
In my long - but not long enough! - journey with Apache Spark I've met the "checkpointing" world in the context of Structured Streaming mostly. But this term also applies to other modules including Apache Spark SQL, so batch processing!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Checkpoint or not
The first question is when to checkpoint? The primary use case for a checkpoint is iterative processing where Apache Spark continuously transforms a single dataset. Without the checkpoint, the lineage would only grow:
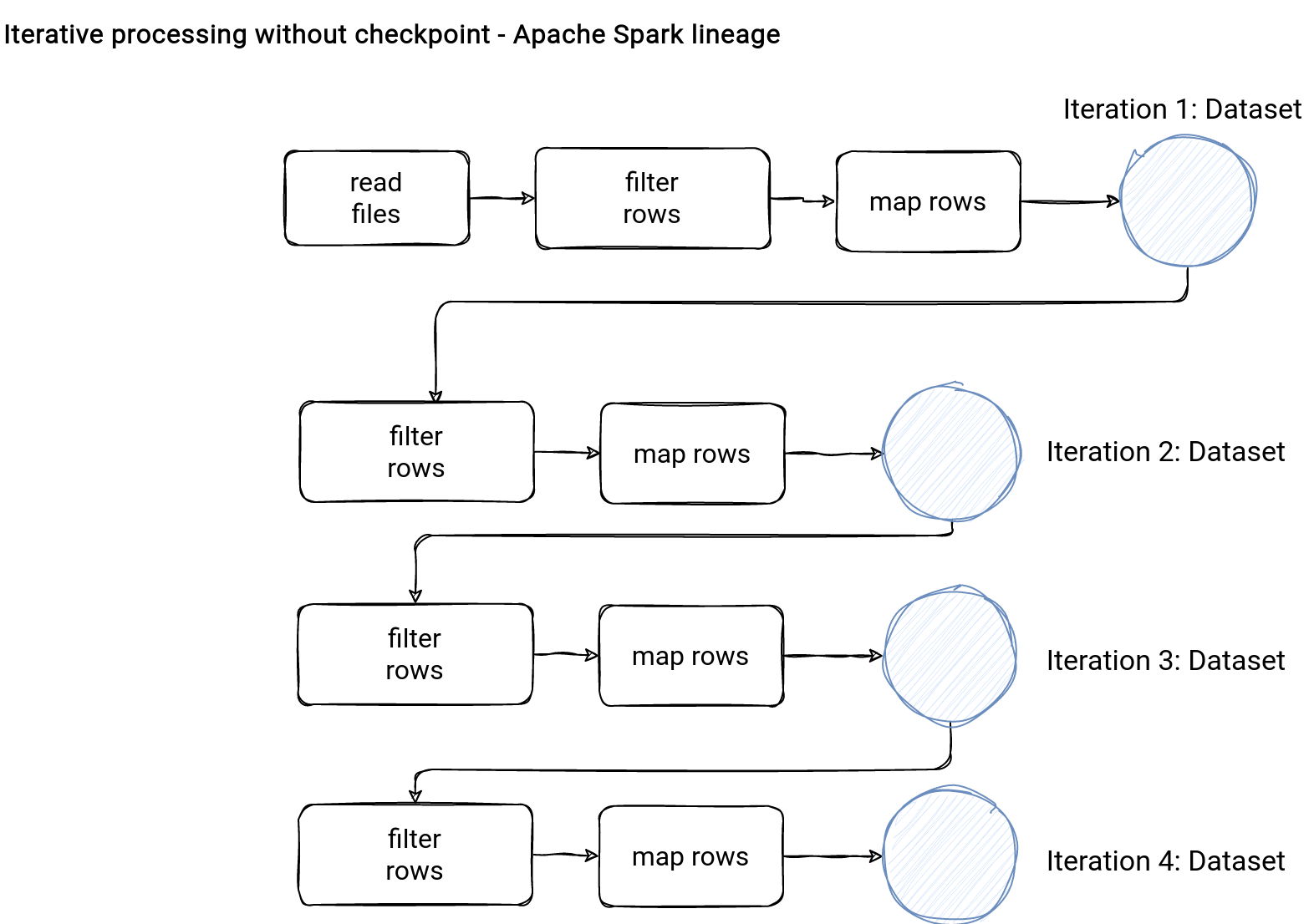
As a data engineer you won't probably see that kind of iteratively processed Datasets that much. But it's not the case with Machine Learning pipelines. Let's take a look at the Alternating Least Square computation from Spark MLlib:
object ALS extends DefaultParamsReadable[ALS] with Logging {
// ...
def train[ID: ClassTag]( // scalastyle:ignore
// ...
checkpointInterval: Int = 10,
seed: Long = 0L)(
implicit ord: Ordering[ID]): (RDD[(ID, Array[Float])], RDD[(ID, Array[Float])]) = {
// ...
for (iter <- 1 to maxIter) {
userFactors.setName(s"userFactors-$iter").persist(intermediateRDDStorageLevel)
val previousItemFactors = itemFactors
itemFactors = computeFactors(userFactors, userOutBlocks, itemInBlocks, rank, regParam,
userLocalIndexEncoder, implicitPrefs, alpha, solver)
previousItemFactors.unpersist()
itemFactors.setName(s"itemFactors-$iter").persist(intermediateRDDStorageLevel)
// TODO: Generalize PeriodicGraphCheckpointer and use it here.
if (shouldCheckpoint(iter)) {
itemFactors.checkpoint() // itemFactors gets materialized in computeFactors
}
val previousUserFactors = userFactors
userFactors = computeFactors(itemFactors, itemOutBlocks, userInBlocks, rank, regParam,
itemLocalIndexEncoder, implicitPrefs, alpha, solver)
if (shouldCheckpoint(iter)) {
itemFactors.cleanShuffleDependencies()
deletePreviousCheckpointFile()
previousCheckpointFile = itemFactors.getCheckpointFile
}
previousUserFactors.unpersist()
}
As you can see in the snippet, the itemFactors is an iterative Dataset that eventually gets checkpointed after several iterations. It's a real-world example but we could write also our own:
var iterativeDataset = rawInput.filter("nr > 1").selectExpr("nr * 2 AS nr")
(0 to 3).foreach(nr => {
iterativeDataset = iterativeDataset.filter(s"nr > ${nr}").selectExpr(s"(nr * ${nr}) AS nr")
})
Even though I only added 4 iterators to keep it short, the logical plan is already long:
== Analyzed Logical Plan ==
nr: int
Project [(nr#22 * 3) AS nr#24]
+- Filter (nr#22 > 3)
+- Project [(nr#20 * 2) AS nr#22]
+- Filter (nr#20 > 2)
+- Project [(nr#18 * 1) AS nr#20]
+- Filter (nr#18 > 1)
+- Project [(nr#16 * 0) AS nr#18]
+- Filter (nr#16 > 0)
+- Project [(nr#10 * 2) AS nr#16]
+- Filter (nr#10 > 1)
+- Project [_1#3 AS nr#10, _2#4 AS label#11, _3#5 AS modulo#12]
+- LocalRelation [_1#3, _2#4, _3#5]
On the other hand, if you compare it if the plan created from a checkpointed dataset, you will see the difference:
(0 to 3).foreach(nr => {
if (nr % 2 == 0) {
iterativeDataset = iterativeDataset.checkpoint(true)
}
iterativeDataset = iterativeDataset.filter(s"nr > ${nr}").selectExpr(s"(nr * ${nr}) AS nr")
})
And the plan is really short:
== Analyzed Logical Plan ==
nr: int
Project [(nr#24 * 3) AS nr#26]
+- Filter (nr#24 > 3)
+- Project [(nr#21 * 2) AS nr#24]
+- Filter (nr#21 > 2)
+- LogicalRDD [nr#21], false
I'm sharing here the analyzed plans because they illustrate the difference better than the optimized plans.
The key takeaway from this part is the lineage reduction by the checkpoint operation. It's also the most visible difference between checkpoint and cache. On the surface both "materialize" the dataset somehow but checkpoint does it without the lineage.
Eager and lazy checkpoint
If you analyze my previous code snippet you will certainly notice a true argument passed to the checkpoint method. This boolean value configures the checkpoint process as being eager or lazy. The difference is the moment when Apache Spark copies the underlying RDD to the checkpoint location defined in the sparkContext.setCheckpointDir("...") method.
The eager strategy triggers the checkpointing job immediately. So it's a blocking operation and Apache Spark can't do anything more before it finishes:
class Dataset[T] private[sql](
@DeveloperApi @Unstable @transient val queryExecution: QueryExecution,
@DeveloperApi @Unstable @transient val encoder: Encoder[T])
extends Serializable {
// ...
private def checkpoint(eager: Boolean, reliableCheckpoint: Boolean): Dataset[T] = {
// ...
val internalRdd = physicalPlan.execute().map(_.copy())
if (reliableCheckpoint) {
internalRdd.checkpoint()
} else {
internalRdd.localCheckpoint()
}
if (eager) {
internalRdd.doCheckpoint()
}
What happens otherwise? Apache Spark only marks the underlying RDD as for being checkpointed and delays the physical checkpoint operation after the completion of the job using the checkpointed RDD:
class SparkContext(config: SparkConf) extends Logging {
def runJob[T, U: ClassTag](rdd: RDD[T], func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int], resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
By default Apache Spark uses the eager and reliable checkpoint that brings us to the next point.
Local checkpoint
Besides the materialization time, there is another difference in the checkpoints, the fault-tolerance. A checkpoint can be local or reliable. The latter is easy to understand. Typically, you define a checkpoint directory on HDFS or an object store and Apache Spark writes the shortened RDD there.
When it comes to the local checkpoints, they work...locally, on executors. I'll tell you more, they even rely on the Apache Spark caching layer!
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
def localCheckpoint(): this.type = RDDCheckpointData.synchronized {
// ...
if (storageLevel == StorageLevel.NONE) {
persist(LocalRDDCheckpointData.DEFAULT_STORAGE_LEVEL)
} else {
persist(LocalRDDCheckpointData.transformStorageLevel(storageLevel), allowOverride = true)
}
// ...
Since this local mode is tied to Apache Spark executors, it's less reliable because they can go down at any moment and lose the checkpointed part of the RDD. There is even a warning that can pop up when you use Dynamic Resource Allocation with local checkpointing:
if (conf.get(DYN_ALLOCATION_ENABLED) &&
conf.contains(DYN_ALLOCATION_CACHED_EXECUTOR_IDLE_TIMEOUT)) {
logWarning("Local checkpointing is NOT safe to use with dynamic allocation, " +
"which removes executors along with their cached blocks. If you must use both " +
"features, you are advised to set `spark.dynamicAllocation.cachedExecutorIdleTimeout` " +
"to a high value. E.g. If you plan to use the RDD for 1 hour, set the timeout to " +
"at least 1 hour.")
}
Checkpoint or sink?
After all this quite technical analysis, one question remains open, why not using the Apache Spark native sink capability to cut the lineage? In the end the result is the same but the operation itself will be different. First, you would need to add a read/write part inside your iteration which already adds some overhead to the code itself. It's not valid for the checkpoint operation which has a coding semantic similar to the caching.
Second, you would need to pay the cost of reading the data and converting it directly to the Dataset. It doesn't happen for the checkpoint where Apache Spark saves the RDD in binary format directly:
bartosz@bartosz:/tmp$ tree spark-sql/checkpoint/ -J
[
{"type":"directory","name":"spark-sql/checkpoint/","contents":[
{"type":"directory","name":"687b397b-974e-4481-9f59-336c9df9e1b3","contents":[
{"type":"directory","name":"rdd-2","contents":[
{"type":"file","name":"part-00000"},
{"type":"file","name":"part-00001"},
{"type":"file","name":"part-00002"},
{"type":"file","name":"part-00003"}
]},
{"type":"directory","name":"rdd-5","contents":[
{"type":"file","name":"part-00000"},
{"type":"file","name":"part-00001"},
{"type":"file","name":"part-00002"},
{"type":"file","name":"part-00003"}
]}
]}
]},
{"type":"report","directories":3,"files":8}
]
3 directories, 8 files
##
bartosz@bartosz:/tmp$ less spark-sql/checkpoint/687b397b-974e-4481-9f59-336c9df9e1b3/rdd-2/part-00000 @3org.apache.spark.sql.catalyst.expressions.UnsafeRow^GO<9B>w^L^@^@xr^@)org.apache.spark.sql.catalyst.InternalRow;(5K^]^R^B^@^@xpw^X^@^@^@^P^@^@^@^A^@^@^@^@^@^@^@^@^D^@^@^@^@^@^@^@x
spark-sql/checkpoint/687b397b-974e-4481-9f59-336c9df9e1b3/rdd-2/part-00000 (END)
It implies a different physical execution:
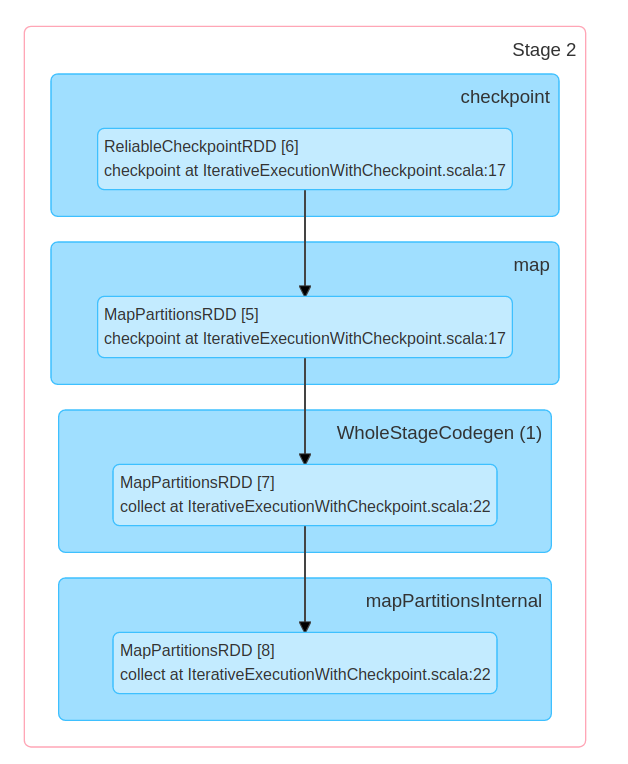
Finally, the checkpoint, even saved to a reliable storage, is limited to a single Apache Spark application. There is no API to read it back from a different place. It's not true for the sink that you can write and use in other places.
I'm almost sure you won't face checkpointed code very often in your data engineering pipelines. Having this kind of iteratively built Datasets is rare. However, it's good to know if you often work with your data scientist teammates and Spark MLlib pipelines!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Apache Spark 3.4.0 was released this week but I haven't had enough time to prepare the new "What's new..." series. Instead, I have something else for you. A blog post explaining checkpoints in #ApacheSparkSQL ? https://t.co/hW9tspwuHo
— Bartosz Konieczny (@waitingforcode) April 16, 2023