
Predicate pushdown is a data processing technique taking user-defined filters and executing them while reading the data. Apache Spark already supported it for Apache Parquet and RDBMS. Starting from Apache Spark 3.1.1, you can also use them for Apache Avro, JSON and CSV formats!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
General predicate pushdown flow
But before going into details, let's see what is the general flow for the predicate pushdown support in DataSources V2. File-based sources implement a FileScanBuilder abstract class. Every FileScanBuilder implementation supporting predicate pushdown also extends the SupportsPushDownFilters trait exposing 2 interface methods:
public interface SupportsPushDownFilters extends ScanBuilder {
Filter[] pushFilters(Filter[] filters);
Filter[] pushedFilters();
}
The former takes all the query filters and returns an array with the filters to apply after the data source's physical scan. You will find that this kind of filter is called post scan filters in the code source. They will apply after reading a row and converting it into Apache Spark's Row format. The second method returns all push down filters, so the ones executed while reading the record from the data source.
Both functions are needed by a PushDownUtils class called by the logical optimization rule called V2ScanRelationPushDown. Whenever the query planner encounters a ScanOperation node, it first creates the ScanBuilder instance (FileScanBuilder in our case) and later calls PushDownUtils' pushFilters(scanBuilder: ScanBuilder, filters: Seq[Expression]) method to return the pushed and post-scan filters. Just after that, the rule creates a Scan instance corresponding to the processed file format. But at that time, it doesn't use the pushed filters! Let me show you:
object V2ScanRelationPushDown extends Rule[LogicalPlan] {
import DataSourceV2Implicits._
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
case ScanOperation(project, filters, relation: DataSourceV2Relation) =>
val scanBuilder = relation.table.asReadable.newScanBuilder(relation.options)
val normalizedFilters = DataSourceStrategy.normalizeExprs(filters, relation.output)
val (normalizedFiltersWithSubquery, normalizedFiltersWithoutSubquery) =
normalizedFilters.partition(SubqueryExpression.hasSubquery)
// `pushedFilters` will be pushed down and evaluated in the underlying data sources.
// `postScanFilters` need to be evaluated after the scan.
// `postScanFilters` and `pushedFilters` can overlap, e.g. the parquet row group filter.
val (pushedFilters, postScanFiltersWithoutSubquery) = PushDownUtils.pushFilters(
scanBuilder, normalizedFiltersWithoutSubquery)
val postScanFilters = postScanFiltersWithoutSubquery ++ normalizedFiltersWithSubquery
val normalizedProjects = DataSourceStrategy
.normalizeExprs(project, relation.output)
.asInstanceOf[Seq[NamedExpression]]
val (scan, output) = PushDownUtils.pruneColumns(
scanBuilder, relation, normalizedProjects, postScanFilters)
val wrappedScan = scan match {
case v1: V1Scan =>
val translated = filters.flatMap(DataSourceStrategy.translateFilter(_, true))
V1ScanWrapper(v1, translated, pushedFilters)
case _ => scan
}
// ...
The extracted pushed filters are only there for the V1 DataSources that would like to use DataSource V2 implementation! Actually, the real push down of the filters takes place in the corresponding ScanBuilders via the aforementioned pushedFilters method. The method is internally used by the builders to pass the pushed predicates to the Scan operation! Below you can find an example for JSON data source that I will describe in the next section:
class JsonScanBuilder (
sparkSession: SparkSession,
fileIndex: PartitioningAwareFileIndex,
schema: StructType,
dataSchema: StructType,
options: CaseInsensitiveStringMap)
extends FileScanBuilder(sparkSession, fileIndex, dataSchema) with SupportsPushDownFilters {
override def build(): Scan = {
JsonScan(
sparkSession,
fileIndex,
dataSchema,
readDataSchema(),
readPartitionSchema(),
options,
pushedFilters())
}
private var _pushedFilters: Array[Filter] = Array.empty
override def pushFilters(filters: Array[Filter]): Array[Filter] = {
if (sparkSession.sessionState.conf.jsonFilterPushDown) {
_pushedFilters = StructFilters.pushedFilters(filters, dataSchema)
}
filters
}
override def pushedFilters(): Array[Filter] = _pushedFilters
JSON predicate pushdown
If you check the JsonScan implementation, you will notice a pushedFilters attribute in the constructor:
case class JsonScan(
// ...
pushedFilters: Array[Filter],
partitionFilters: Seq[Expression] = Seq.empty,
dataFilters: Seq[Expression] = Seq.empty)
extends TextBasedFileScan(sparkSession, options) {
The partition reader factory instance (JsonPartitionReaderFactory) uses these pushedFilters to build the PartitionReader:
case class JsonPartitionReaderFactory(
sqlConf: SQLConf,
broadcastedConf: Broadcast[SerializableConfiguration],
dataSchema: StructType,
readDataSchema: StructType,
partitionSchema: StructType,
parsedOptions: JSONOptionsInRead,
filters: Seq[Filter]) extends FilePartitionReaderFactory {
// ...
override def buildReader(partitionedFile: PartitionedFile): PartitionReader[InternalRow] = {
val actualSchema =
StructType(readDataSchema.filterNot(_.name == parsedOptions.columnNameOfCorruptRecord))
val parser = new JacksonParser(
actualSchema,
parsedOptions,
allowArrayAsStructs = true,
filters)
As you can see then, the pushed filters evaluate at the JacksonParser level; i.e, when Apache Spark converts JSON textual rows into InternalRow format. In other words, the filter applies on before returning the row in the SELECT statement.
Initially, I wrongly thought that the pushed filters work on the raw (= not Spark internal) format. However, if we check the JSON implementation, we'll see that the rows are first converted from the raw format into InternalRow, and only later validated against the pushed filters!
JSON pushed filters are represented by the JsonFilters class. It builds an array of position-based JsonPredicate filters. What does it mean, a position-based? Every field in the input schema has a position. JsonFilters relies on these position to create pushed filters corresponding to the given field:
private val predicates: Array[Array[JsonPredicate]] = {
val groupedPredicates = Array.fill(schema.length)(Array.empty[JsonPredicate])
// …
// BK: Prepare the correct type of every existing
// pushed filter. Thanks to the groupedPredicates setup,
// the fields without filters will have an empty filters array
groupedByFields.foreach { case (fieldName, fieldPredicates) =>
val fieldIndex = schema.fieldIndex(fieldName)
groupedPredicates(fieldIndex) = fieldPredicates.map(_._2).toArray
}
groupedPredicates
}
JsonFilters also exposes a skipRow method used by JSON-to-InternalRow converter to check whether the converted row should be filtered out:
class JsonFilters(pushedFilters: Seq[sources.Filter], schema: StructType)
extends StructFilters(pushedFilters, schema) {
// ...
def skipRow(row: InternalRow, index: Int): Boolean = {
var skip = false
for (pred <- predicates(index) if !skip) {
pred.refCount -= 1
skip = pred.refCount == 0 && !pred.predicate.eval(row)
}
skip
}
}
class JacksonParser(
schema: DataType,
val options: JSONOptions,
allowArrayAsStructs: Boolean,
filters: Seq[Filter] = Seq.empty) extends Logging {
// ...
private def convertObject( // ...
var skipRow = false
structFilters.reset()
while (!skipRow && nextUntil(parser, JsonToken.END_OBJECT)) {
schema.getFieldIndex(parser.getCurrentName) match {
case Some(index) =>
try {
row.update(index, fieldConverters(index).apply(parser))
skipRow = structFilters.skipRow(row, index)
} catch {
case e: SparkUpgradeException => throw e
case NonFatal(e) if isRoot =>
badRecordException = badRecordException.orElse(Some(e))
parser.skipChildren()
}
case None =>
parser.skipChildren()
}
}
if (skipRow) {
None
} else if (badRecordException.isEmpty) {
Some(row)
} else {
throw PartialResultException(row, badRecordException.get)
}
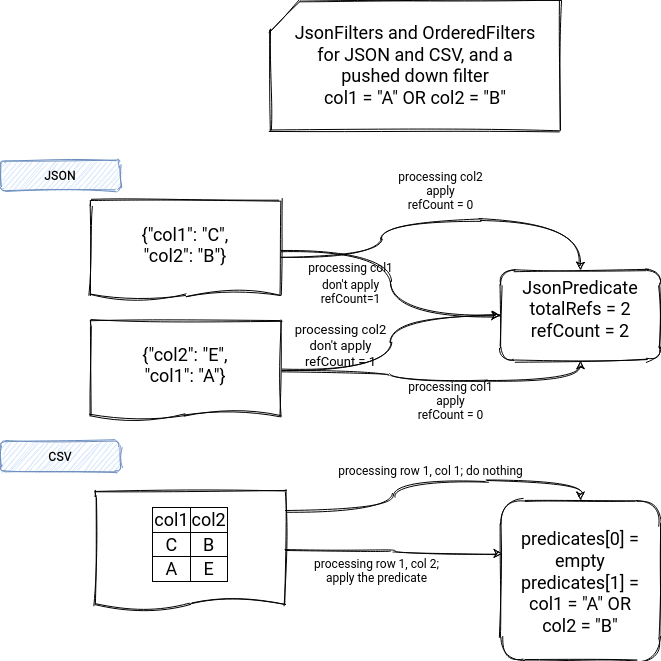
Calling the reset() is quite important because it resets the internal state of the filters. JsonFilters assumes that every skipRow call is preceded by the reset one.
Why the filter is stateful?
If you're wondering why, it's a good question! A filter can apply to 1 or multiple attributes. An example of a complex filter is an expression like WHERE (col1 = "A" OR col2 = "C"). To execute the filter, we need then to be sure that both columns are ready (technically, we could simply check the first condition for the "OR" statement here but it would complexify the implementation a lot).
To make it possible, JsonPredicate created in JsonFilters for each filter expression, stores the number of columns referencing it. In our example, this number of columns would be 2.
Knowing that the fields in a JSON row don't have to be always defined in the same order, JsonPredicate doesn't apply sequentially; i.e, in our example, it won't always apply after converting col2. Instead, it internally counts the number of already processed columns of the filter:
case class JsonPredicate(predicate: BasePredicate, totalRefs: Int) {
var refCount: Int = totalRefs
def reset(): Unit = {refCount = totalRefs}
}
That' the reason why in the skipRow snippet presented above (skip = pred.refCount == 0 && !pred.predicate.eval(row)), you can see that the predicate applies only when all columns were resolved.
And since a given JsonPredicate will be shared by all rows processed in the given input partition, it's automatically mutable, hence, it requires the reset() method to be called before processing every new JSON row. You will see later that it won't be required for CSV and Avro which rely on the position of the last field present in the filter expression.
JSON predicate pushdown is not yet supported for nested columns (check SPARK-32325 and can be disabled with spark.sql.json.filterPushdown.enabled.
CSV predicate pushdown
Regarding CSV, the execution flow is the same as for JSON, i.e, it passes the pushed predicates from the CSV ScanBuilder to the CSV PartitionReader. That's why, instead of repeating this information, let's focus on the filtering execution step only. The class responsible for converting textual CSV to InternalRow format is UnivocityParser. Inside the parser you will find a snippet initializing the pushed filters, also conditioned by a configuration property enabled by default:
class UnivocityParser(
dataSchema: StructType,
requiredSchema: StructType,
val options: CSVOptions,
filters: Seq[Filter]) extends Logging {
// ...
private val csvFilters = if (SQLConf.get.csvFilterPushDown) {
new OrderedFilters(filters, requiredSchema)
} else {
new NoopFilters
}
OrderedFilters is another type of StructFilters which also creates a position-based filters array. Cross-field filters that apply to 2 or more attributes always apply to the schema's last attribute. You will find a great example of it in the inline comment below:
/**
* Converted filters to predicates and grouped by maximum field index
* in the read schema. For example, if an filter refers to 2 attributes
* attrA with field index 5 and attrB with field index 10 in the read schema:
* 0 === $"attrA" or $"attrB" < 100
* the filter is compiled to a predicate, and placed to the `predicates`
* array at the position 10. In this way, if there is a row with initialized
* fields from the 0 to 10 index, the predicate can be applied to the row
* to check that the row should be skipped or not.
// ...
*/
private val predicates: Array[BasePredicate] = {
val len = requiredSchema.fields.length
val groupedPredicates = Array.fill[BasePredicate](len)(null)
val groupedFilters = Array.fill(len)(Seq.empty[sources.Filter])
for (filter <- filters) {
val refs = filter.references
val index = if (refs.isEmpty) {
// For example, `AlwaysTrue` and `AlwaysFalse` doesn't have any references
// Filters w/o refs always return the same result. Taking into account
// that predicates are combined via `And`, we can apply such filters only
// once at the position 0.
0
} else {
refs.map(requiredSchema.fieldIndex).max
}
groupedFilters(index) :+= filter
}
// ...
for (i <- 0 until len) {
if (groupedFilters(i).nonEmpty) {
groupedPredicates(i) = toPredicate(groupedFilters(i))
}
}
groupedPredicates
}
As for JSON, CSV also uses the same interface exposing the reset-skipRow assumption. However, there is no need to involve the reset because the data source is position-based (= columns are always resolved in the same order!), and therefore the filter can be applied sequentially:
class OrderedFilters(filters: Seq[sources.Filter], requiredSchema: StructType)
extends StructFilters(filters, requiredSchema) {
def skipRow(row: InternalRow, index: Int): Boolean = {
assert(0 <= index && index < requiredSchema.fields.length,
"Index is out of the valid range: it must point out to a field of the required schema.")
val predicate = predicates(index)
predicate != null && !predicate.eval(row)
}
def reset(): Unit = {}
}
class UnivocityParser(
dataSchema: StructType,
requiredSchema: StructType,
val options: CSVOptions,
filters: Seq[Filter]) extends Logging {
private def convert(tokens: Array[String]): Option[InternalRow] = {
// ...
var i = 0
val row = requiredRow.get
var skipRow = false
while (i < requiredSchema.length) {
try {
if (skipRow) {
row.setNullAt(i)
} else {
row(i) = valueConverters(i).apply(getToken(tokens, i))
if (csvFilters.skipRow(row, i)) {
skipRow = true
}
}
// ...
if (skipRow) {
noRows
} else {
if (badRecordException.isDefined) {
throw BadRecordException(
() => getCurrentInput, () => requiredRow.headOption, badRecordException.get)
} else {
requiredRow
}
}
}
}
You can find the comparison of both approaches in the following schema:
Apache Avro predicate pushdown
Apache Avro data source also relies on the stateless OrderedFilters instance and the same ScanBuilder → PartitionReader flow:
case class AvroPartitionReaderFactory(
sqlConf: SQLConf,
broadcastedConf: Broadcast[SerializableConfiguration],
dataSchema: StructType,
readDataSchema: StructType,
partitionSchema: StructType,
parsedOptions: AvroOptions,
filters: Seq[Filter]) extends FilePartitionReaderFactory with Logging {
override def buildReader(partitionedFile: PartitionedFile): PartitionReader[InternalRow] = {
// ...
val avroFilters = if (SQLConf.get.avroFilterPushDown) {
new OrderedFilters(filters, readDataSchema)
} else {
new NoopFilters
}
val fileReader = new PartitionReader[InternalRow] with AvroUtils.RowReader {
override val fileReader = reader
override val deserializer = new AvroDeserializer(
userProvidedSchema.getOrElse(reader.getSchema),
readDataSchema,
datetimeRebaseMode,
avroFilters)
As previously, the factory passes the pushed filters to the converter instance which for Avro file format is AvroDeserializer. It uses them inside the getRecordWriter method returning false if the row shouldn't be filtered out. Regarding the filtering logic itself, it uses the same principle as previously, so after updating every field, it calls the skipRow of the OrderedFilters:
private[sql] class AvroDeserializer(
rootAvroType: Schema,
rootCatalystType: DataType,
datetimeRebaseMode: LegacyBehaviorPolicy.Value,
filters: StructFilters) {
// …
def deserialize(data: Any): Option[Any] = converter(data)
private val converter: Any => Option[Any] = rootCatalystType match {
// ...
case st: StructType =>
val resultRow = new SpecificInternalRow(st.map(_.dataType))
val fieldUpdater = new RowUpdater(resultRow)
val applyFilters = filters.skipRow(resultRow, _)
val writer = getRecordWriter(rootAvroType, st, Nil, applyFilters)
(data: Any) => {
val record = data.asInstanceOf[GenericRecord]
val skipRow = writer(fieldUpdater, record)
if (skipRow) None else Some(resultRow)
}
// ...
}
}
private def getRecordWriter(
avroType: Schema,
sqlType: StructType,
path: List[String],
applyFilters: Int => Boolean): (CatalystDataUpdater, GenericRecord) => Boolean = {
val validFieldIndexes = ArrayBuffer.empty[Int]
val fieldWriters = ArrayBuffer.empty[(CatalystDataUpdater, Any) => Unit]
val length = sqlType.length
var i = 0
while (i < length) {
// ...
(fieldUpdater, record) => {
var i = 0
var skipRow = false
while (i < validFieldIndexes.length && !skipRow) {
fieldWriters(i)(fieldUpdater, record.get(validFieldIndexes(i)))
skipRow = applyFilters(i)
i += 1
}
skipRow
}
}
Since the execution flow for all the 3 file formats is the same, in the demo I will focus only on the JSON data source:
According to the benchmarks made by the author of the changes, Max Gekk, the queries benefiting from the predicate pushdowns execute much faster (2x for Avro and even 25x for JSON on JDK 11). I can't wait to see how it will change for the nested fields pushed filters!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.1 - predicate pushdown for JSON, CSV and Apache Avro here:
Related blog posts:
- What's new in Apache Spark 3.1.1 - new built-in functions
- What's new in Apache Spark 3.1 - JDBC (WIP) and DataSource V2 API
- What's new in Apache Spark 3.1 - Kubernetes Generally Available!
- What's new in Apache Spark 3.1 - nodes decommissioning
- What's new in Apache Spark 3.1 - Project Zen
Starting from #ApacheSpark 3.1, Apache Avro, CSV and JSON support predicate pushdown! If you want to discover the new classes involved in this feature, you can check my new blog post ? https://t.co/sd3QX1Hm02
— Bartosz Konieczny (@waitingforcode) April 10, 2021