
If you noticed that some filter expressions weren't pushed down to your Apache Parquet files, the situation should change in Apache Spark 3.0. The new release supports this feature called nested data predicate pushdown.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post you will learn a bit more about this Apache Spark 3.0 new feature, that by the way is quite old since it was first mentioned in 2016! In the first part, you will see how pushing the filters to Apache Parquet data source works. In the second one, you will discover what changes made this feature possible in the nested fields. Finally, you will see a demo of this feature in action.
Predicate pushdown in Apache Parquet
Everything starts in DataSourceScanExec (technically not really, but this "not really" part is related to the changes introduced with Apache Spark 3, so I will cover it later). This physical operator responsible for, as the name indicates, data source, has a field representing the input RDD. Inside, you can find a factory method returning the iterator for the input files, where the pushedDownFilters are set:
val readFile: (PartitionedFile) => Iterator[InternalRow] =
relation.fileFormat.buildReaderWithPartitionValues(
sparkSession = relation.sparkSession,
dataSchema = relation.dataSchema,
partitionSchema = relation.partitionSchema,
requiredSchema = requiredSchema,
filters = pushedDownFilters,
options = relation.options,
hadoopConf = relation.sparkSession.sessionState.newHadoopConfWithOptions(relation.options))
This method is later passed to one of the functions reading the data which works on bucketed and not bucketed datasets. Both return a FileScanRDD that contains our readFile function.
But wait a minute, where is Apache Parquet here? If you check again the readFile snippet, the function is constructed from a relation.fileFormat.buildReaderWithPartitionValues which is implemented by all formats supported in Apache Spark, including Apache Parquet. In the signature of this function you can see that the filters defined in the initial query are present, and for ParquetFileFormat they're used to create ParquetFilters instances:
// Try to push down filters when filter push-down is enabled.
val pushed = if (enableParquetFilterPushDown) {
val parquetSchema = footerFileMetaData.getSchema
val parquetFilters = new ParquetFilters(parquetSchema, pushDownDate, pushDownTimestamp,
pushDownDecimal, pushDownStringStartWith, pushDownInFilterThreshold, isCaseSensitive)
filters
// Collects all converted Parquet filter predicates. Notice that not all predicates can be
// converted (`ParquetFilters.createFilter` returns an `Option`). That's why a `flatMap`
// is used here.
.flatMap(parquetFilters.createFilter(_))
.reduceOption(FilterApi.and)
} else {
None
}
So built filters are later passed to Hadoop's configuration entries prefixed with parquet.private.read.filter.predicate and used by one of the available readers, VectorizedParquetRecordReader or ParquetRecordReader. Regarding the former one, it executes the filters at the initialization step that way:
footer = readFooter(configuration, file, range(split.getStart(), split.getEnd()));
MessageType fileSchema = footer.getFileMetaData().getSchema();
FilterCompat.Filter filter = getFilter(configuration);
blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
And the filtering logic is later called by RowGroupFilter that verifies whether the block should be dropped according to its statistics or the metadata of the stored columns:
List<BlockMetaData> filteredBlocks = new ArrayList<BlockMetaData>();
for (BlockMetaData block : blocks) {
boolean drop = false;
if(levels.contains(FilterLevel.STATISTICS)) {
drop = StatisticsFilter.canDrop(filterPredicate, block.getColumns());
}
if(!drop && levels.contains(FilterLevel.DICTIONARY)) {
drop = DictionaryFilter.canDrop(filterPredicate, block.getColumns(), reader.getDictionaryReader(block));
}
if(!drop) {
filteredBlocks.add(block);
}
}
return filteredBlocks;
The workflow for this scenario looks like in this diagram:
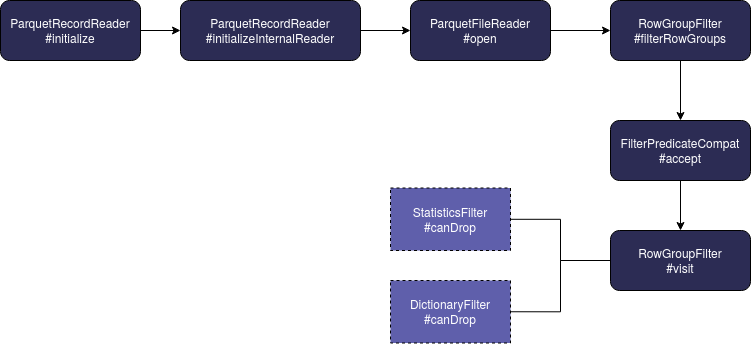
To my surprise, I didn't see any place where these filters were applied at the row level and if I'm wrong, feel free to rectify in the comments. I found an old comment of one of Parquet's integration PR. Nonetheless, if I'm right, the reason for that might come from the batch abstraction returned in the vectorized mode. Under this link you can learn more about vectorized operations in Apache Spark SQL.
But the VectorizedParquetRecordReader won't be used for the nested fields because of this check, and more exactly the resultSchema part (nested field is not atomic):
val enableVectorizedReader: Boolean =
sqlConf.parquetVectorizedReaderEnabled &&
resultSchema.forall(_.dataType.isInstanceOf[AtomicType])
Let's see then how does the filtering work on the not vectorized ParquetRecordReader. It will also use RowGroupFilter to get rid of the not matching filters but in addition to that, it will call getCurrentRecord method of FilteringRecordMaterializer where the filter expressions will be applied at the record level for the remaining column chunks:
@Override
public T getCurrentRecord() {
// find out if the predicate thinks we should keep this record
boolean keep = IncrementallyUpdatedFilterPredicateEvaluator.evaluate(filterPredicate);
// reset the stateful predicate no matter what
IncrementallyUpdatedFilterPredicateResetter.reset(filterPredicate);
if (keep) {
return delegate.getCurrentRecord();
} else {
// signals a skip
return null;
}
}
The workflow for this scenario looks like in this picture:
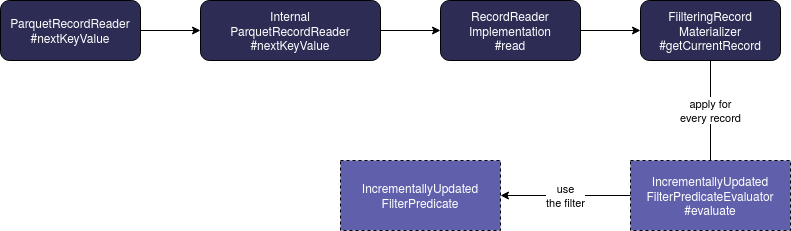
You can see then that the filtering is delegated to predicate evaluator taking as parameter an instance of IncrementallyUpdatedFilterPredicate which contains the filter expression defined at Apache Spark's level and converted meantime to Apache Parquet classes.
Nested predicates support
That was a general execution flow and before Apache Spark 3.0, it worked great for top-level fields. Starting from this new release, nested fields are supported. The first change to enable this was a new configuration entry called spark.sql.optimizer.nestedPredicatePushdown.supportedFileSources that defines a list of data sources supporting push down predicates for nested columns. And in this list you can currently file Parquet and ORC data sources. The list is later used in already mentioned pushedDownFilters attribute of DataSourceScanExec:
@transient
private lazy val pushedDownFilters = {
val supportNestedPredicatePushdown = DataSourceUtils.supportNestedPredicatePushdown(relation)
dataFilters.flatMap(DataSourceStrategy.translateFilter(_, supportNestedPredicatePushdown))
}
As you can see, this attribute is used in the function that converts the Expression filters from Apache Spark plan into corresponding Filter objects. These objects are later used in another snippet already quoted:
val parquetSchema = footerFileMetaData.getSchema
val parquetFilters = new ParquetFilters(parquetSchema, pushDownDate, pushDownTimestamp,
pushDownDecimal, pushDownStringStartWith, pushDownInFilterThreshold, isCaseSensitive)
filters
// Collects all converted Parquet filter predicates. Notice that not all predicates can be
// converted (`ParquetFilters.createFilter` returns an `Option`). That's why a `flatMap`
// is used here.
.flatMap(parquetFilters.createFilter(_))
.reduceOption(FilterApi.and)
And that's here where you can find another change. The createFilter calls a createFilterHelper which returns an optional Apache Parquet filter (None is returned if the filter can't be translated):
def createFilter(predicate: sources.Filter): Option[FilterPredicate] = {
createFilterHelper(predicate, canPartialPushDownConjuncts = true)
}
In previous version of Apache Spark, one of the methods called by createFilterHelper excluded the nested fields with this check:
private def canMakeFilterOn(name: String, value: Any): Boolean = {
nameToParquetField.contains(name) && !name.contains(".") && valueCanMakeFilterOn(name, value)
In 3.0 this method changed and also, a support for nested fields were added with a field called nameToParquetField:
// A map which contains parquet field name and data type, if predicate push down applies.
//
// Each key in `nameToParquetField` represents a column; `dots` are used as separators for
// nested columns. If any part of the names contains `dots`, it is quoted to avoid confusion.
// See `org.apache.spark.sql.connector.catalog.quote` for implementation details.
private val nameToParquetField : Map[String, ParquetPrimitiveField] = {
// ...
}
private def canMakeFilterOn(name: String, value: Any): Boolean = {
nameToParquetField.contains(name) && valueCanMakeFilterOn(name, value)
}
Demo code
Let's see how the predicate pushdown for the nested fields works in Apache Spark 3.0. Below you can find the code and the demo video:
val outputDir = "/tmp/wfc/spark3/nested-predicate-pushdown"
val inputDataset = Seq(
NestedPredicatePushTestObject(1, NestedPredicatePushEntity("a")),
NestedPredicatePushTestObject(2, NestedPredicatePushEntity("b")),
NestedPredicatePushTestObject(3, NestedPredicatePushEntity("a")),
NestedPredicatePushTestObject(4, NestedPredicatePushEntity("c")),
NestedPredicatePushTestObject(5, NestedPredicatePushEntity("a"))
).toDS()
inputDataset.write.mode("overwrite").parquet(outputDir)
sparkSession.read
.parquet(outputDir)
.filter("nestedField.letter = 'a'")
.show(20)
The support for the nested fields predicate pushdown is another way to accelerate the execution time of Apache Spark pipelines. Another great news for this new 3.0 release 🤩
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.0 - predicate pushdown support for nested fields here:
- Predicate Pushdown for Nested fields [SPARK-12355][SQL] Implement unhandledFilter interface for Parquet #10502
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3.0 - GPU-aware scheduling
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - UI changes
- What's new in Apache Spark 3.0 - dynamic partition pruning
You certainly know predicate pushdown feature in #ApacheSpark. Starting from #SparkSQL 3, it works on the nested fields! More details in the new blog post ? https://t.co/4OHs1fxku6
— Bartosz Konieczny (@waitingforcode) September 19, 2020