
Some time ago when I was analyzing the execution of my Apache Spark job on Spark UI, I noticed a limit(...) action. It was weird as I actually was running only the show(...) command to display the DataFrame locally. At the time I understood why but hadn't found time to write a blog post. Recently Antoni reminded me on LinkedIn that I should have blogged about show(...) back then to better answer his question :)
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
At no surprise, the show action is built upon other Apache Spark primitives. The limit(...) mentioned previously in the blog post is only one of them. To understand it better, let's take a look at the execution stack. As you can see, whenever you invoke the show(...) method, you inherently invoke take and collect actions:

You can also notice three parameters accepted by the show(...) action. The first of them, the numRows is obvious. It sets the number of rows to display. However, it might not be your number. Apache Spark performs some gatekeeping action to prevent you from setting too small (negative) or too big (bigger than Integer.MAX_VALUE - 15 - 1):
val numRows = _numRows.max(0).min(ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH - 1)
🗒 Collect and memory limits
Keep in mind the show() action executes a collect() under-the-hood, meaning all the rows are transferred to the driver. Even though you define a big number of rows to display, the operation can still end with an Out-Of-Memory error.
The second parameter of the show(...) action is truncate. Although you define it as a bool, internally Apache Spark passes it as an int. Why so? First, when you call the show(...), Apache Spark interprets your truncation intent by converting it to 0 or 20:
def show(numRows: Int, truncate: Boolean): Unit = if (truncate) {
println(showString(numRows, truncate = 20))
} else {
println(showString(numRows, truncate = 0))
}
As you can see, you can either fully disable string truncation, or only ask Apache Spark to show you 20 first characters each time. There is no way - besides doing it in the select preceding your show(...) - to configure the number of displayed characters. Later, this 0 or 20 is passed to the getRows where each column is truncated or not after reading it from the dataset:
row.toSeq.map { cell =>
// Escapes meta-characters not to break the `showString` format
val str = SchemaUtils.escapeMetaCharacters(cell.toString)
if (truncate > 0 && str.length > truncate) {
// do not show ellipses for strings shorter than 4 characters.
if (truncate < 4) str.substring(0, truncate)
else str.substring(0, truncate - 3) + "..."
} else {
str
}
}
Before we go to the next parameters, I owe you a precision. The getRows command quoted previously doesn't respect the numRows specified at the input. It always takes one additional row to tell you there is or there isn't more data than you asked (the only showing top x rows from the display):
private[sql] def getRows(numRows: Int, truncate: Int): Seq[Seq[String]] = {
val newDf = commandResultOptimized.toDF()
val castCols = newDf.logicalPlan.output.map { col =>Column(ToPrettyString(col))}
val data = newDf.select(castCols: _*).take(numRows + 1)
You should also notice that when you analyze the execution plan on Spark UI. Here is my example for showing only 5 rows:
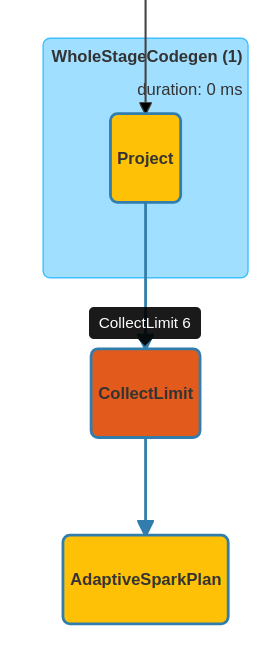
Finally, depending on the third parameters which is vertical boolean flag, you can decide to display the DataFrame as a regular table, or as a vertical table composed of column name and value in rows. You can see how both behave in the last image:
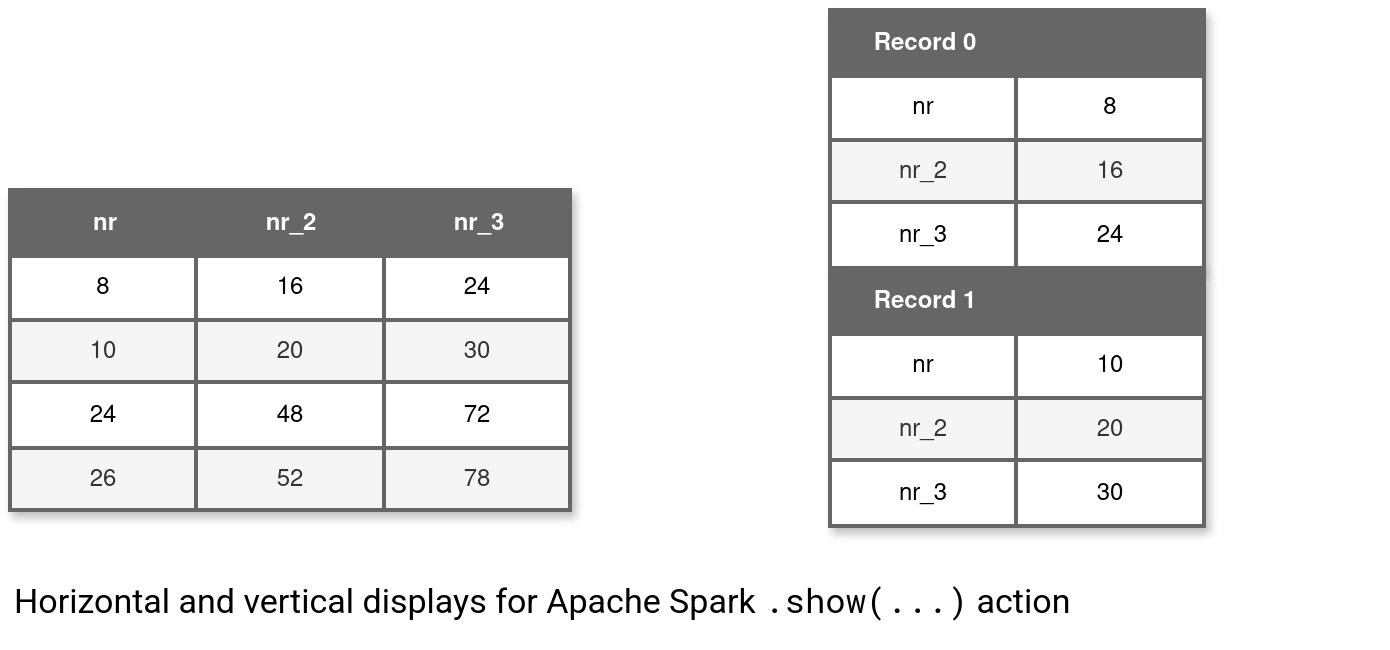
Apache Spark's show(...) action is a convenient debugging method to understand how your data processing logic works. It's even more powerful when you combine it with a dedicated UI backend as Databricks notebooks where you can operate on the visual tabular output. Just one thing to remember in that case, instead of show(...) always use the display!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩