
When I was preparing my talk about Apache Spark customization, I wanted to talk about User Defined Types. After some digging, I saw that there are some UDT in the source code and one of them was VectorUDT. And it led me to the topic of this post which is the vectorization.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Since it's a completely new concept for me, I will start the post by explaining some basics applied on the hardware level. Later I will focus on its implementation in Apache Spark SQL and more exactly, I will explain the implementation of one of the supported vectorized formats which is Apache Parquet.
Vectorized operations 101
When you put "vectorization" keyword, you will find plenty of interesting links and that's why I will try to summarize them here. For more information, I invite you to check the links from "Read also" section.
In simple terms, vectorization, which is also known as vector processing or SIMDization, is a way to apply an operation at once on the whole set of values. So for instance, instead of doing this:
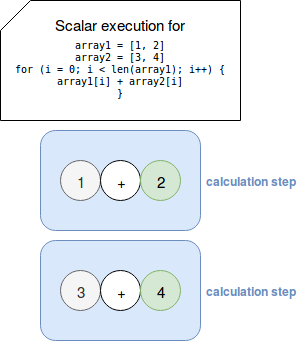
a vectorized program will do this:
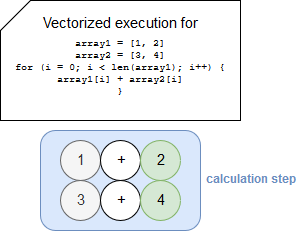
How is it even possible? To answer that question, we must go really deep in the hardware to the registers. To recall, a register (CPU register) is a fast storage place used by the processor to accept, store and transfer data and instructions. The register involved in the vectorization is called vector register. BTW, it's only one method of vector architectures. Another one is a memory-memory vector processor where the operands are fetched from memory and written there back as the vector operation proceeds. But let's stay with the case of vector registers.
The registers have a specific size. When one operation is vectorized, it's first divided (unrolled) to fill available space and to execute as many operations as possible in parallel. This time too, I will try to illustrate it with an image:
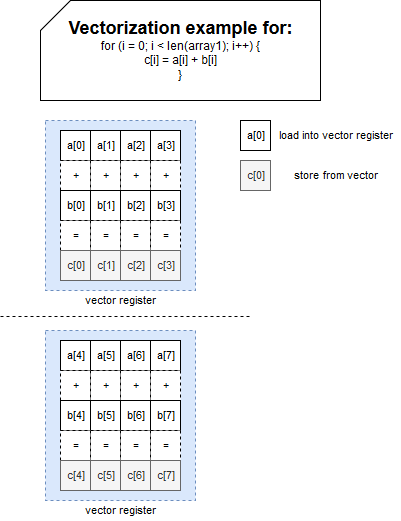
In this example, the vector has the size of 4, so 4 operations can be executed in parallel which can improve the execution time. In the sequential (scalar) mode, only the first column of the register will be used.
Vectorized operations and Apache Spark
The previous section presented some internal details for vectorization at the hardware level. But the question is, how does it relate to Apache Spark and its distributed computing model? Vectorization in Apache Spark is defined in the classes from org.apache.spark.sql.vectorized and org.apache.spark.sql.execution.vectorized packages. If you start by analyzing their names, you will immediately see that the vectorization is related to column-oriented storage, so to the data sources like Apache Parquet, Apache ORC or Apache Arrow. Covering all of them would be hard so I will take Apache Parquet as the example.
To understand vectorization in distributed data processing, let's start at the beginning. How does Apache Spark read vectorized files? The investigation starts with the generated code and more exactly with a scan_nextBatch_NR (NR >= 0) method looking like:
/* 073 */ private void scan_nextBatch_0() throws java.io.IOException {
/* 074 */ long getBatchStart = System.nanoTime();
/* 075 */ if (scan_mutableStateArray_0[0].hasNext()) {
/* 076 */ scan_mutableStateArray_1[0] = (org.apache.spark.sql.vectorized.ColumnarBatch)scan_mutableStateArray_0[0].next();
/* 077 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(scan_mutableStateArray_1[0].numRows());
/* 078 */ scan_batchIdx_0 = 0;
/* 079 */ scan_mutableStateArray_2[0] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) scan_mutableStateArray_1[0].column(0);
/* 080 */
/* 081 */ }
/* 082 */ scan_scanTime_0 += System.nanoTime() - getBatchStart;
/* 083 */ }
So, what happens here? Apache Parquet format is supported by ParquetFileFormat class which depending on the configuration is parametrized to deal with vectorized on not vectorized data. The property responsible for that is spark.sql.parquet.enableVectorizedReader and its default value is true.
When the vectorization is enabled, ParquetFileFormat creates an instance of VectorizedParquetRecordReader which is wrapped by the iterator queried by Apache Spark for the processed rows. In the previous snippet, this iterator is exposed in scan_mutableStateArray_0[0].next() call.
Execution details
That's all for global picture. Let's check now which classes are involved and how vectorized data is constructed. The object responsible for everything is already mentioned VectorizedParquetRecordReader. It exposes a method called nextBatch() which accordingly to the documentation, "advances to the next batch of rows". Here you can already notice that under-the-hood, the vectorized data is considered as batched one, so if you analyze the code, it's better to look for "batch" and "vector" terms rather than only for the latter one. VectorizedParquetRecordReader is composed of 2 classes used in the batch reading, WritableColumnVector and ColumnarBatch.
WritableColumnVector is only an abstract class and its implementations are adapter either for on-heap or off-heap storage. Despite that subtle difference, they all have a common goal to store data read from Parquet files in each of processed batches. But how Apache Spark controls the batch size?. It does it with the configuration property called spark.sql.parquet.columnarReaderBatchSize. When a new batch is processed, the size of items to read from Parquet's data page (you can read more details about internal storage in Parquet: Data storage in file post) is determined as Math.min((long) capacity, totalCountLoadedSoFar - rowsReturned) where min is the introduced property. totalCountLoadedSoFar is the property incremented at every read page whereas rowsReturned represents the number of rows processed by Apache Spark.
Parquet data is physically loaded by VectorizedColumnReader#readBatch(int total, WritableColumnVector column) method, just after resolving the batch size:
// VectorizedParquetRecordReader#nextBatch
int num = (int) Math.min((long) capacity, totalCountLoadedSoFar - rowsReturned);
for (int i = 0; i < columnReaders.length; ++i) {
if (columnReaders[i] == null) continue;
columnReaders[i].readBatch(num, columnVectors[i]);
}
// readBatch
/**
* Reads `total` values from this columnReader into column.
*/
void readBatch(int total, WritableColumnVector column) throws IOException {
/// ...
Above part figures out the lines of Parquet data pages to read and the bridge between Apache Spark and Apache Parquet API is made in VectorizedColumnReader#readPage() method which works on one of Parquet's data page versions (V1 or V2). Later the input stream of the page is passed to one of VectorizedValuesReaders. That reader is used later by VectorizedColumnReader's read${TYPE}Batch(int rowId, int num, WritableColumnVector column) methods (e.g. TYPE = Int).
Summary in images
The post is quite long so to summarize all sayings, I prepared 2 simple schemas for the under-the-hood execution. The first one presents a global picture of the execution:

And in the second one you can find more detailed concepts:
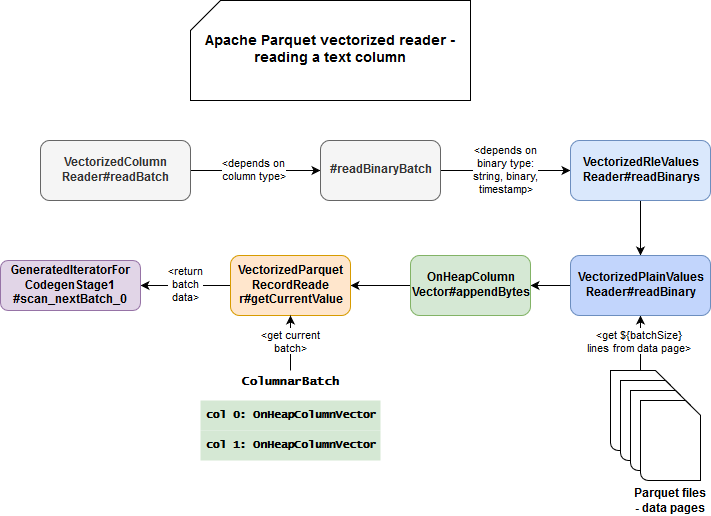
The most important takeaway for vectorization is the performance impact. As you saw, vectorization accumulates multiple inputs in a single batch and processes them at once. The batch is, by the way, the keyword (aside from vectorization) to understand vectorized formats in Apache Spark.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Vectorized operations in Apache Spark SQL here:
- Spark 2.x - 2nd generation Tungsten Engine Vectorized Query Execution in Apache Spark at Facebook Chen Yang Facebook How does Apache Spark read a parquet file
Related blog posts:
In the first post of this week I focused on #ApacheSpark #SparkSQL vectorized readers. Curious about the concept?
— Bartosz Konieczny (@waitingforcode) September 13, 2019
You can read more about that here: https://t.co/rv9nzLuy65