
Apart from data processing-related changes, Apache Spark 3.0 also brings some changes at the UI level. The interface is supposed to be more intuitive and should help you understand processing logic better!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Categorizing the UI changes turned out to be a bit harder than classifying the changes related to processing logic since this classification will be very objective. Nonetheless, I hope you will be able to easily understand what changed in the new major release of the framework. In the first part of the post, you will discover the evolutions related to the tooltips. In the second you will see what changed in the execution plans. Just after them, you will see the Structured Streaming UI improvements and finally get a list of some bug fixes.
Tooltips
Tooltips were the first major evolution of the Apache Spark 3 UI. And if you remember hovering the Executors tab and getting the help information like:
You should be positively surprised by Apache Spark 3.0 because the tooltips provide now an interesting explanation of the column. Moreover, some new tooltips were also added to make your engineering life easier.
In general , all the tabs were impacted and you will see some of the changes by the end of this blog post. This change is also a great occasion to discover the UI internals. The tooltips are managed inside ToolTips object in ui.storage and ui packages. Some of them are reused in different UI parts and one of the greatest examples of it is the duration, added in Spark 3.0.0:
val DURATION =
"Elapsed time since the stage was submitted until execution completion of all its tasks."
Plans
Some changes were also made to make the plans execution more readable. One of them concerns the code stage ids that were added to the SQL Tab:
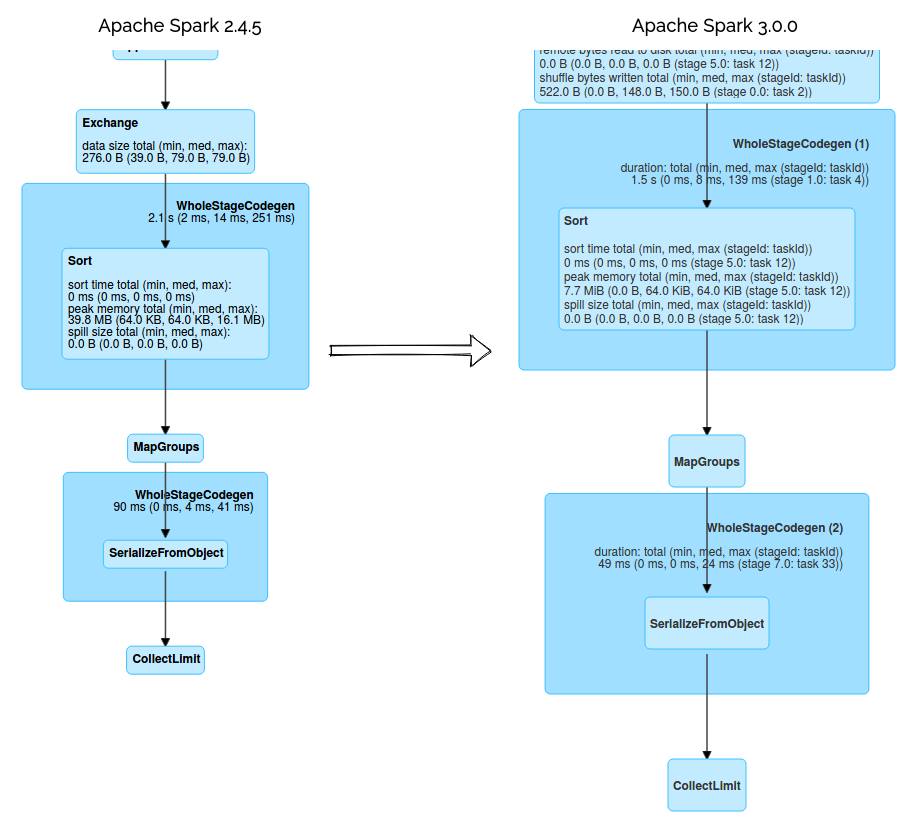
Starting from version 3, you can also get the max metric for the stage and task of every plan node. For example, with this information, you can easily discover the max time spent on the shuffle writes. But to enable them, do not forget to check this checkbox:

Structured Streaming
Another big change in Apache Spark 3.0 UI is the Structured Streaming tab that will appear next to SQL tab for the streaming queries. You won't find it in Apache Spark 2.4.5 and as you can see in the screen below, debugging Structured Streaming application should be now much easier:

One of the nice features of this tab is the Operation Duration block that shows the detailed statistics of every executed micro-batch. You can then learn about the most time-consuming operation just by comparing them visually, without necessarily going to the logs and building your comparison from the logged statistics!

Bug fixes
Finally, as for every release, there are also some bug fixes. One of the great improvements in that field is the ability to search in the Task tabs directly by the displayed values and not the unformatted ones.
It's also important to notice the addition of multiple accumulators in the tasks table and a very smart change of the method controlling the display of complete or incomplete applications on the Spark History UI. Before 3.0.0, the check were made like this:
val allAppsSize = parent.getApplicationList()
val displayApplications = parent.getApplicationList()
.count(isApplicationCompleted(_) != requestedIncomplete)
if (allAppsSize > 0) {
if (displayApplications) {
<script src={UIUtils.prependBaseUri(
But after all, we can display the part as soon as one application meets the completeness condition (complete vs incomplete display):
val displayApplications = parent.getApplicationList()
.exists(isApplicationCompleted(_) != requestedIncomplete)
if (displayApplications) {
<script src={UIUtils.prependBaseUri(
Also, the SQL tab supports the pagination and becomes more consistent with the remaining tabs. This change also avoids the potential Out Of Memory errors in case of multiple executed jobs.
Below you can find a video that compares some of the changes introduced in this blog post:
Our daily work can be improved with appropriate monitoring and altering tools. Apache Spark UI, with the effort put in the most recent release, makes it better! Especially for the Structured Streaming users and newcomers who can familiarize themselves with the interface easier thanks to the improved tooltip messages.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3.0 - GPU-aware scheduling
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - dynamic partition pruning
- What's new in Apache Spark 3.0 - predicate pushdown support for nested fields
#ApacheSpark is not only about the code, it also about the visuals ?️ The new version of the framework brings some important changes in the UI part, including a major evolution for #StructuredStreaming pipelines ? https://t.co/uFVLcBn4E4
— Bartosz Konieczny (@waitingforcode) October 10, 2020