
In my previous blog post you could learn about the Adaptive Query Execution improvement added to Apache Spark 3.0. At that moment, you learned only about the general execution flow for the adaptive queries. Today it's time to see one of possible optimizations that can happen at this moment, the shuffle partition coalesce.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Why?
Shuffle partition coalesce, and I insist on the shuffle part of the name, is the optimization whose goal is to reduce the number of reduce tasks performing the shuffle operation. Confused? Let's take an example of a JOIN operation. It's divided into 2 major operations, one that can be made locally, at the input partitions level, and here we can put the local transformations like map or filter. This operation will produce shuffle partition files that will be used by the second major operation, on the reducer side, which will be the generation of the rows output after the join.
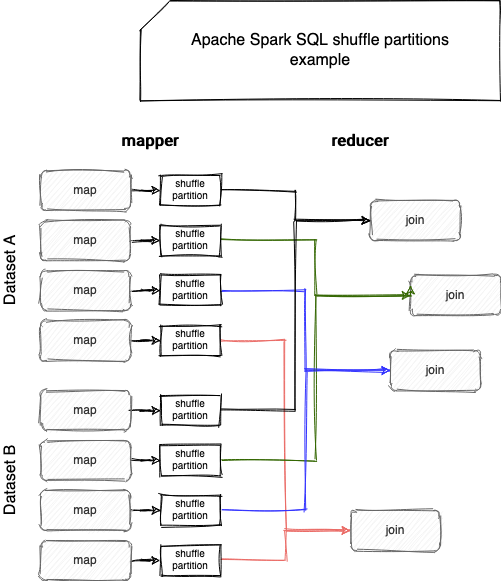
As you can see, in the schema we join 2 datasets and approximately, we can say that we have 1 task per shuffle partitions pair. The problem with this approach is that the shuffle partitions could be really small and, therefore, lead to the execution of many small tasks. And who says many small tasks, says multiple I/O operations on disk and across the network.
The goal of shuffle partitions coalesce optimization is to ... coalesce, so group multiple small partitions and expose them as a single group to the reducer task.
Configuration
To make it possible, you have to configure 4 important properties. The first of them is spark.sql.adaptive.coalescePartitions.enabled and as its name indicates, it controls whether the optimization is enabled or not.
Next to it, you can set the spark.sql.adaptive.coalescePartitions.initialPartitionNum and spark.sql.adaptive.coalescePartitions.minPartitionNum. The former one defines the initial number of shuffle partitions before coalescing:
private def defaultNumPreShufflePartitions: Int =
if (conf.adaptiveExecutionEnabled && conf.coalesceShufflePartitionsEnabled) {
conf.initialShufflePartitionNum
} else {
conf.numShufflePartitions
}
As you can see, it's only used when the AQE and shuffle partition coalesce features are enabled. If not, it fallbacks to the property you certainly know already which is spark.sql.shuffle.partitions.
Regarding minPartitionNum property, it defines the minimal number of shuffle partitions after coalesce. If not set, the default parallelism from Spark cluster (spark.default.parallelism) is used.
The last property is spark.sql.adaptive.advisoryPartitionSizeInBytes and it represents a recommended size of the shuffle partition after coalescing. This property is only a hint and can be overridden by the coalesce algorithm that you will discover just now.
Algorithm
The execution starts with some control flow verifications. The first of them is very easy to understand because it checks whether the configuration is enabled for the coalesce operation. The second one verifies another condition, namely whether all the leaf nodes are QueryStageExec operations, so either a shuffle or broadcast one. Why is it important? According to this comment, the non-respect of that can break some assumptions:
// If not all leaf nodes are query stages, it's not safe to reduce the number of
// shuffle partitions, because we may break the assumption that all children of a spark plan
// have same number of output partitions.
The 3rd check verifies whether all shuffles can have their partition numbers changed. When this property can be disabled? For example, when the user explicitly repartitions one of the shuffled datasets, which illustrates the following snippet from physical execution strategies:
case logical.Repartition(numPartitions, shuffle, child) =>
if (shuffle) {
ShuffleExchangeExec(RoundRobinPartitioning(numPartitions),
planLater(child), canChangeNumPartitions = false) :: Nil
} else {
execution.CoalesceExec(numPartitions, planLater(child)) :: Nil
}
case r: logical.RepartitionByExpression =>
exchange.ShuffleExchangeExec(
r.partitioning, planLater(r.child), canChangeNumPartitions = false) :: Nil
The last guard condition checks whether both sides have the same number of shuffle partitions. An example of this scenario is also included in the comment:
// We may have different pre-shuffle partition numbers, don't reduce shuffle partition number
// in that case. For example when we union fully aggregated data (data is arranged to a single
// partition) and a result of a SortMergeJoin (multiple partitions).
Once all these 4 conditions are met, the coalesce algorithm is applied. The algorithm uses the statistics generated by the map stage which are included in this object:
/** * Holds statistics about the output sizes in a map stage. May become a DeveloperApi in the future. * * @param shuffleId ID of the shuffle * @param bytesByPartitionId approximate number of output bytes for each map output partition * (may be inexact due to use of compressed map statuses) */ private[spark] class MapOutputStatistics(val shuffleId: Int, val bytesByPartitionId: Array[Long])
After that, the algorithm computes the minimal number of partitions that should be generated after the optimization. It uses for that spark.sql.adaptive.coalescePartitions.minPartitionNum or the cluster default parallelism. Once resolved, the coalesce algorithm is invoked:
val partitionSpecs = ShufflePartitionsUtil.coalescePartitions(
validMetrics.toArray,
advisoryTargetSize = conf.getConf(SQLConf.ADVISORY_PARTITION_SIZE_IN_BYTES),
minNumPartitions = minPartitionNum)
The coalesce operation assumes, and that also explains why we ensured before to have the same number of partition files in both datasets, that the partitions of the same index from the partitions list will be read by the same task. In other words, if dataset A and dataset B both have partitions [0, 1, 2], the algorithm assumes that [A=0, B=0], [A=1, B=1], [A=2, B=2] will be read by 3 different tasks.
Next, the coalesce algorithm iterates over all pairs (A=0, B=0), (A=1, B=1), (A=2, B=2) and verifies whether together, their size is bigger or not than the targeted size of the post-shuffle partition. If it's the case, a new CoalescedPartitionSpec is produced. If it's not the case, the iteration continues and the index of that partition will be included in one of the next CoalescedPartitionSpec:
if (i > latestSplitPoint && coalescedSize + totalSizeOfCurrentPartition > targetSize) {
partitionSpecs += CoalescedPartitionSpec(latestSplitPoint, i)
latestSplitPoint = i
// reset postShuffleInputSize.
coalescedSize = totalSizeOfCurrentPartition
} else {
coalescedSize += totalSizeOfCurrentPartition
}
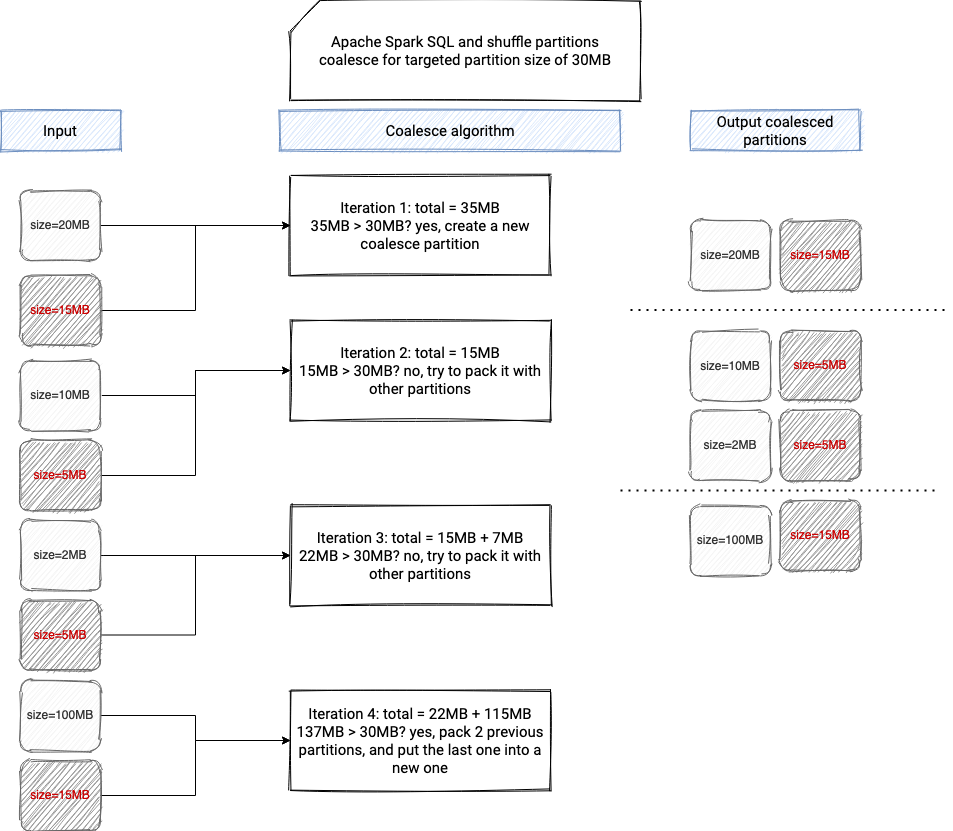
The result of this optimization is a new sequence of ShufflePartitionSpec. This sequence is later passed to the physical execution, via a new node in the plan called CustomShuffleReaderExec.
Physical execution
What happens after this reorganization step? The new node, CustomShuffleReaderExec stores the list of new partitions assignment:
case class CoalescedPartitionSpec( startReducerIndex: Int, endReducerIndex: Int) extends ShufflePartitionSpec
You can see then that every assignment has a start and end index. These ranges are used to discover what shuffle files should be fetched by every reducer step, in SortShuffleManager:
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext,
metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C] = {
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByExecutorId(
handle.shuffleId, startPartition, endPartition)
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], blocksByAddress, context, metrics,
shouldBatchFetch = canUseBatchFetch(startPartition, endPartition, context))
}
And at this moment it is worth noticing that there is another optimization for the shuffle fetch operation. In the configuration you can find spark.sql.adaptive.fetchShuffleBlocksInBatch property that by default is set to true and enables the retrieval of multiple continuous shuffle block files to reduce the I/O cost of the operation.
As you can see then, and it was my initial wrong assumption about this feature, there is no physical rewriting for the shuffle block files. The optimization is then a pure logical reorganization. At this moment I didn't explore yet the way of building shuffle blocks for the operations involving shuffle (joins, group by key,...) but the fact of mixing the pairs for the blocks for both datasets, and the requirement of having the same number of them, makes me think that pre-shuffle partitions have to contain all records for the given key in the single block file, on both sides 🤔 If you have any news about that, please leave the comment. For my side, I already added a topic to my backlog and will check that later (Thank you TheEphemeralDream for the confirmation 👍).
Examples
Below you can find the code I'm using in the demo recorded just after:
object ShufflePartitionCoalesceConfiguration {
val sparkSession = SparkSession.builder()
.appName("Spark 3.0: AQE - shuffle partitions coalesce").master("local[*]")
.config("spark.sql.adaptive.enabled", true)
.config("spark.sql.adaptive.logLevel", "TRACE")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.minPartitionNum", "2")
// Initial number of shuffle partitions
// I put a very big number to make the coalescing happen
// coalesce - about setting the right number of reducer task
.config("spark.sql.adaptive.coalescePartitions.initialPartitionNum", "100")
.config("spark.sql.adaptive.advisoryPartitionSizeInBytes", "10KB")
// Make it small enough to produce shuffle partitions
.config("spark.sql.autoBroadcastJoinThreshold", "1KB")
.getOrCreate()
import sparkSession.implicits._
val input4 = (0 to 50000).toDF("id4")
val input5 = (0 to 3000).toDF("id5")
}
object ShufflePartitionCoalesceNotAppliedAfterRepartitioning extends App {
val input5Repartitioned = input5.repartition(10)
input4.join(input5Repartitioned,
input4("id4") === input5("id5"), "inner"
).collect()
}
object ShufflePartitionCoalesceApplied extends App {
input4.join(input5,
input4("id4") === input5("id5"), "inner"
).collect()
}
Shuffle partitions coalesce is only one of the adaptive query execution optimizations. As you saw in the blog post, it helps to reduce the number of partitions, so automatically the number of tasks that will process them on the reducer side. In the next article from the series, you will learn about skewed data optimization.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.0 - shuffle partitions coalesce here:
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3.0 - GPU-aware scheduling
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - UI changes
- What's new in Apache Spark 3.0 - dynamic partition pruning
Adaptive Query Execution in #SparkSQL is a set of features that can optimize the query execution at runtime. Today it's time to discover the first of them called shuffle partitions coalesce. If you want to learn more about it ? https://t.co/K3m2pAwWuB
— Bartosz Konieczny (@waitingforcode) August 8, 2020