
GPU-awareness was one of the topics I postponed the most in my Apache Spark 3.0 exploration. But its time has come and in this blog post you will discover what changed in the version 3 of the framework regarding the GPU-based computation.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post starts with a short presentation of GPU-based computing. Before writing this article, I was not very familiar with this domain, with the "whys", "whats" and "hows" and that's why the blog post starts with some basics presentation. If it's not your case, you can skip this part. The second and third sections present the changes related to the GPU-aware scheduling added in SPARK-24615 and related tasks. Finally, the last part introduces a side project called Spark RAPIDS plugin that may put Spark pipelines directly on the GPU.
GPU-based processing 101
The difference between CPU and GPU comes mostly from the processing approach. The CPU has a few cores that are optimized for sequential processing. On the other hand, GPU has much more but smaller cores that are better suited for parallel processing. You can find a simplified comparison in an image below:
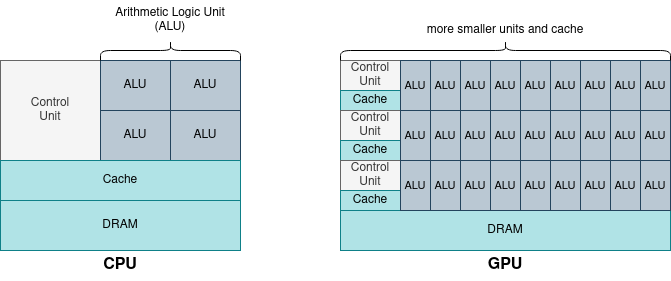
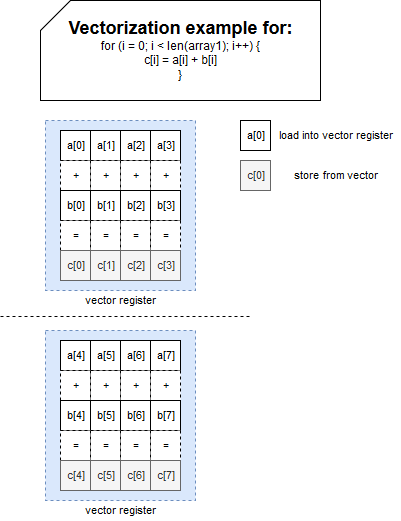
GPU will perform a way better for the workloads based on the parallel processing but CPU should still be used for short and sequential tasks. An example of the domain where the GPU performs very well is Deep Learning, and more exactly Computer Vision or Natural Language Processing. Algorithms solving these problems can be easily parallelized. And this parallelization is something you already met on the blog, more exactly in the article about vectorized operations in Apache Spark SQL:
Apart from this quite basic and high-level information, it's good to know some vocabulary. The first key term is CUDA and in simple words, it's a programming model for NVIDIA that helps to implement GPU-based programs. The applications are still written with usual low-level languages (C, C++, Fortran) but thanks to this extension, they can interact with the GPU. And if you need a high-level abstraction, you can use a framework like RAPIDS which is the second term to know.
GPU-aware scheduler - settings
Does it mean that Apache Spark 3.0 runs on top of CUDA or RAPIDS? No, but it's an interesting topic that will be covered in the last section. The feature prepared for the 3.0 release is a bit "simpler" since it's "only" a specification sent from Apache Spark to one of the supported cluster managers (YARN, Kubernetes, standalone, Mesos scheduling is still open for implementation). I put "only" and "simpler" on double quotes on purpose because if you check the work done, as well the conceptual as the coding work, you will see that it's not "only" and "simple".
The specification consists on defining the configuration entries like spark.executor.resource.gpu.amount or spark.driver.resource.gpu.amount. They will be considered as any other configuration properties and therefore, will be translated under-the-hood to the properties understandable by the given cluster manager.
For example, this translation for YARN is implemented in ResourceRequestHelper#getYarnResourcesFromSparkResources and looks like:
// ResourceUtils
final val GPU: String = "gpu"
final val FPGA: String = "fpga"
// ResourceRequestHelper
val YARN_GPU_RESOURCE_CONFIG = "yarn.io/gpu"
val YARN_FPGA_RESOURCE_CONFIG = "yarn.io/fpga"
private[yarn] def getYarnResourcesFromSparkResources(
confPrefix: String,
sparkConf: SparkConf
): Map[String, String] = {
Map(GPU -> YARN_GPU_RESOURCE_CONFIG, FPGA -> YARN_FPGA_RESOURCE_CONFIG).map {
case (rName, yarnName) =>
(yarnName -> sparkConf.get(new ResourceID(confPrefix, rName).amountConf, "0"))
}.filter { case (_, count) => count.toLong > 0 }
}
Apart from that, the GPU-aware scheduler also implements a concept of resources discovery. This aspect is controlled by the script defined in the spark.executor.resource.gpu.discoveryScript or spark.driver.resource.gpu.discoveryScript property. Some of the cluster managers won't notify Apache Spark where the resources are allocated and the discovery script helps to...well, discover them! An example of that script is nvidia-smi --query-gpu=index --format=csv,noheader that will return the GPU indexes for NVIDIA cards. The script is executed when the executor starts and it has to respect the format defined in the ResourceInformation#parseJson:
ResourceInformationJson(name: String, addresses: Seq[String])
// Example in JSON:
// {"name": "gpu", "addresses": ["0", "1"]}
GPU-aware scheduler - validation
Fine, that was for the discovery and communication parts. Does it mean that Apache Spark blindly trusts the cluster managers? No because it will perform the same requirements checks as for the CPUs expected by every task. This check looks like that:
// org.apache.spark.scheduler.TaskSchedulerImpl
private def resourceOfferSingleTaskSet(
// ...
shuffledOffers: Seq[WorkerOffer], availableCpus: Array[Int],
availableResources: Array[Map[String, Buffer[String]]],
// ...
) {
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
if (availableCpus(i) >= CPUS_PER_TASK &&
resourcesMeetTaskRequirements(availableResources(i))) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality, availableResources(i))) {
tasks(i) += task
As you can see in the snippet, the CPU comparison is quite straightforward. For the resourcesMeetTaskRequirements, the validation execution is delegated to ResourceUtils:
def resourcesMeetRequirements(
resourcesFree: Map[String, Int],
resourceRequirements: Seq[ResourceRequirement])
: Boolean = {
resourceRequirements.forall { req =>
resourcesFree.getOrElse(req.resourceName, 0) >= req.amount
}
}
If one of the required resources, like GPUs, is not available in the pool of proposed workers, the task won't be scheduled. To notice that, let's back to the TaskSchedulerImpl's resourceOffers. This method is responsible for allocating the resources to the tasks and is called by CoarseGrainedSchedulerBackend.DriverEndpoint method here:
private def makeOffers(executorId: String): Unit = {
// Make sure no executor is killed while some task is launching on it
val taskDescs = withLock {
if (isExecutorActive(executorId)) {
// ...
scheduler.resourceOffers(workOffers)
} else {
Seq.empty
}
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)
}
}
Spark RAPIDS plugin
RAPIDS for Apache Spark is a plugin that helps to execute data processing pipelines via the RAPIDS libraries on top of NVIDIA GPUs. It's currently one of the best examples I found illustrating how far you can customize the framework. RAPIDS for Apache Spark is a plugin that is activated with a simple spark.rapids.sql.enabled configuration entry and, of course, the already presented GPU-aware scheduling attributes.
The library is a set of sources, custom logical and physical rules based on the concept of Spark plugins which by the way, are another new feature in Apache Spark 3.0! The main entrypoint for RAPIDS is SQLPlugin class exposing the plugins for the driver and executors:
class SQLPlugin extends SparkPlugin with Logging {
override def driverPlugin(): DriverPlugin = new RapidsDriverPlugin
override def executorPlugin(): ExecutorPlugin = new RapidsExecutorPlugin
}
The role of the driver plugin is mostly to extend the available configuration options by adding SQLExecPlugin to the spark.sql.extensions attribute:
class SQLExecPlugin extends (SparkSessionExtensions => Unit) with Logging {
override def apply(extensions: SparkSessionExtensions): Unit = {
logWarning("Installing extensions to enable rapids GPU SQL support." +
s" To disable GPU support set `${RapidsConf.SQL_ENABLED}` to false")
extensions.injectColumnar(_ => ColumnarOverrideRules())
ShimLoader.getSparkShims.injectQueryStagePrepRule(extensions, _ => GpuQueryStagePrepOverrides())
}
}
As you can see, 2 categories of optimizations are inserted to Apache Spark plan. The first is about the columnar rules and the second about the physical plan. The customization works by wrapping the initial execution plan by one of RapidsMeta[INPUT <: BASE, BASE, OUTPUT <: BASE] implementations or by RuleNotFoundSparkPlanMeta when the plan cannot be translated to the GPU version:
val commonExecs: Map[Class[_ <: SparkPlan], ExecRule[_ <: SparkPlan]] = Seq(
// ...
exec[ProjectExec](
"The backend for most select, withColumn and dropColumn statements",
(proj, conf, p, r) => {
new SparkPlanMeta[ProjectExec](proj, conf, p, r) {
override def convertToGpu(): GpuExec =
GpuProjectExec(childExprs.map(_.convertToGpu()), childPlans(0).convertIfNeeded())
}
}),
// ...
val execs: Map[Class[_ <: SparkPlan], ExecRule[_ <: SparkPlan]] =
commonExecs ++ ShimLoader.getSparkShims.getExecs
def wrapPlan[INPUT <: SparkPlan](
plan: INPUT, conf: RapidsConf, parent: Option[RapidsMeta[_, _, _]]): SparkPlanMeta[INPUT] =
execs.get(plan.getClass)
.map(r => r.wrap(plan, conf, parent, r).asInstanceOf[SparkPlanMeta[INPUT]])
.getOrElse(new RuleNotFoundSparkPlanMeta(plan, conf, parent))
In consequence, the plan will look like that:
+- GpuProject [username#102L]
+- GpuCoalesceBatches TargetSize(20000)
+- GpuFilter ((gpuisnotnull(username#102L)))
+- GpuFileGpuScan parquet [username#102L,user_id#103] Batched: true, DataFilters: [isnotnull(username#102L)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/spark-rapids-test..., PartitionFilters: [], PushedFilters: [IsNotNull(username)], ReadSchema: struct<username:string,user_id:bigint>
Regarding the executor plugin, it's role is to perform the resource initialization on the executors. It starts a semaphore that controls the concurrent access to the GPU from the operations customized in the previous plugin. Below an example coming from CSVPartitionReader#readToTable:
private def readToTable(hasHeader: Boolean): Option[Table] = {
// ...
val cudfSchema = GpuColumnVector.from(dataSchema)
val csvOpts = buildCsvOptions(parsedOptions, newReadDataSchema, hasHeader)
// about to start using the GPU
GpuSemaphore.acquireIfNecessary(TaskContext.get())
// GpuSemaphore
object GpuSemaphore {
def acquireIfNecessary(context: TaskContext): Unit = {
if (enabled && context != null) {
getInstance.acquireIfNecessary(context)
}
private final class GpuSemaphore(tasksPerGpu: Int) extends Logging {
private val semaphore = new Semaphore(tasksPerGpu)
def acquireIfNecessary(context: TaskContext): Unit = {
val nvtxRange = new NvtxRange("Acquire GPU", NvtxColor.RED)
try {
val taskAttemptId = context.taskAttemptId()
val refs = activeTasks.get(taskAttemptId)
if (refs == null || refs.getValue == 0) {
logDebug(s"Task $taskAttemptId acquiring GPU")
semaphore.acquire()
// ...
I didn't expect to learn so much about Apache Spark and GPU. As you saw in the article, this new computing environment takes more and more place in the framework. Regarding the advancement of RAPIDS plugin, the GPU-aware scheduling presented in the 2nd and 3rd parts, seems to be just the beginning.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.0 - GPU-aware scheduling here:
- Why can GPU do matrix multiplication faster than CPU? Running Tensorflow on CPU is faster than running it on GPU [SPARK-27725][EXAMPLES] Add an example discovery Script for GPU resources #24731 What Is CUDA? Getting Started with the RAPIDS Accelerator for Apache Spark Machine learning with XGBoost gets faster with Dataproc on GPUs
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - UI changes
- What's new in Apache Spark 3.0 - dynamic partition pruning
- What's new in Apache Spark 3.0 - predicate pushdown support for nested fields
Apart from performance optimization and API extension, #ApacheSpark 3 also has few changes on the "cluster" part. To start, the GPU-aware scheduling explained in the new blog post ? https://t.co/OOy1465e79
— Bartosz Konieczny (@waitingforcode) October 24, 2020