
It's the second blog post about laterals in Apache Spark SQL. Previously you discovered how to combine queries with lateral subquery and lateral views. Now it's time to see a more local feature, lateral column aliases.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
If you have been using Apache Spark SQL since at least the 3.3.0 release, you might have already faced the errors lateral column aliases try to solve. If not, let's take a refresher. The following code converts a JSON into a structure and creates a new column from the structure's two fields:
SELECT
FROM_JSON(letter_json, "lower STRING, upper STRING") AS letter,
CONCAT_WS(" -> ", letter.lower, letter.upper) AS concatenated
FROM letters
If you try to execute this code on top of Apache Spark 3.3.0 or below, you'll get the following error:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Column 'letter.lower' does not exist. Did you mean one of the following? [letters.letter_json]; line 4 pos 19;
'Project [from_json(StructField(lower,StringType,true), StructField(upper,StringType,true), letter_json#4, Some(Europe/Paris)) AS letter#6, 'CONCAT_WS( -> , 'letter.lower, 'letter.upper) AS concatenated#7]
+- SubqueryAlias letters
+- View (`letters`, [letter_json#4])
+- Project [value#1 AS letter_json#4]
+- LocalRelation [value#1]
The error says there is no such a column as "letter". You can mitigate this issue by defining a subquery:
SELECT CONCAT_WS(" -> ", letter.lower, letter.upper) AS concatenated FROM
(SELECT FROM_JSON(letter_json, "lower STRING, upper STRING") AS letter FROM letters) AS l
But that's before Apache Spark 3.4.0 that has added the support for lateral column aliases. Consequently, if you try to execute the erroneous query with this version, or above, you'll get the results, and in the logs, you will see a new ResolveLateralColumnAliasReference rule.
LateralColumnAliasReference - analysis
The rule, as well as the corresponding logical node (LateralColumnAliasReference) are the results of work made by Xinyi Yu as part of the SPARK-27561.
The feature transforms unresolved aliases into LateralColumnAliasReferences that are later transformed into a corresponding execution plan. If you don't want to use it, but btw why would you do so, you can disable the spark.sql.lateralColumnAlias.enableImplicitResolution property, turned on by default.
Most of the execution magic happens during the query analysis stage. At that moment Apache Spark analyzes the attributes defined in the query and whenever an attribute is not yet resolved, the engine calls ColumnResolutionHelper#resolveLateralColumnAlias function. The function gets all selected columns and tries to resolve them by recursively mapping unknown fields to the known ones with the help of a local cache between dependent objects. Both methods are present in the next code snippet:
val aliasMap = mutable.HashMap.empty[String, Either[Alias, Int]]
def resolve(e: Expression): Expression = { ///...
selectList.map {
case a: Alias =>
val result = resolve(a)
val lowerCasedName = a.name.toLowerCase(Locale.ROOT)
aliasMap.get(lowerCasedName) match {
case Some(scala.util.Left(_)) =>
aliasMap(lowerCasedName) = scala.util.Right(2)
case Some(scala.util.Right(count)) =>
aliasMap(lowerCasedName) = scala.util.Right(count + 1)
case None =>
aliasMap += lowerCasedName -> scala.util.Left(a)
}
result
case other => resolve(other)
}
The picture below summarizes this analysis step producing LateralColumnAliasReferences:
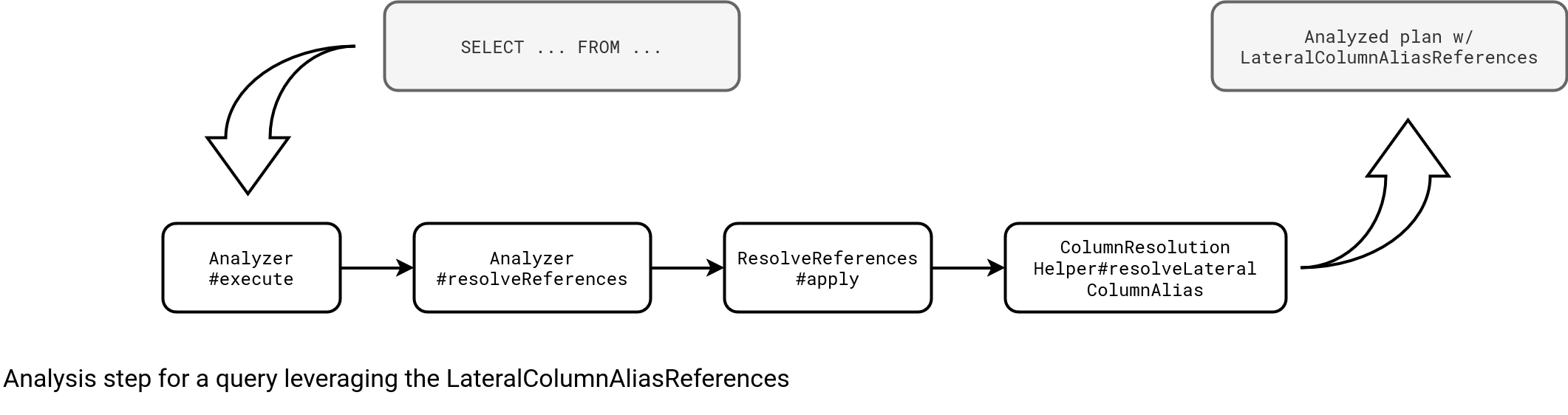
However, the analysis doesn't stop here. There is an additional rule (ResolveLateralColumnAliasReference) that converts the LateralColumnAliasReference nodes to columns. If we take our initial example, with the help of this rule the plan gets transformed that way:

As you can see, the next analysis rule, the ResolveLateralColumnAliasReference splits the initial query into two parts. The lower, aka outer, Project node stores all columns expected by the upper, aka inner, attributes.
From now on, the query can follow the usual path of the known, thus resolved, columns.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Lateral column aliases in Apache Spark SQL here:
- Introducing the Support of Lateral Column Alias Support "lateral column alias references" to allow column aliases to be used within SELECT clauses