
Apache Spark 3.0 extended the static execution engine with a runtime optimization engine called Adaptive Query Execution. It has changed a lot since the very first release and so even in the most recent version! But AQE is not a single performance improvement and I hope you'll see this in the blog post!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Limits pushdown
I'll start the article with the limit operation optimizations. In the first evolution, Yuming Wang optimized the LEFT OUTER JOIN query with a LIMIT. Previously, the limit was applied only after performing the join whereas it's not necessary. It can be set first locally on the left side to reduce the volume of data to join.
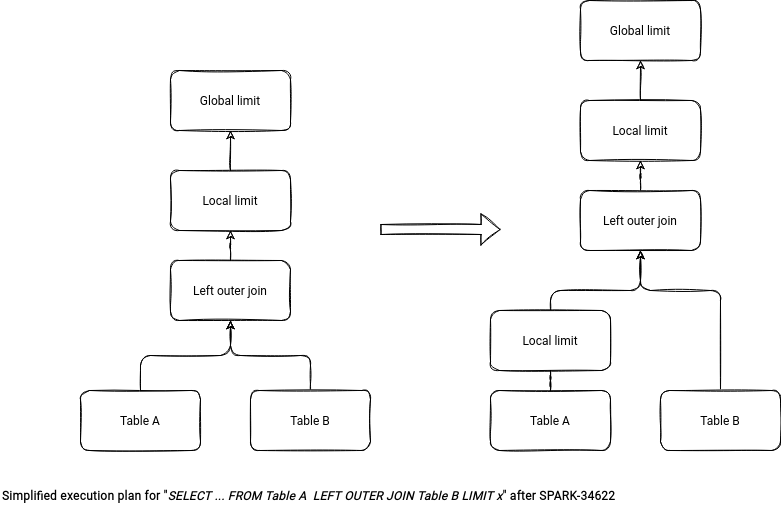
Cheng Su implemented a similar optimization but this time for LEFT SEMI and LEFT ANI joins. The push down applies the local limit operation to the left side if there is no join condition specified. The optimization relies on the semantics of these joins which are:
- return left side if the right side is non-empty (LEFT SEMI JOIN)
- return left side if the right side is empty (LEFT ANTI JOIN)
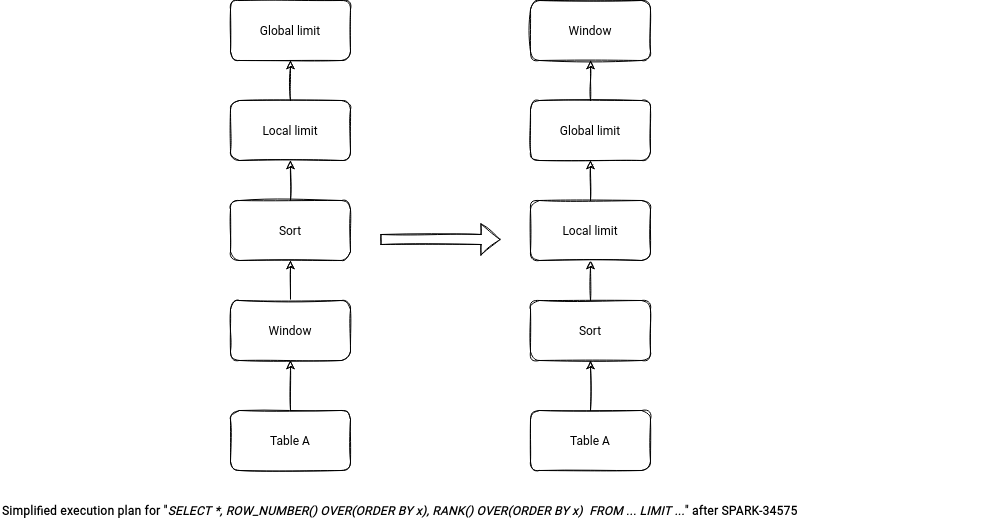
To terminate, Yuming Wang also improved the limit in the context of a WINDOW without partition specification. He added a logical optimization rule class called LimitPushDownThroughWindow that will apply the limit directly on the input table. Previously, the query like SELECT *, ROW_NUMBER() OVER(ORDER BY col1) AS row_nr FROM input_table LIMIT 10 had been applying the limit on the window generation (so full table scan). Thanks to the optimization, the query is going to be transformed to SELECT *, ROW_NUMBER() OVER(ORDER BY col1) AS row_nr FROM (SELECT * FROM input_table ORDER BY col1 LIMIT 10).
Joins
The limit improvements aren't the single ones impacting joins. Yuming Wang detected some performance issues with the queries involving joins and aggregates. The LEFT SEMI and LEFT ANTI joins will only be used in the execution plan if Spark can plan them as broadcast hash joins.
The second joins-related feature was authored by Cheng Su. Thanks to it, all join types of sort-merge join support code generation. According to the micro-benchmarks associated with the Pull Requests, the code generation can improve the queries execution by 10-30%.
In addition to the classical runtime, the joins also changed for the Adaptive Query Execution engine. To start, XiDuo Yi added a dedicated configuration option for broadcast joins in the AQE. The configuration for the AQE-optimized plans is spark.sql.adaptive.autoBroadcastJoinThreshold. The goal of this new parameter is to make a distinction between compiled and runtime execution because the former often deals with less accurate statistics. On that field too, the change adds a new isRuntime attribute to Statistics class to mark them as coming from the AQE.
This isRuntime flag is used in another change targeting shuffled hash join usage. Before, the formula used to determine the join type (shuffle or sort-merge) didn't work well because of the dynamic number of shuffle partitions. The new condition uses the runtime statistics and a new threshold configured in spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold:
object DynamicJoinSelection extends Rule[LogicalPlan] {
private def preferShuffledHashJoin(mapStats: MapOutputStatistics): Boolean = {
val maxShuffledHashJoinLocalMapThreshold =
conf.getConf(SQLConf.ADAPTIVE_MAX_SHUFFLE_HASH_JOIN_LOCAL_MAP_THRESHOLD)
val advisoryPartitionSize = conf.getConf(SQLConf.ADVISORY_PARTITION_SIZE_IN_BYTES)
advisoryPartitionSize <= maxShuffledHashJoinLocalMapThreshold &&
mapStats.bytesByPartitionId.forall(_ <= maxShuffledHashJoinLocalMapThreshold)
}
XiDuo You, the author of the above change, also renamed the DemoteBroadcastHashJoin rule to the DynamicJoinSelection and also added an internal hint called PREFER_SHUFFLE_HASH. The hint informs the AQE engine that it should use the shuffle hash join in the plan.
Another AQE-related improvement reorders the skew join and shuffle partitions coalesce in the optimization rules list. The author, Wenchen Fan, found out that the coalescing was applied before the skew join and since reasoning about skew on the coalesced partitions is more challenging, he reversed the order.
To terminate the AQE part, Ke Jia introduced Dynamic Partition Pruning support in the adaptive engine for broadcast hash joins with the PlanAdaptiveDynamicPruningFilters rule.
Broadcast nested loop join
Since the broadcast nested loop join got its umbrella ticket on JIRA, I decided to cover the changes in a separate part. In the first improvement, Cheng Su added the code generation support for INNERand CROSS joins. And it seems to be a big performance enabler because the micro-benchmark associated with the Pull Request shows the execution time decrease from ~ 60000 to 30000 milliseconds!
Later on, Cheng Su continued his effort on the code generation and added the support for LEFT SEMI and LEFT ANTI joins. Besides, he has been helped by Zebing Lin in extending the code generation to the LEFT OUTER and RIGHT OUTER joins. All these changes have a noticeable impact on the execution of the benchmarked queries.
Cheng Su is also the author of the next BNLP-related change. He found that the output and ordering weren't preserved for this join type. But having them could prevent some shuffle in case of queries involving other shuffle-operations than the join, like aggregates. This extra shuffle exchange can be then removed if the partitioning on the streamed (!= not broadcasted) side is preserved.
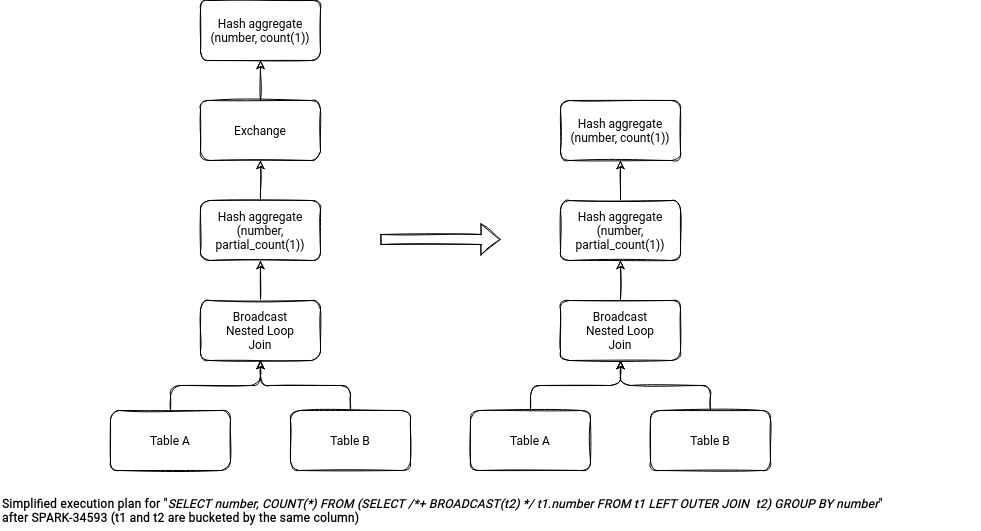
Finally, Cheng Su also optimized the query executions for LEFT ANTI and LEFT SEMI joins. Previously, when the query didn't have the join condition, the execution engine would iterate every row from the broadcast side and try to find the match. After this change, since there is no join condition, it's enough to check the emptiness of the streamed side.
Writing logic
The next change closes the joins chapter because it tends to optimize output files generation. The feature called hash-based output writers was implemented by Cheng Su to avoid local sorting before generating the partitioned or bucketed files. If you're looking for more details on this sort-based logic, you should find them in Apache Spark SQL partitionBy - shuffle or not to shuffle?.
So now, instead of sorting data before writing, Apache Spark can also keep the mapping between the partition/bucket output writer and the file. This new writing mode is not enabled by default, though. It has to be explicitly turned on by setting the spark.sql.maxConcurrentOutputFileWriters value to more than 0. This property also defines the maximal number of opened files in the mapping. Once reached, the writer will fall back to the sort-based writing mode for the remaining entries.
In addition to the output writers part, the Adaptive Query Execution got some interesting hint called REBALANCE. XiDuo Yi added this hint to deal with the too small/too big output files problems in the sink. As an outcome, you should get output partitions of a reasonable size. It does that by adding an extra shuffle stage to the plan, depending on the rebalance version (columns vs. no columns present in the hint):
object BasicOperators extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
//...
case r: logical.RebalancePartitions =>
val shuffleOrigin = if (r.partitionExpressions.isEmpty) {
REBALANCE_PARTITIONS_BY_NONE
} else {
REBALANCE_PARTITIONS_BY_COL
}
exchange.ShuffleExchangeExec(r.partitioning, planLater(r.child), shuffleOrigin) :: Nil
Statistics
Statistics are the next improved part impacting the final performances of the job. Yuming Wang found out that the PruneFileSourcePartitions logical rule was removing all advanced statistics like number of rows. Because of that, some of the queries that could have been planned as broadcast join, were planned as more expensive sort-merge joins. It shouldn't be the case in Apache Spark 3.2.0 anymore.
Besides the pruning stats, the Cost-Based Optimization layer also got some interesting improvements. Ayushi Agarwal added cardinality estimation for the union, sort and range operations. The union now provides the number of rows with min and max stats per column. The sort operation inherits children's stats, whereas the range data comes from the range operation itself and is computed from start, end and step params.
In the second CBO optimization Tanel Kiis improved the cost optimization function. The previous implementation implied a symmetry between the costs: {plan A}.betterThan({plan B}) implies !{plan B}.betterThan({plan A}). However, the change was not beneficial for all type of queries and Apache Spark 3.2.0 improved that with the following formula:
object JoinReorderDP extends PredicateHelper with Logging {
// ...
def betterThan(other: JoinPlan, conf: SQLConf): Boolean = {
// ...
val relativeRows = BigDecimal(this.planCost.card) / BigDecimal(other.planCost.card)
val relativeSize = BigDecimal(this.planCost.size) / BigDecimal(other.planCost.size)
Math.pow(relativeRows.doubleValue, conf.joinReorderCardWeight) *
Math.pow(relativeSize.doubleValue, 1 - conf.joinReorderCardWeight) < 1
}
The new formula avoids overwhelming risk present in the initial version, mentioned in the PullRequest:
Originally A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1 was used. Besides being "non-symteric", this also can exhibit one overwhelming other.
For w=0.5 If A size (bytes) is at least 2x larger than B, then no matter how many times more rows does the B plan have, B will allways be considered to be better - 0.5*2 + 0.5*0.00000000000001 > 1.
To terminate this part, Cheng Su added a CostEvaluator interface that can be used to define a custom evaluator for the Adaptive Query Execution engine. Currently, the feature was quite surprising for me at first glance. The AQE is supposed to be smart enough to adapt the query at runtime, isn't it? Yes, but the AQE behavior may also depend on the production environment. Cheng Su quotes its context at Facebook where they use a custom remote shuffle service called Cosco requiring a different cost model.
Misc
To terminate this already quite long blog post, let's see the remaining changes. Dongjoon Hyun changed the status of the Adaptive Query Execution. From now it's enabled by default! To disable it, you have to explicitly set the spark.sql.adaptive.enabled property to false.
In his second contribution, Dongjoon Huyn, alongside Yuming Wang, worked on improving the ZStandard compression codec integration with Apache Spark. The new release includes a lot of dependency versions fixes and performance improvement with the buffer pool of ZSTD JNI library enabled by default.
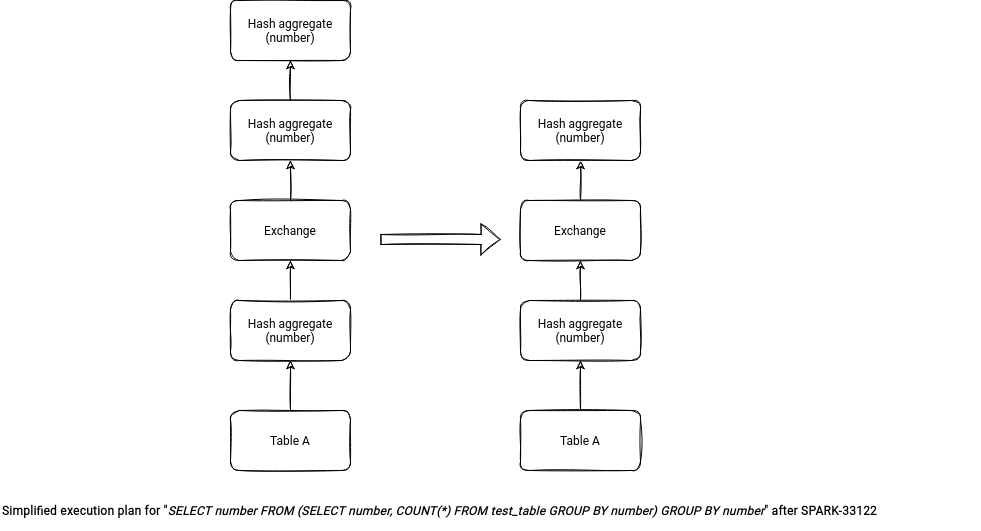
Besides the ZStandard improved, the new Apache Spark also gots a new optimization rule called RemoveRedundantAggregates. Added by Tanel Kiis, the rule removes a redundant aggregates. It applies when one of 2 aggregates is there to keep only distinct values.
As you can see, Apache Spark 3.2.0 brought a few interesting optimizations that maybe will speed up your queries?.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.2.0 - performance optimizations here:
- Push down limit through Project Push down limit for LEFT SEMI and LEFT ANTI join Push down limit through window when partitionSpec is empty [SQL] Allow FileFormatWriter to write multiple partitions/buckets without sort Add a new operator to distingush if AQE can optimize safely Keep necessary stats after partition pruning Cardinality estimation of union, range and sort logical operators Use better CBO cost function Allow custom plugin for AQE cost evaluator Enable spark.sql.adaptive.enabled true by default Improve ZSTD support Remove redundant aggregates in the Optimzier Broadcast nested loop join improvement Support DPP in AQE When the join is Broadcast hash join before applying the AQE rules Only push down LeftSemi/LeftAnti over Aggregate if join can be planned as broadcast join Add code-gen for all join types of sort-merge join Support AQE side broadcast hash join threshold Support AQE side shuffled hash join formula using rule Optimize skew join before coalescing shuffle partitions
Related blog posts:
- What's new in Apache Spark 3.2.0 - miscellaneous changes
- What's new in Apache Spark 3.2.0 - Apache Parquet and Apache Avro improvements
- What's new in Apache Spark 3.2.0 - PySpark and Pandas
- What's new in Apache Spark 3.2.0 - Data Source V2
- What's new in Apache Spark 3.2.0 - push-based shuffle
What's new in #ApacheSpark 3.2.0 from the performance point of view? That's the topic of the new blog post you'll find here ? https://t.co/3lnfvKiZ8t
— Bartosz Konieczny (@waitingforcode) December 11, 2021