
I have a feeling that a lot of things related to the scalability happened in the 3.1 release. General Availability of Kubernetes that I will cover next week is only one of them. The second one is the nodes decommissioning!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Nodes decommissioning?
Yes, that's the first important question to answer before digging deeper into the code. Why should we manage a decommissioned node? The whys are pretty clearly presented in the design doc associated to the SPARK-20624. Holden Karau, who is the main author of the node decommissioning feature, shared a list of situations where you can need it:
- on the cloud if you use spot or preemptible instances for costs optimization; in such a scenario, these instances can go away at any moment, and you may need to recompute the tasks they executed
- on a shared cluster where the jobs with a higher priority can take the resources used by lower priority and already running jobs
The most problematic point with losing an executor is the need to recompute the shuffle or cached data. The node decommissioning feature lets you enable blocks and shuffle data migration before the node goes away to mitigate the issue.
Node decommissioning and the data
When I analyzed the node decommissioning feature, I concluded with a logical division for the node decommissioning operations. The first category groups metadata actions like the worker's exclusion from the list of schedulable resources. The second category applies to the data and concerns shuffle files and RDD blocks migration. And I will start here with the data part.
The data decommissioning part happens in the decommissionSelf() method of the CoarseGrainedSchedulerBackend. In the beginning, the method verifies whether the node decommissioning feature is enabled, so whether the value of spark.decommission.enabled is true. At this moment, the executor also checks whether it's not already running the decommissioning process. If yes, it doesn't continue the decommissioning at this stage and lets the started one terminate.
After these 2 checks, the executor marks itself in the decommissioned state and starts the data migration task. Once again, only if it's enabled with spark.storage.decommission.enabled property. If yes, the executor sends a DecommissionBlockManager message to its block manager. The block manager reacts to this message by initializing a BlockManagerDecommissioner and starting yet another self-decommissioning process:
private[spark] def decommissionSelf(): Unit = synchronized {
decommissioner match {
case None =>
logInfo("Starting block manager decommissioning process...")
decommissioner = Some(new BlockManagerDecommissioner(conf, this))
decommissioner.foreach(_.start())
case Some(_) =>
logDebug("Block manager already in decommissioning state")
}
}
The decommissioner calls the start() method where it physically migrates the data to available peer block managers. If there is no existing peers, the decommissioner can use the fallback storage if it's enabled in spark.storage.decommission.fallbackStorage.path:
private[storage] def getPeers(forceFetch: Boolean): Seq[BlockManagerId] = {
peerFetchLock.synchronized {
val cachedPeersTtl = conf.get(config.STORAGE_CACHED_PEERS_TTL) // milliseconds
val diff = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - lastPeerFetchTimeNs)
val timeout = diff > cachedPeersTtl
if (cachedPeers == null || forceFetch || timeout) {
cachedPeers = master.getPeers(blockManagerId).sortBy(_.hashCode)
lastPeerFetchTimeNs = System.nanoTime()
logDebug("Fetched peers from master: " + cachedPeers.mkString("[", ",", "]"))
}
if (cachedPeers.isEmpty &&
conf.get(config.STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH).isDefined) {
Seq(FallbackStorage.FALLBACK_BLOCK_MANAGER_ID)
} else {
cachedPeers
}
}
}
After finding the peers, the decommissioner starts the replication. A similar workflow applies to the shuffle files except that its execution is controlled with spark.storage.decommission.shuffleBlocks.enabled property. The executor later checks the migration state by continuously calling the lastMigrationInfo():
while (true) {
logInfo("Checking to see if we can shutdown.")
if (executor == null || executor.numRunningTasks == 0) {
if (env.conf.get(STORAGE_DECOMMISSION_ENABLED)) {
logInfo("No running tasks, checking migrations")
val (migrationTime, allBlocksMigrated) = env.blockManager.lastMigrationInfo()
// We can only trust allBlocksMigrated boolean value if there were no tasks running
// since the start of computing it.
if (allBlocksMigrated && (migrationTime > lastTaskRunningTime)) {
logInfo("No running tasks, all blocks migrated, stopping.")
exitExecutor(0, "Finished decommissioning", notifyDriver = true)
} else {
logInfo("All blocks not yet migrated.")
}
What does this allBlocksMigrated hide? Once the replication terminated, the shuffle and cache replication methods update, respectively, the stoppedShuffle and stoppedRDD variables. If both are set to true, it means that the replication terminated or it was not required for the given data type. allBlocksMigrated in that case will return true and the executor can gracefully shutdown.
After a successful decommissioning, the executor notifies the driver with the RemoveExecutor message having the "Finished decommissioning" as the removal reason. You can find the summary of this self-decommissioning in the schema below:
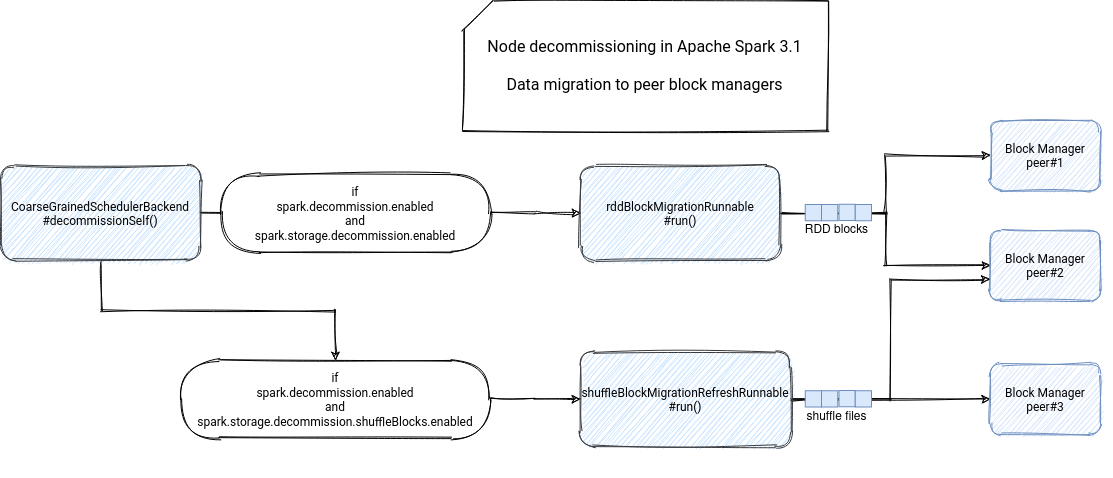
Decommissioning trigger
Now, the tricker part, i.e. how does the decommissioning even start?! The first implemented trigger is the PWR signal. The executors and workers listen for it by attaching a listener to SignalUtils:
if (conf.get(config.DECOMMISSION_ENABLED)) {
logInfo("Registering SIGPWR handler to trigger decommissioning.")
SignalUtils.register("PWR", "Failed to register SIGPWR handler - " +
"disabling worker decommission feature.") {
self.send(WorkerSigPWRReceived) // or ExecutorSigPWRReceived
true
}
} else {
logInfo("Worker decommissioning not enabled, SIGPWR will result in exiting.")
}
When the listener intercepts the signal, it sends the ExecutorSigPWRReceived or WorkerSigPWRReceived to itself - depending on the place intercepting the signal. The worker will be the place used for standalone cluster manager whereas the executor will be the one involved in Kubernetes.
Both will communicate with the driver but differently! The worker will first reach the master with WorkerDecommissioning message. The master will later get all executors of the worker, mark each of them as decommissioned, and finally send the ExecutorUpdated message, one per every executor, to the driver. The driver will take the message and send the DecommissionExecutor message to the corresponding executor. Upon receiving this message, the executor starts the decommissioning process described in the previous section. The following schema summarizes these interactions:
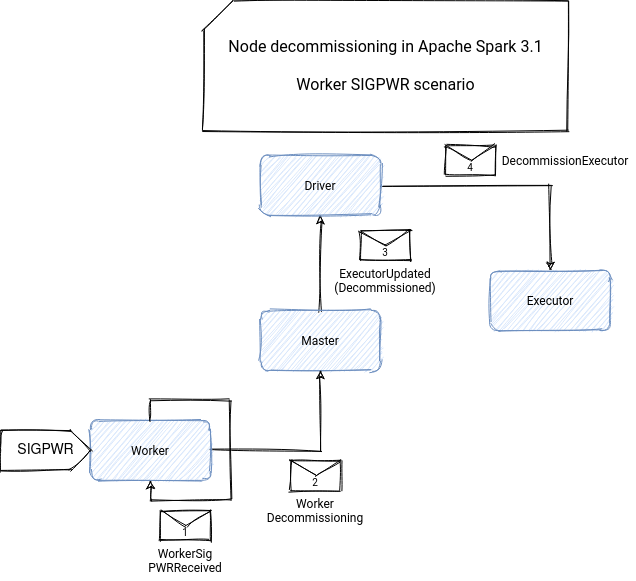
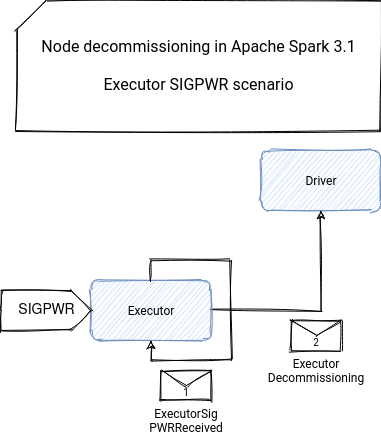
Regarding the executor-first scenario, before starting the decommissioning described above, it notifies the driver about this fact by sending the ExecutorDecommissioning message. Thanks to it, the driver makes all necessary tasks to not include this executor in the tasks scheduling. Apart from the scheduling, it will also tell the master block manager that it should mark the block manager of the decommissioned executor as decommissioned, so that they're not used in any replication or migration task. After getting a successful response of the driver, the executor starts the self-decommissioning as explained in the previous section:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case ExecutorSigPWRReceived =>
var driverNotified = false
try {
driver.foreach { driverRef =>
// Tell driver that we are starting decommissioning so it stops trying to schedule us
driverNotified = driverRef.askSync[Boolean](ExecutorDecommissioning(executorId))
if (driverNotified) decommissionSelf()
}
And as for the worker, an associated workflow:
HTTP endpoint trigger
In addition to the signal trigger, in a standalone cluster you can also decommission a node from an HTTP endpoint called /workers/kill:
private[master]
class MasterWebUI(
val master: Master,
requestedPort: Int)
// ...
def initialize(): Unit = {
val masterPage = new MasterPage(this)
attachPage(new ApplicationPage(this))
attachPage(masterPage)
addStaticHandler(MasterWebUI.STATIC_RESOURCE_DIR)
// ...
attachHandler(createServletHandler("/workers/kill", new HttpServlet {
override def doPost(req: HttpServletRequest, resp: HttpServletResponse): Unit = {
val hostnames: Seq[String] = Option(req.getParameterValues("host"))
.getOrElse(Array[String]()).toSeq
if (!isDecommissioningRequestAllowed(req)) {
resp.sendError(HttpServletResponse.SC_METHOD_NOT_ALLOWED)
} else {
val removedWorkers = masterEndpointRef.askSync[Integer](
DecommissionWorkersOnHosts(hostnames))
logInfo(s"Decommissioning of hosts $hostnames decommissioned $removedWorkers workers")
if (removedWorkers > 0) {
resp.setStatus(HttpServletResponse.SC_OK)
} else if (removedWorkers == 0) {
resp.sendError(HttpServletResponse.SC_NOT_FOUND)
} else {
// We shouldn't even see this case.
resp.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR)
}
}
}
As you can see, this time the master gets a DecommissionWorkersOnHosts message. Upon receiving this message, the master sends the DecommissionWorkers message to itself.
Later, it will send 2 messages. First, it will notify the driver about the decommissioning of the executors running on the worker with the already mentioned ExecutorUpdated message. The executor will start the decommissioning. In the second message, the master will send the DecommissionWorker message to every decommissioned worker. Each of the workers will set the decommissioned state to true.
You can find the summary of the interactions below:
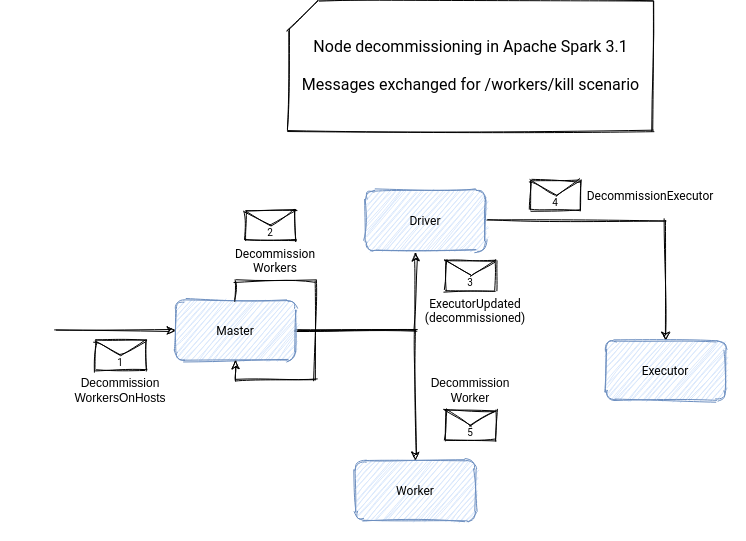
Please notice that the nodes decommissioning feature doesn't guarantee a full replication, though! If a cloud provider reclaims the preemptible or spot instance you're using, it can give you some delay before taking it back, but this delay is unaware of your shutdown process. Despite that fact, the feature implemented by Holder Karau, Prakhar Jain, Devesh Agrawal, and Wuyi is a good step forward to adapt Apache Spark to a dynamic and elastic cloud computing environment!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.1 - nodes decommissioning here:
Related blog posts:
- What's new in Apache Spark 3.1.1 - new built-in functions
- What's new in Apache Spark 3.1 - JDBC (WIP) and DataSource V2 API
- What's new in Apache Spark 3.1 - Kubernetes Generally Available!
- What's new in Apache Spark 3.1 - predicate pushdown for JSON, CSV and Apache Avro
- What's new in Apache Spark 3.1 - Project Zen
What can help build scalable pipelines in #ApacheSpark ? Kubernetes, cloud, but also the new feature I described in today's blog post, the node decommissioning ? https://t.co/VxthG6mn4A
— Bartosz Konieczny (@waitingforcode) April 17, 2021