
This year, I'll be exploring various software engineering principles and their application to data engineering. Clean Architecture is a prime example, and it serves as the focus of this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In a nutshell, clean architecture promises a clear separation between layers, from business rules implemented as domain objects, to the communication with the external world via adapters. This separation favors business logic independence from the technical world represented by databases or external APIs. One of the most important rules is the isolation where the inner circles should never know what their outer cycles are. The code organized that way is more flexible and easier to test locally since the most external cycle is not anymore required for the code execution. The following picture summaries the clean architecture principle:
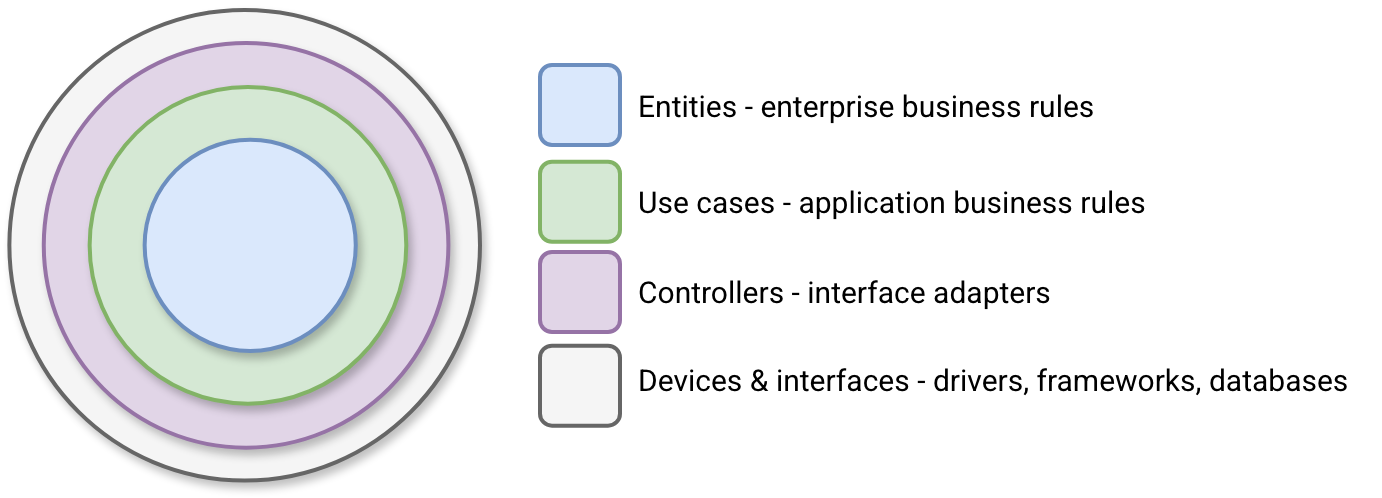
If you have done some web development at least once in your life, you can clearly see where it's going. The entities are domain objects, so everything that represents your business. If you are an e-commerce store, you will find here classes like Order, Buyer, or yet Seller.
When it comes to the Use cases, this circle will contain code that apply the business rules implemented in the domain entities directly. Think about it as methods that operate on domains and eventually orchestrate abstract definitions from the Controllers layer. In our e-commerce example we would implement here a method changing order status to ready and persisting this change...remark, I'm not typing where this state should be persisted as the Use case layer shouldn't know this detail.
The next circle is the Controllers one, aka interface adapters. They're exact implementations of the persistence abstractions invoked in the Use cases circle. Typically, they'll facilitate data exchange between real databases, messaging queues, external APIs, or HTTP requests, and the inner circle. For example, we could convert here our domain Order into a row that can be persisted in the database.
The final circle stands for Devices and interfaces. That's where all external services or databases expected by inner circles are living. You'll find here some infrastructure with databases but also frameworks used to build the application.
Clean architecture for data engineers
Applying the clean architecture as-is to data engineering projects is risky. It might lead to many unnecessary abstractions that will complexify the code without reason. Therefore, instead of trying to translate clean architecture to data engineering workloads, let's try to adapt it.
As I have been specializing in Apache Spark over the years, I'll use it as an example and, hopefully, share one way for organizing the code for PySpark jobs running on Databricks (since it's another tool I've been extensively working on over the years 😉).
Our workflow consists of many CSV files that should ultimately be combined to a single DataFrame, and written to a Delta Lake table. We can illustrate it as follows:
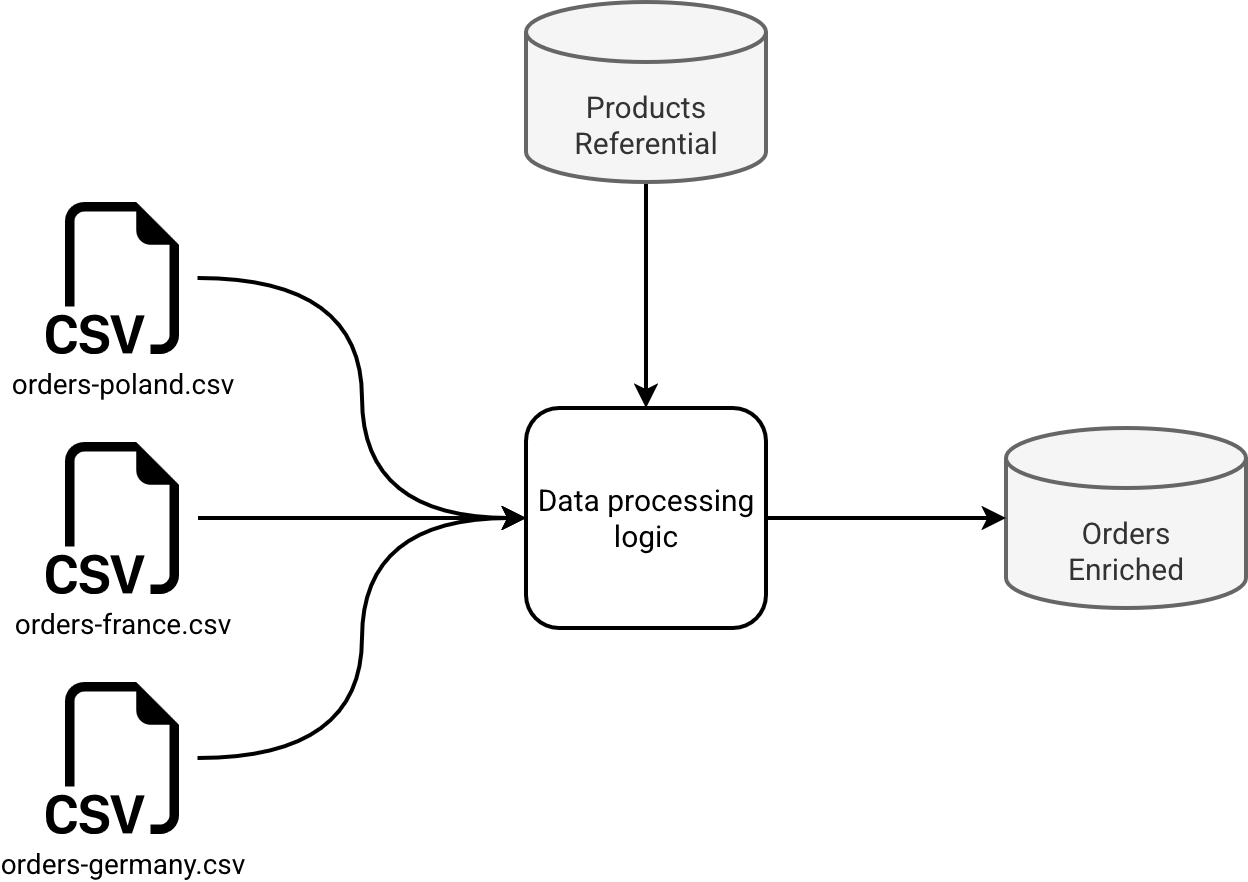
Because it's hard to translate this workflow to circle-based clean architecture, let's see how to represent it with layered boxes:
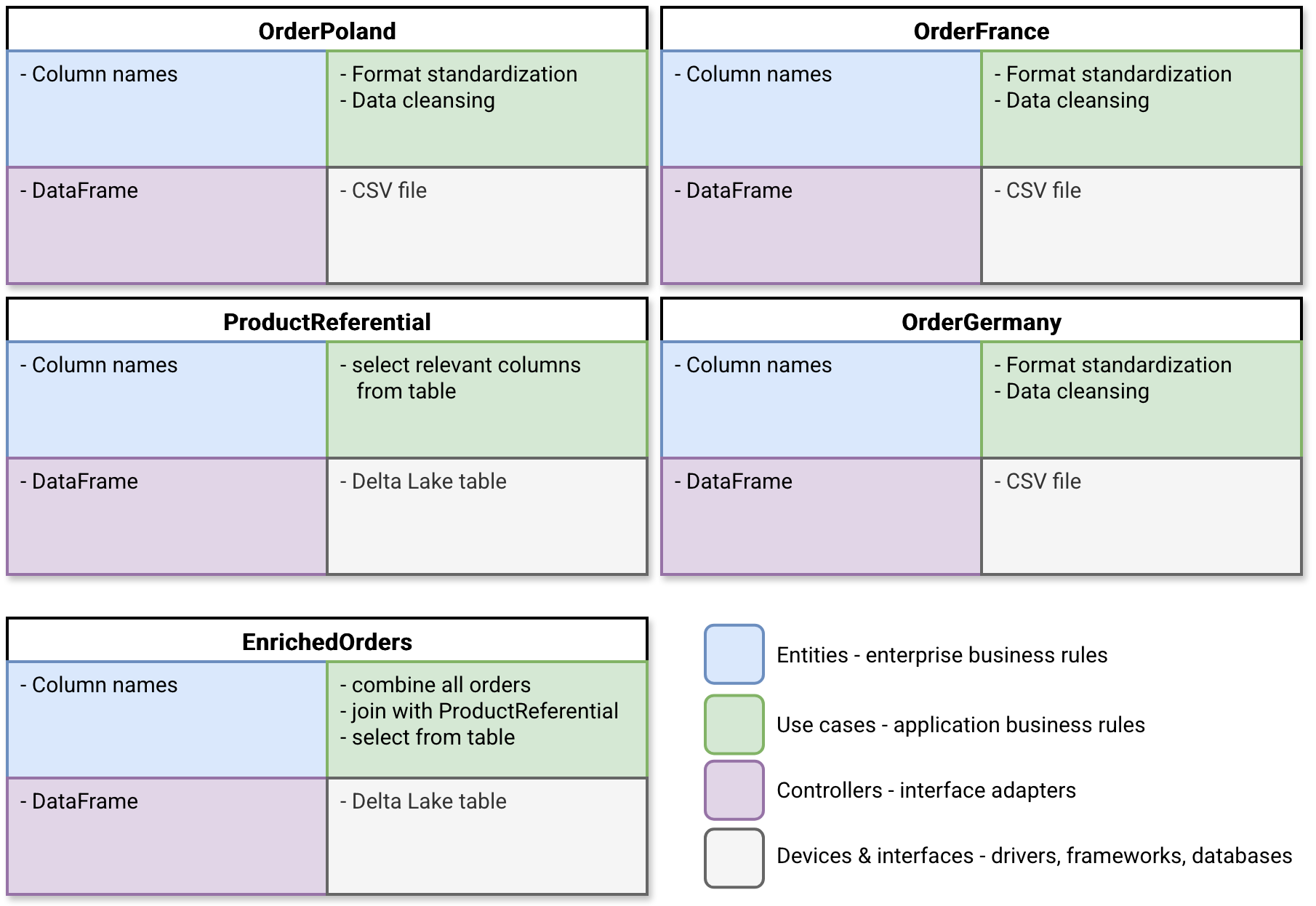
Let see how this organization fits to the onion-based organization of clean architecture:
- Entity is a domain object with the column names present, respectively in the CSV files for the orders, and in the Delta Lake table for the product referential. It doesn't know anything about other layers.
- Use cases are data transformations on top of the Entities. Consequently each use case needs to know the column names but on another side, it can completely ignore the interface adapter. Technically, it only has to be a DataFrame, a little bit like data repository interfaces for software engineering.
- Controllers are only interfaces for a data store but they don't need to be the data stores used for real. For testing you could for example replace Delta Lake tables with in-memory DataFrames. Consider it as repository implementations either for testing with in-memory DataFrames, for local runs with file-based data sources, or for production execution with real databases behind.
- Finally, the Delta Lake tables and CSV files are the real things where our data lives.
Even though I could introduce the real data repositories abstraction to generate DataFrames, I won't to that. Repositories are an additional abstraction that - subjectively speaking - brings an extra indirection layer making the whole understanding more challenging. That's why the DataFrames from the Controllers circle will be for me...simple DataFrames that might be generated by a Use case.
To see this clean architecture in the PySpark context, let's take a look at the code snippets:
- Orders entity (leaving only one country because it's very similar):
@dataclass class OrderPoland: CUSTOMER_ID = 'customer_id' ITEM_ID = 'item_id' MANUFACTURER = 'manufacturer' DATE = 'date' LABEL = 'label' VALUE = 'value' UNITS = 'units' UNITS_TYPE_ENTITY = 'units_type_entity' @classmethod def prepare_dataframe(clz, order_to_process: DataFrame) -> DataFrame: prepared_order = order_to_process.withColumnsRenamed({ clz.CUSTOMER_ID: EnrichedOrder.CUSTOMER, clz.DATE: EnrichedOrder.ORDER_DATE, clz.UNITS_TYPE_ENTITY: EnrichedOrder.UNITS_TYPE }) return prepared_order.drop(clz.LABEL) - Product referential entity:
@dataclass class ProductReferential: ITEM_ID = 'item_id' MANUFACTURER = 'manufacturer' MODEL = 'model' ALL_COLUMNS = [ITEM_ID, MANUFACTURER, MODEL] def prepare_dataframe(self, product_referential: DataFrame) -> DataFrame: return product_referential.select(self.ALL_COLUMNS) - Enriched orders entity:
@dataclass class EnrichedOrder: CUSTOMER = 'customer' ITEM_ID = ProductReferential.ITEM_ID MANUFACTURER = ProductReferential.MANUFACTURER ORDER_DATE = 'order_date' VALUE = 'value' UNITS = 'units' UNITS_TYPE = 'units_type' ALL_COLUMNS = [CUSTOMER, ITEM_ID, MANUFACTURER, ORDER_DATE, VALUE, UNITS, UNITS_TYPE] @classmethod def prepare_enriched_order(clz, orders_poland: DataFrame, orders_france: DataFrame, orders_germany: DataFrame, referential_product: DataFrame) -> DataFrame: unified_orders = (orders_poland.unionByName(orders_germany, allowMissingColumns=False) .unionByName(orders_france, allowMissingColumns=False)) enriched_orders = unified_orders.join(referential_product, on=[ProductReferential.ITEM_ID, ProductReferential.MANUFACTURER], how='left') return enriched_orders.select(clz.ALL_COLUMNS - Main job that I'm considering here as the ultimate Devices and interfaces layer connecting everything:
def generate_enriched_orders(raw_poland: DataFrame, raw_france: DataFrame, raw_germany: DataFrame, raw_referential_data: DataFrame) -> DataFrame: orders_poland = OrderPoland.prepare_dataframe(raw_poland) orders_france = OrderFrance.prepare_dataframe(raw_france) orders_germany = OrderGermany.prepare_dataframe(raw_germany) referential_data = ProductReferential.prepare_dataframe(raw_referential_data) enriched_orders = EnrichedOrder.prepare_enriched_order( orders_poland=orders_poland, orders_france=orders_france, orders_germany=orders_germany, referential_product=referential_data ) return enriched_orders if __name__ == '__main__': spark = (configure_spark_with_delta_pip(SparkSession.builder.master("local[*]") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") .config("spark.sql.warehouse.dir", "../data/catalog") ).getOrCreate()) enriched_orders = generate_enriched_orders( raw_poland=spark.read.csv('../data/poland_orders', header=True, inferSchema=True), raw_france=spark.read.csv('../data/france_orders', header=True, inferSchema=True), raw_germany=spark.read.csv('../data/germany_orders', header=True, inferSchema=True), raw_referential_data=spark.read.table('product_referential') ) enriched_orders.write.format('delta').mode('overwrite').saveAsTable('enriched_orders')
Clean Architecture provides a robust framework for decoupling layers within your codebase. As demonstrated in this post, despite its origins in pure software engineering, these concepts are highly applicable to the data engineering context.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩