
In the previous Apache Spark releases you could see many shuffle evolutions such as shuffle files tracking or pluggable storage interface. And the things don't change for 3.2.0 which comes with the push-based merge shuffle.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Why
The main reason behind this new feature is the optimization for really Big Data shuffle scenarios, such as shuffle blocks of TBs or even PBs of size. This volume doesn't only apply to big shuffle files but also a lot of small shuffle files impacting the disk throughput. The feature is not there to replace the classical sort-based shuffle but rather to complement it with this additional optimization for these challenging workloads.
To address the issue, the LinkedIn engineers (Chandni Singh, Min Shen, Minchu Yang, Mridul Muralidharan, Venkata krishnan Sowrirajan, Ye Zhou,) proposed a design doc implementing shuffle merge on remote shuffle services. So the push character of the shuffle means sending shuffle blocks for merging rather than sending shuffle blocks as it to the reducers.
To understand the push-based shuffle, I divided the article into 5 sections. I tried to write them in order of execution. That's why, it'll start by the shuffle mapper stage (shuffle writing) and terminate with the shuffle reducer stage (shuffle reading).
Shuffle service nodes
The central coordination class for the shuffle push is DAGScheduler. Before creating a shuffle map stage, it checks the conditions required to use the shuffle push, so:
- the spark.shuffle.push.enabled turned on (false by default)
- the spark.shuffle.service.enabled turned on (false by default)
- the resource manager - only YARN is supported so far
- the serializer supports objects relocation - it holds for UnsafeRowSerializer and KryoSerializer with auto-reset property
- the spark.io.encryption.enabled turned off (false by default)
- the shuffle RDD doesn't work in barrier mode
If all these conditions are met, DAGScheduler prepares shuffle stage by:
- asking the resource manager backend for the list of executors available for being shuffle merge services. The communication consists of sending a GetShufflePushMergerLocations message to the master node block manager (the BlockManagerMasterEndpoint class). If the number of active executors is lower than the number of targeted mergers, the block manager might use any of past executors, up to 500 (default value of the spark.shuffle.push.maxRetainedMergerLocations)
- upon returning the available nodes for hosting the merge shuffle service, DAGScheduler records them in the ShuffleDependency mergerLocs attribute. Apart from this attribute, ShuffleDependency also has a field enabling the shuffle merge feature called shuffleMergeEnabled.
Mapper tasks
At first glance, shuffle mapper tasks don't change. They still generate the data and index shuffle files. However, to support the shuffle merge feature their ShuffleWriteProcessors got extended by this part:
if (dep.shuffleMergeEnabled && dep.getMergerLocs.nonEmpty && !dep.shuffleMergeFinalized) {
manager.shuffleBlockResolver match {
case resolver: IndexShuffleBlockResolver =>
val dataFile = resolver.getDataFile(dep.shuffleId, mapId)
new ShuffleBlockPusher(SparkEnv.get.conf)
.initiateBlockPush(dataFile, writer.getPartitionLengths(), dep, partition.index)
case _ =>
}
}
As you can see, an instance of ShuffleBlockPusher gets created and its initiateBlockPush method called. Inside the method, the pusher creates shuffle merger requests by taking continuous blocks of shuffle data. You'll find the continuity represented in the following snippet by the mergerId variable:
for (reduceId <- 0 until numPartitions) {
// ...
val mergerId = math.min(math.floor(reduceId * 1.0 / numPartitions * numMergers),
numMergers - 1).asInstanceOf[Int]
As long as the mergerId is the same and the throughput conditions are respected (max request size, max in-flight requests for the executor), the pusher continues to add the shuffle blocks to the merged process. If one of these conditions is broken, the pusher creates a new push request and accumulates the data inside it as previously.
After the creation of the requests, the pusher randomizes their order and delivers to the shuffle server via ExternalBlockStoreClient's pushBlocks method. Under-the-hood, the client initializes an instance of OneForOneBlockPusher that sends one reducer's data at a time with the following extra attributes:
public PushBlockStream(
String appId, int appAttemptId,
int shuffleId,
int shuffleMergeId,
int mapIndex, int reduceId,
int index)
Merge
Shuffle service then gets the aforementioned metadata with the corresponding shuffle data. In the merge process, the ExternalBlockHandler manipulates the request in the receiveStream method. It passes the push message to the RemoteBlockPushResolver's receiveBlockDataAsStream that appends the shuffle data to the merged data file for the reducer. But as you can notice in the image just below, the data file is not alone:
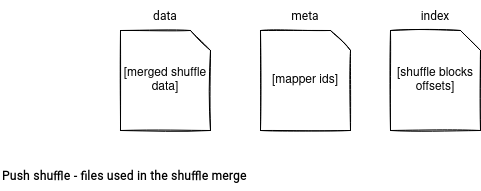
Besides the data file, the merger also has an index and a meta file. In the former one it stores the offsets of the written data whereas in the latter, it persists the indices of the map tasks which performed the successful merge operation.
A successful merge operation takes place when:
- it's allowed - at any given time, only one map stream for a given reducer can be merged with existing files. It's the allowedToWrite method from PushBlockStreamCallback.
- it's unique - a duplicated reducer data can be sent for example from a speculative task execution. It's the isDuplicateBlock method from PushBlockStreamCallback.
- it's on time - the merge won't happen if the shuffle map task terminated (= reducers started). It's the isTooLate method from PushBlockStreamCallback.
- it's not stale - this error can happen with indeterminate stage retries. It's the isStale method from PushBlockStreamCallback.
After adding the shuffle bytes to the data file, the merger writes first the merged offset to the index file and only later adds the mapper information to the meta file. Why this order? The reader reads first the index file to get the total length to fetch and only later it gets the map ids from the meta file. The reader uses these 2 attributes to create fetch requests:
private class PushBasedFetchHelper
// ...
def createChunkBlockInfosFromMetaResponse(
shuffleId: Int, shuffleMergeId: Int,
reduceId: Int, blockSize: Long,
bitmaps: Array[RoaringBitmap]): ArrayBuffer[(BlockId, Long, Int)] = {
val approxChunkSize = blockSize / bitmaps.length
val blocksToFetch = new ArrayBuffer[(BlockId, Long, Int)]()
for (i <- bitmaps.indices) {
val blockChunkId = ShuffleBlockChunkId(shuffleId, shuffleMergeId, reduceId, i)
chunksMetaMap.put(blockChunkId, bitmaps(i))
logDebug(s"adding block chunk $blockChunkId of size $approxChunkSize")
blocksToFetch += ((blockChunkId, approxChunkSize, SHUFFLE_PUSH_MAP_ID))
}
blocksToFet
But since it's a more reading-related part, I will continue with the writing before covering it in more detail.
Finalization
The writing part ends when DAGScheduler gets the notification about the last mapper task executed. It then sends a FinalizeShuffleMerge message to all shuffle services. The services intercept the message and from the MergerShuffleFileManager finalize the merge process. Any in progress merge is then interrupted and cancelled to avoid having partial data in the merged files.
DAGScheduler waits spark.shuffle.push.result.timeout to get the responses. If the shuffle service responds within this delay, the DAGScheduler intercepts the response containing the following attributes:
public class MergeStatuses extends BlockTransferMessage {
/** Shuffle ID **/
public final int shuffleId;
/**
* shuffleMergeId is used to uniquely identify merging process of shuffle by
* an indeterminate stage attempt.
*/
public final int shuffleMergeId;
/**
* Array of bitmaps tracking the set of mapper partition blocks merged for each
* reducer partition
*/
public final RoaringBitmap[] bitmaps;
/** Array of reducer IDs **/
public final int[] reduceIds;
/**
* Array of merged shuffle partition block size. Each represents the total size of all
* merged shuffle partition blocks for one reducer partition.
* **/
public final long[] sizes;
DAGScheduler registers this information by sending it to the master map output tracker so that the tracker keeps a single source of truth for the merged blocks and their locations.
Passed the spark.shuffle.push.result.timeout delay, it sends the ShuffleMergeFinalized to its internal event loop and handles the message by triggering the reducer's stage.
Reducer
On the reducer side you'll also find similar classes to the not-merged shuffle scenario. So, everything will start with SortShuffleManager and its getReader method. Inside you'll see the call to MapOutputTracker's getPushBasedShuffleMapSizesByExecutorId. The method name is quite self-explanatory because it returns the information about the shuffle blocks to fetch for the given shuffle partition. And these blocks can be one of these 2 types (ids):
- ShuffleMergedBlockId - covers the shuffle merge scenario. Besides the shuffle id and reduce id, it contains the shuffle merge id attribute. It's one of the required information to read the merged blocks.
- ShuffleBlockId - for the scenario where the mapper couldn't merge the shuffle block.
The blocks are later transferred as parameter to ShuffleBlockFetchIterator. The iterator uses this information to build a correct type of the block fetch requests.The difference between a normal and a merged fetch? The highlighted attribute (I omit here the batch fetch even though it's a second different attribute, but is less relevant than the highlighted one):
case ShuffleMergedBlockId(_, _, _) =>
if (curBlocks.size >= maxBlocksInFlightPerAddress) {
curBlocks = createFetchRequests(curBlocks.toSeq, address, isLast = false,
collectedRemoteRequests, enableBatchFetch = false, forMergedMetas = true )
}
case _ =>
// For batch fetch, the actual block in flight should count for merged block.
val mayExceedsMaxBlocks = !doBatchFetch && curBlocks.size >= maxBlocksInFlightPerAddress
if (curRequestSize >= targetRemoteRequestSize || mayExceedsMaxBlocks) {
curBlocks = createFetchRequests(curBlocks.toSeq, address, isLast = false,
collectedRemoteRequests, doBatchFetch)
curRequestSize = curBlocks.map(_.size).sum
}
The meta attribute is set to the fetch request and depending on its value, the iterator will send the shuffle data request (meta is false) or the shuffle meta file request:
def send(remoteAddress: BlockManagerId, request: FetchRequest): Unit = {
if (request.forMergedMetas) {
pushBasedFetchHelper.sendFetchMergedStatusRequest(request)
} else {
sendRequest(request)
}
numBlocksInFlightPerAddress(remoteAddress) =
numBlocksInFlightPerAddress.getOrElse(remoteAddress, 0) + request.blocks.size
}
The meta fetch request returns the following object:
case class PushMergedRemoteMetaFetchResult( shuffleId: Int, shuffleMergeId: Int, reduceId: Int, blockSize: Long, bitmaps: Array[RoaringBitmap], address: BlockManagerId)
As you can notice, the data is not there because it's only the metadata information. When the ShuffleBlockFetcherIterator meets the responses of that type, it uses it to create yet another request, this time to fetch the shuffle data blocks:
case PushMergedRemoteMetaFetchResult(
shuffleId, shuffleMergeId, reduceId, blockSize, bitmaps, address) =>
// ...
val blocksToFetch = pushBasedFetchHelper.createChunkBlockInfosFromMetaResponse(
shuffleId, shuffleMergeId, reduceId, blockSize, bitmaps)
val additionalRemoteReqs = new ArrayBuffer[FetchRequest]
collectFetchRequests(address, blocksToFetch.toSeq, additionalRemoteReqs)
fetchRequests ++= additionalRemoteReqs
// Set result to null to force another iteration.
result = null
This time, the block id is of ShuffleBlockChunkId type meaning that the request type will not have the meta flag set to true. Put another way, this time it will download the shuffle data from the shuffle service:
blockId match {
case ShuffleBlockChunkId(_, _, _, _) =>
if (curRequestSize >= targetRemoteRequestSize ||
curBlocks.size >= maxBlocksInFlightPerAddress) {
curBlocks = createFetchRequests(curBlocks.toSeq, address, isLast = false,
collectedRemoteRequests, enableBatchFetch = false)
curRequestSize = curBlocks.map(_.size).sum
}
The aforementioned logic concerns the remote shuffle fetch. For the locally merged shuffles the logic is easier. The local data has the same properties as remote but it's represented by a different class (PushMergedLocalMetaFetchResult). Instead of sending a request, it simply uses the merge metadata to load shuffle blocks from the local disk:
case PushMergedLocalMetaFetchResult(
shuffleId, shuffleMergeId, reduceId, bitmaps, localDirs) =>
// Fetch push-merged-local shuffle block data as multiple shuffle chunks
val shuffleBlockId = ShuffleMergedBlockId(shuffleId, shuffleMergeId, reduceId)
try {
val bufs: Seq[ManagedBuffer] = blockManager.getLocalMergedBlockData(shuffleBlockId,
localDirs)
Sure, push-based shuffle was designed with the goal to optimize huge shuffle exchanges. It's only supported by YARN resource manager but despite that, it's an interesting addition to the continuously evolving shuffle component.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.2.0 - push-based shuffle here:
Related blog posts:
- What's new in Apache Spark 3.2.0 - miscellaneous changes
- What's new in Apache Spark 3.2.0 - Apache Parquet and Apache Avro improvements
- What's new in Apache Spark 3.2.0 - performance optimizations
- What's new in Apache Spark 3.2.0 - PySpark and Pandas
- What's new in Apache Spark 3.2.0 - Data Source V2
Push-based shuffle in #ApacheSpark ? Yes, it's a new feature of the 3.2.0 version. If you want to learn some implementation details, I explained them in the new blog post ? https://t.co/OHhwPv92m4
— Bartosz Konieczny (@waitingforcode) November 20, 2021