
I still have 2 topics remaining in my "What's new..." backlog. I'd like to share the first of them with you today, and see what changed for Apache Parquet and Apache Avro data sources.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Datetime rebasing in read options
In the first feature of the list, Maxim Gekk extended the datetime rebasing options to Apache Avro and Apache Parquet data sources.
Apache Spark 3.0 changed the hybrid Julian+Gregorian calendar to a more standardized Proleptic Gregorian Calendar. At this occasion, the framework also got the spark.sql.legacy.(parquet|avro).datetimeRebaseModeInRead configuration property to keep the backward compatibility (although, it was also possible to fail the reader by setting the "exception" value).
However, the rebase option was available globally, at the SparkSession level. Starting fro, Apache Spark 3.2.0, you can use it locally, at a data source level:
val exceptionMode = intercept[SparkException] {
sparkSession.read.format("parquet").option("datetimeRebaseMode", "EXCEPTION")
.load("/tmp/spark245-input").show(false)
}
exceptionMode.getMessage should include("You may get a different result due to the upgrading of Spark 3.0: \nreading dates before 1582-10-15 or timestamps before 1900-01-01T00:00:00Z from Parquet INT96\nfiles can be ambiguous, as the files may be written by Spark 2.x or legacy versions of\nHive, which uses a legacy hybrid calendar that is different from Spark 3.0+'s Proleptic\nGregorian calendar. See more details in SPARK-31404.")
// Same SparkSession but a different rebase mode for this reader
sparkSession.read.format("parquet").option("datetimeRebaseMode", "LEGACY")
.load("/tmp/spark245-input").count() shouldEqual 1
Column indexes in Parquet
Column indexes aren't new in Apache Parquet, but Apache Spark hasn't supported them in the vectorized reader. At first glance, it sounds like huge work involving many code changes. However, it happens that implementing the column indexes support for that reader was "just" the matter of using an appropriate method from Apache Parquet dependency!
In the previous versions the Parquet vectorized reader was using the readNextRowGroup function that simply reads everything from the row group. Starting from 3.2.0, the reader uses readNextFilteredRowGroup that can skip pages not matching the filter:
public class ParquetFileReader implements Closeable {
// ...
/**
* Reads all the columns requested from the row group at the current file position. It may skip specific pages based
* on the column indexes according to the actual filter. As the rows are not aligned among the pages of the different
* columns row synchronization might be required. See the documentation of the class SynchronizingColumnReader for
* details.
*
* @return the PageReadStore which can provide PageReaders for each column
* @throws IOException
* if any I/O error occurs while reading
*/
public PageReadStore readNextFilteredRowGroup() throws IOException {
// ...
/**
* Reads all the columns requested from the row group at the current file position.
* @throws IOException if an error occurs while reading
* @return the PageReadStore which can provide PageReaders for each column.
*/
public PageReadStore readNextRowGroup() throws IOException {
It can then be a great performance booster for the data sources using the vectorized reader. How? Let's recall some storage details of Apache Parquet. The following schema shows the main storage components of an Apache Parquet file:
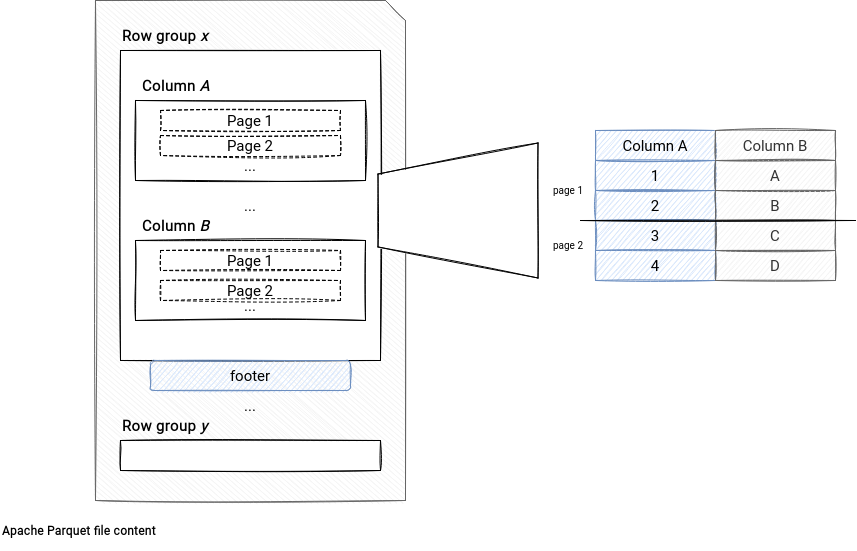
A file is composed of row groups. Each row group stores the information for the columns in pages. There is also a footer containing the column index. The index contains row pages statistics that the data reader can use to skip reading pages irrelevant for the filter expression. It reduces then the I/O effort and according to the benchmark added by Yuming Wang, it optimized some queries more than x10!
Predicate pushdown in Parquet
Besides the vectorized reader improvement, Apache Parquet also got a better support for predicate pushdown filters of the IN clause. When it comes to the queries involving this predicate, Apache Spark will transform the included values to a set of OR statements. However, the number of statements is limited by the spark.sql.parquet.pushdown.inFilterThreshold configuration entry (defaults to 10). Because of that, the queries like WHERE x IN (2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22) weren't pushed down.
Starting from Apache Spark 3.2.0, such filters will be pushed down to the data source as a WHERE x >= 2 AND <= 22 condition. You can check the logic in ParquetFilters (example for long type but the logic is the same for the others):
private val makeInPredicate:
PartialFunction[ParquetSchemaType,
(Array[String], Array[Any], ParquetStatistics[_]) => FilterPredicate] = {
// …
case ParquetLongType =>
(n: Array[String], v: Array[Any], statistics: ParquetStatistics[_]) =>
v.map(_.asInstanceOf[JLong]).foreach(statistics.updateStats(_))
FilterApi.and(
FilterApi.gtEq(longColumn(n), statistics.genericGetMin().asInstanceOf[JLong]),
FilterApi.ltEq(longColumn(n), statistics.genericGetMax().asInstanceOf[JLong]))
Schema in Avro
To terminate this blog post, let's see 2 changes impacting schemas in Apache Avro data source. The first of them was authored by Ohad Raviv and it adds a possibility to define the Avro schema as a file. To do so, you have to use the source option called avroSchemaUrl, like in the example below:
val schemaPath = getClass.getResource("/user_avro_schema.avsc").getPath
val schema = new Schema.Parser().parse(new File(schemaPath))
val user1 = new GenericRecordBuilder(schema)
.set("first_name", "Bartosz")
.set("age", 34)
.build()
val avroWriter = new DataFileWriter(new GenericDatumWriter[GenericRecord](schema))
avroWriter.create(schema, new File("/tmp/users.avro"))
avroWriter.append(user1)
avroWriter.close()
val schemaPathWithInvalidField = getClass.getResource("/user_avro_schema_invalid.avsc").getPath
val sparkSession = SparkSession.builder()
.appName("SPARK-34416 : Avro schema at reading").master("local[*]")
.getOrCreate()
// The test should fail meaning that we correctly loaded the Avro schema from the file
val error = intercept[SparkException] {
sparkSession.read.option("avroSchemaUrl", schemaPathWithInvalidField).format("avro").load("/tmp/users.avro")
.show(false)
}
error.getMessage should include("Found user, expecting user, missing required field some_age")
The second evolution comes from Erik Krogen and adds an option to configure the schema matching between Apache Avro and Apache Spark. By default, the matching uses field names but if the new property called positionalFieldMatching is turned on, the matching will become position-based. You can see a comparison of these 2 approaches in the following snippet:
val outputDir = "/tmp/avro-position-schema"
(0 to 5).map(nr => (nr, s"nr=${nr}")).toDF("id", "label")
.write.format("avro").mode(SaveMode.Overwrite).save(outputDir)
val schemaOnRead = new StructType().add("label", IntegerType).add("id", StringType)
val positionBasedRows = sparkSession.read.schema(schemaOnRead).option("positionalFieldMatching", true)
.format("avro").load(outputDir).map(row => s"${row.getAs[Int]("label")}=${row.getAs[String]("id")}")
.collect()
positionBasedRows should contain allOf("0=nr=0", "1=nr=1", "2=nr=2", "3=nr=3", "4=nr=4", "5=nr=5")
val schemaError = intercept[SparkException] {
sparkSession.read.schema(schemaOnRead).option("positionalFieldMatching", false)
.format("avro").load(outputDir).show(false)
}
schemaError.getMessage should include(
"""IncompatibleSchemaException: Cannot convert Avro type {"type":"record","name":"topLevelRecord","fields":[{"name":"id","type":"int"},{"name":"label","type":["string","null"]}]} to SQL type STRUCT<`label`: INT, `id`: STRING>.""")
That's the end of this blog post but not the end of my Apache Spark 3.2.0 exploration. Next week I'll share with you some features I could categorize in dedicated articles!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.2.0 - Apache Parquet and Apache Avro improvements here:
- Support parquet datasource options to control datetime rebasing in read Support Avro datasource options to control datetime rebasing in read ColumnIndex Layout to Support Page Skipping Parquet support Column indexes Improve in filter pushdown for ParquetFilters Support avroSchemaUrl in addition to avroSchema Support configurable Avro schema field matching for positional or by-name
Related blog posts:
- What's new in Apache Spark 3.2.0 - miscellaneous changes
- What's new in Apache Spark 3.2.0 - performance optimizations
- What's new in Apache Spark 3.2.0 - PySpark and Pandas
- What's new in Apache Spark 3.2.0 - Data Source V2
- What's new in Apache Spark 3.2.0 - push-based shuffle
A bit late this time but I was offline last weekend, for real! The first blog post from " What's new in #ApacheSpark " series covers the changes in Apache Parquet and Apache Avro connectors ? https://t.co/exCicluqvD
— Bartosz Konieczny (@waitingforcode) December 20, 2021