
That's one of my recent surprises. While I have been exploring arbitrary stateful processing, hence the mapGroupsWithState among others, I mistakenly created a batch DataFrame and applied the mapping function on top of it. Turns out, it worked! Well, not really but I let you discover why in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The code snippet I'm talking about looks like that:
val timestampedEvents = Seq(
TimestampedEvent(1, Timestamp.valueOf("2024-04-01 09:00:00")),
TimestampedEvent(2, Timestamp.valueOf("2024-04-01 09:02:00")),
TimestampedEvent(3, Timestamp.valueOf("2024-04-01 09:04:00")),
TimestampedEvent(4, Timestamp.valueOf("2024-04-01 09:12:50")),
TimestampedEvent(1, Timestamp.valueOf("2024-04-01 09:00:00")),
TimestampedEvent(2, Timestamp.valueOf("2024-04-01 10:02:50"))
).toDS
val query = timestampedEvents.withWatermark("eventTime", "20 minutes")
.groupByKey(row => row.eventId)
.flatMapGroupsWithState(
outputMode = Update(),
timeoutConf = GroupStateTimeout.EventTimeTimeout())(StatefulMappingFunction.concatenateRowsInGroup)
As you can notice, everything is there for being a valid Structured Streaming transformation (watermark, output mode, stateful mapping, ...). But despite all this, when you run the job, the state passed to the StatefulMappingFunction.concatenateRowsInGroup is always empty! Why? Well, first it remains a batch job and batch jobs don't support stateful processing in Apache Spark. As they don't support it, they follow a different physical query planning depicted below:
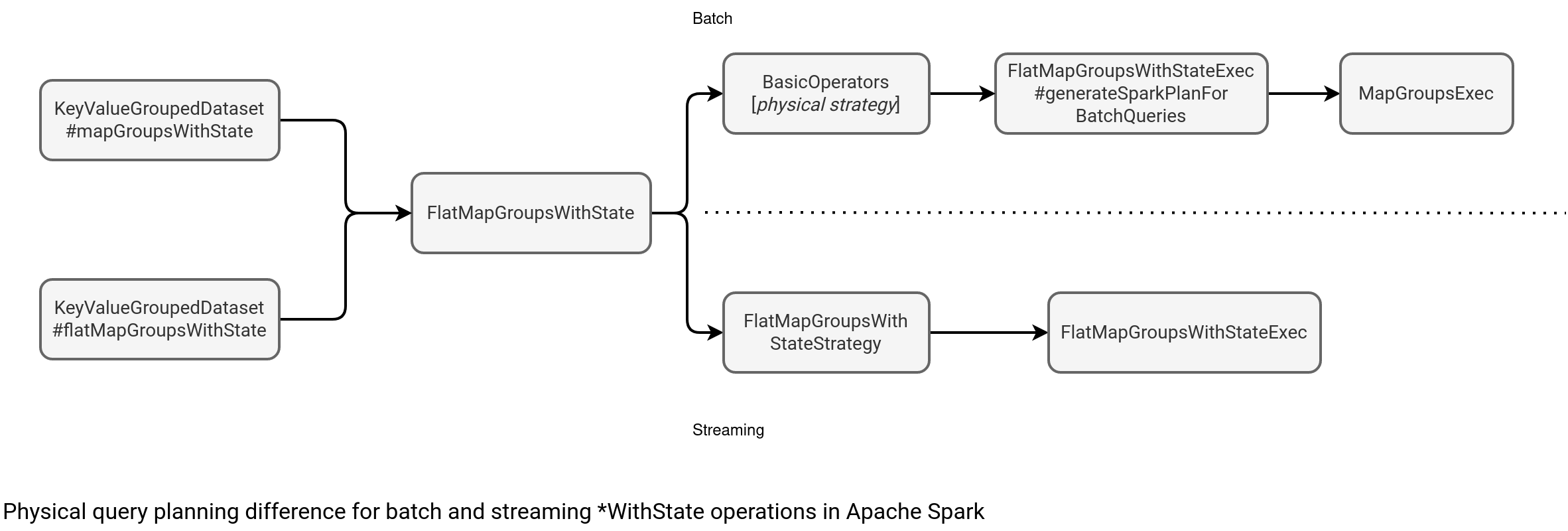
As you can see, the physical planner for batch applies a strategy that converts the *WithState function into a regular mapGroups:
// FlatMapGroupsWithStateExec#generateSparkPlanForBatchQueries
// ...
MapGroupsExec(
userFunc, keyDeserializer, valueDeserializer, groupingAttributes,
dataAttributes, Seq.empty, outputObjAttr, timeoutConf, child)
Does it mean the state is never used? When it comes to the regular *WithState call, yes. But there is one special case when the GroupState might not be empty, the batch job with state initialization.
State initialization
The state can be present only when you provide a state initialization DataFrame. In that case, the physical planner creates a CoGroupExec operator:
CoGroupExec(
func, keyDeserializer, valueDeserializer, initialStateDeserializer, groupingAttributes,
initialStateGroupAttrs, dataAttributes, initialStateDataAttrs, Seq.empty, Seq.empty,
outputObjAttr, child, initialState)
The mapping function receives then the first state from the state DataFrame:
val func = (keyRow: Any, values: Iterator[Any], states: Iterator[Any]) => {
val optionalStates = states.map { stateValue =>
if (foundInitialStateForKey) {
foundDuplicateInitialKeyException()
}
foundInitialStateForKey = true
stateValue
}.toArray
val groupState = GroupStateImpl.createForStreaming(
optionalStates.headOption,
System.currentTimeMillis,
GroupStateImpl.NO_TIMESTAMP, timeoutConf,
hasTimedOut = false, watermarkPresent)
// Call user function with the state and values for this key
userFunc(keyRow, values, groupState)
}
Let's see it in action now:
val initialStateDf: KeyValueGroupedDataset[Int, Seq[String]] = Seq(
(1, Seq("1=1")),
(10, Seq("10=10")),
).toDF("id", "stateValue").as[(Int, Seq[String])].groupByKey(row => row._1).mapValues(row => row._2)
val query = timestampedEvents.withWatermark("eventTime", "20 minutes")
.groupByKey(row => row.eventId)
.flatMapGroupsWithState(
outputMode = Update(),
timeoutConf = GroupStateTimeout.EventTimeTimeout(),
initialState = initialStateDf)(
func = StatefulMappingFunction.concatenateRowsInGroup)
The initial state must be an instance of the KeyValueGroupedDataset so that both can be combined with the same key.
And the watermark?
And what happens with the watermark? Technically, there is nothing wrong to call the withWatermark on top of the batch DataFrame:
val timestampedEvents = Seq(
// ...
).toDS
val query = timestampedEvents.withWatermark("eventTime", "20 minutes")
.groupByKey(row => row.eventId)
However, under-the-hood it involves a logical plan rule that removes the watermark expression. Take a look at the withWatermark function for the batch DataFrame:
def withWatermark(eventTime: String, delayThreshold: String): Dataset[T] = withTypedPlan {
val parsedDelay = IntervalUtils.fromIntervalString(delayThreshold)
require(!IntervalUtils.isNegative(parsedDelay), s"delay threshold ($delayThreshold) should not be negative.")
EliminateEventTimeWatermark(
EventTimeWatermark(UnresolvedAttribute(eventTime), parsedDelay, logicalPlan))
}
The EliminateEventTimeWatermark rule simply extracts all children plan below the watermark expression and passes it without its parent:
object EliminateEventTimeWatermark extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsWithPruning(
_.containsPattern(EVENT_TIME_WATERMARK)) {
case EventTimeWatermark(_, _, child) if !child.isStreaming => child
}
And the watermark with initial state?
I bet you didn't see this one coming! Turns out, it behaves differently than the watermark without the state loading! The reason is hidden in the generateSparkPlanForBatchQueries creating the cogroup operation:
if (hasInitialState) {
val watermarkPresent = child.output.exists {
case a: Attribute if a.metadata.contains(EventTimeWatermark.delayKey) => true
case _ => false
}
val groupState = GroupStateImpl.createForStreaming(
optionalStates.headOption, System.currentTimeMillis,
GroupStateImpl.NO_TIMESTAMP, timeoutConf,
hasTimedOut = false, watermarkPresent)
As you can see, the code first checks the watermark presence but as you already know, the withWatermark expression is ignored in batch. As a consequence if you mapping function calls state.getCurrentWatermarkMs(), you'll get an error:
org.apache.spark.SparkUnsupportedOperationException: Cannot get event time watermark timestamp without setting watermark before [map|flatMap]GroupsWithState.
I must admit, although this behavior doesn't bring any failure besides this watermark situation, the whole mapGroupsWithState in batch is slightly counter-intuitive. Users could think that the watermarks and stateful transformations, hence the transformations persisting the state, are allowed. But as you saw in this blog post, the transformation is just a regular map groups function with eventually some initial state enrichment which, that being said, it's quite a convenient way to bootstrap the context.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩