)
When you check the logical plan, you'll notice a LateralJoin node composed of another LogicalPlan (aka outer query), and a subquery (LateralSubquery). During the logical planning optimization stage, Catalyst optimizer will transform lateral join into a...regular join by applying RewriteLateralSubquery rule. From now on, the lateral join becomes a regular join and Apache Spark executes it with one of the available strategies, such as sort-merge join. The next schema summarizes this workflow:
Lateral views
Besides joins, Apache Spark also supports lateral views. They're useful if you need to generate a common sequence of values to be combined with outer query. For example, the following example will join each row from the main_table table with [2, 4] array:
SELECT * FROM main_table LATERAL VIEW EXPLODE(ARRAY(2, 4)) lateral_table
More exactly speaking, the "EXPLODE(ARRAY([2, 4]))" is a generator. Unsurprisingly then, if you analyze the logic plan, you will find a Generate node:
== Parsed Logical Plan ==
'Project [*]
+- 'Generate 'EXPLODE('ARRAY(2, 4)), false, lateral_table
+- 'UnresolvedRelation [main_table], [], false
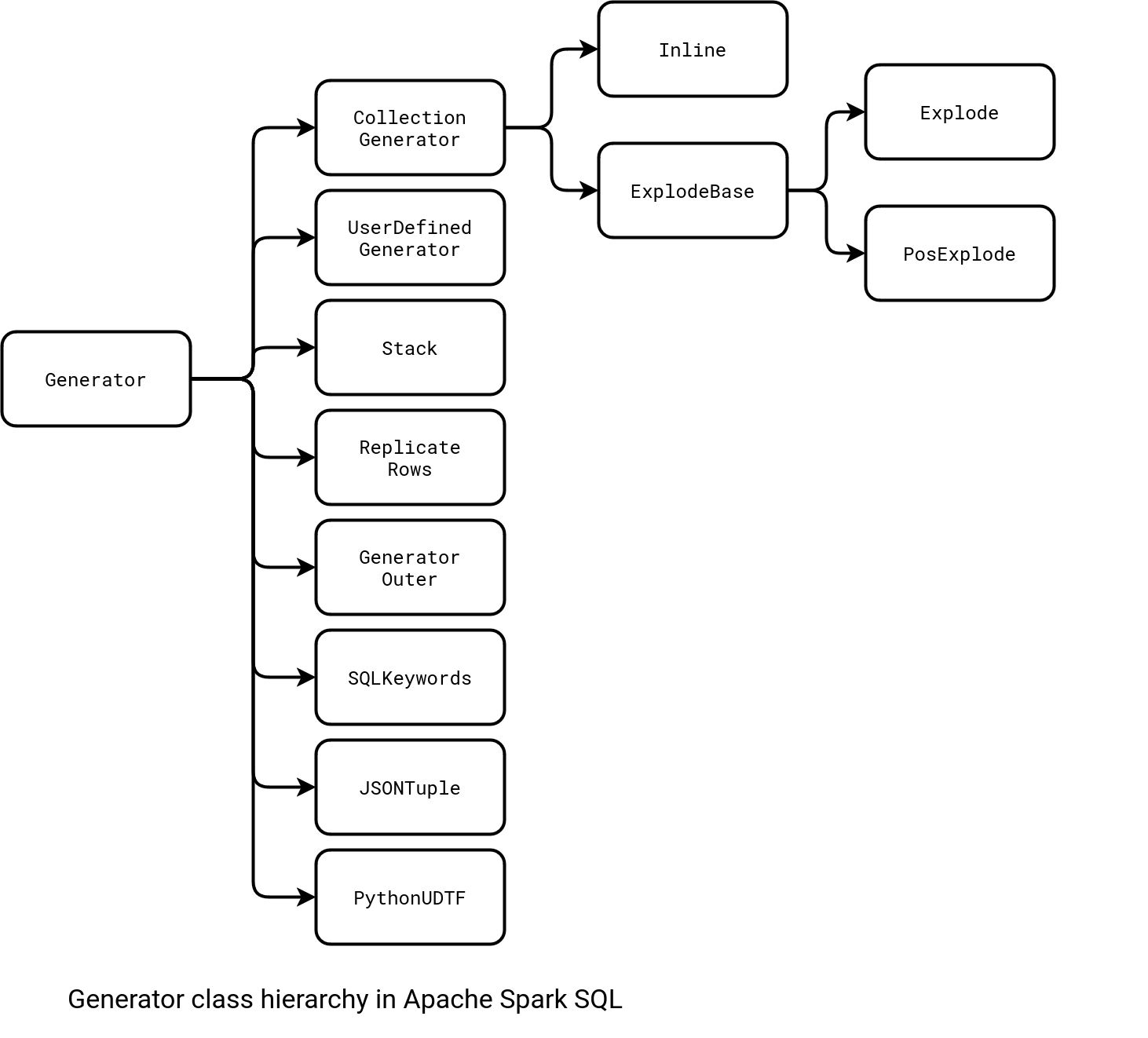
EXPLODE functions is probably the most popular generator but if you analyze the implementations of the Generator interface, you'll find many others. The next figure shows what else you could use in a query with LATERAL VIEW:
Data generator expressions implement code generation. Therefore, you won't find any generator-related node in the physical plan and instead, the generator part will be marked the asterisk ("*") sign for the whole stage code generation. Below you can find an example for our EXPLODE use case:
== Physical Plan == *(1) Generate explode([2,4]), [c1#20, c2#21], true, [col#22] +- Scan hive spark_catalog.default.main_table [c1#20, c2#21], HiveTableRelation [`spark_catalog`.`default`.`main_table`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [c1#20, c2#21], Partition Cols: []]
An exception to the inclusion of the generators to the generated code is the stack function. If you don't know how it works, I shared some details in stack operation in Apache Spark SQL blog post. The stack function doesn't support code generation if it generates more than 50 rows. Below is the condition from org.apache.spark.sql.catalyst.expressions.Stack responsible for this control:
case class Stack(children: Seq[Expression]) extends Generator {
private lazy val numRows = children.head.eval().asInstanceOf[Int]
override def supportCodegen: Boolean = numRows <= 50
I didn't find a special mention why 50 but looks like it has been considered as a sign of a large expression from the beginning.
Lucky me, while I was exploring lateral subqueries and lateral views, I found Apache Spark got yet another support for lateral expressions, this time in the version 3.4. But I'll blog about lateral alias references next time!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Lateral subquery, aka lateral join, and lateral views in Apache Spark SQL here:
- ANSI SQL: LATERAL derived table(T491) Implement code generation for Generate What is the difference between LATERAL JOIN and a subquery in PostgreSQL?