
Spark 2.2.0 brought the change of structured streaming state. Between 2.0 and 2.2.0 it was marked as "alpha". But the last version changed this status to General Availability. It's so a good moment to start to play with this new feature - even if some basics have already been covered in the post about structured streaming. This time we'll go deeper and analyze the integration with Apache Kafka that will be helpful to
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post begins by explaining how use Kafka structured streaming with Spark. It will recall the difference between source and sink and show some code used to to connect to the broker. In next sections this code will be analyzed. The second section will describe the source provider. The third part will be devoted to the offsets management. The last part will describe data reading.
Integrating Kafka with Spark structured streaming
Structured streaming integrated Kafka as source and sink. It means that we can read and write messages. In big picture using Kafka in Spark structured streaming is mainly the matter of good configuration. The configuration that starts by defining the brokers addresses in bootstrap.servers property. It also supports the parameters defining reading strategy (= starting offset, param called startingOffset) and the data source (topic-partition pairs, topics or topics RegEx). We can also easily manage the failure with retry parameters (= fetchOffset.numRetries, fetchOffset.retryIntervalMs).
For the writer it's much simpler. We also need to define bootstrap servers but it's the single one required property. The second entry, topic, indicates the place where the rows will be written but it's optional. If each message carries topic information, it's not required to configure this parameter globally.
The sample code using Kafka structured streaming is:
sparkSession.readStream.format("kafka")
.options(configuration.getStructuredStreamOptions())
.load()
Kafka source provider
For the reading everything starts at org.apache.spark.sql.kafka010.KafkaSourceProvider class. But before it's called, DataSource class resolves the provider according to the value defined in format(String) during DataStreamReader construction. The provider's resolution happens in org.apache.spark.sql.execution.datasources.DataSource#lookupDataSource where Spark uses Java's ServiceLoader to find all loaded classes implementing the org.apache.spark.sql.sources.DataSourceRegister interface. Later it iterates over all of them lazily (= it doesn't materialize all classes at once). On each found class the org.apache.spark.sql.sources.DataSourceRegister#shortName() method is called. It's compared with the value specified in format(...) and if both match, appropriated provider is chosen.
If any of loaded classes don't match, Spark considers that format(...) contains the full provider's name and it tries to load it directly from the classpath. If the class is not loaded, Spark will try to get the default source (= format(...) source suffixed with DefaultSource, e.g. kafka.DefaultSource). So as you see, this resolution step is very useful when you don't want to define full class name every time in format(...) method.
After loading the source provider, the real source class is created by calling org.apache.spark.sql.sources.StreamSourceProvider#createSource(org.apache.spark.sql.sources.StreamSourceProvider#createSource) method.
During the creation of Kafka source, Kafka source provider defines:
- unique group id - it allows to retrieve all data into a single query. Otherwise, if the second query would be executed on the same topic as the first query, data could arrive partially to both consumers. It could lead to the creation of Message queue.
- driver offset reader - pretty interesting point. Spark will create a Kafka consumer on the driver that will only read data offsets from Kafka. The characteristic trait is that driver's consumer doesn't commit any offsets and it's only there to discover topic topology. The whole operations returns an instance of KafkaOffsetReader.
executors configurations - created KafkaOffsetReader is later passed to the KafkaSource that is created with the executors configuration. Both concepts are detailed better in the next sections.
Preparing offsets
Before exploring implementation details, below schema shows some of described interactions between Spark structured streaming and Kafka module:
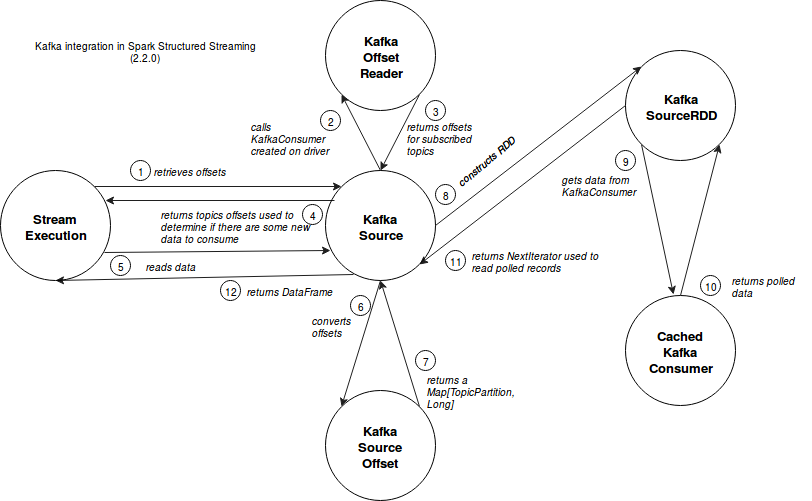
Spark structured streaming still works in micro batches. They're managed by org.apache.spark.sql.execution.streaming.StreamExecution class and more exactly by its implementation of org.apache.spark.sql.execution.streaming.StreamExecutionThread#StreamExecutionThread. Internally it calls the private method called runBatches() that triggers data retrieval every specified interval of time (ProcessingTimeExecutor) or only once (OneTimeExecutor). And the interaction between StreamExecution and kafka source begins when constructNextBatch() is called (before it, StreamExecution resolves offsets for each source).
The first thing StreamExecution does with Kafka is the retrieval of offsets that, in this specific case, are the pairs (topic partition, offset). These pairs are returned by fetchLatestOffsets() method of KafkaOffsetReader that is called by Kafka source. It's there where offset-specific consumer is used. The reading consists on simple call of KafkaConsumer's methods (poll, assignment, pause , seekToEnd and position).
So constructed partitions are returned and used by StreamExecution's dataAvailable() method to check if there are new data available for reading. This check consists on simple comparison between new offset and current offset for each partition.
Reading data
If new data is available, StreamExecution instance calls KafkaSource getBatch(start: Option[Offset], end: Offset) to retrieve data contained between 2 offsets. The first thing it does is the conversion of received offset to Map[TopicPartition, Long] through the call of Map[TopicPartition, Long] of KafkaSourceOffset getPartitionOffsets(offset: Offset).
StreamExecution follows already consumed offsets. The first parameter (start) sent to getBatch method corresponds to the last seen offset in previous micro-batch. KafkaSource uses it to detect new and deleted partitions:
// frompartitionsOffset created from start param // untilPartitionsOffset created from end param val newPartitions = untilPartitionOffsets.keySet.diff(fromPartitionOffsets.keySet) val deletedPartitions = fromPartitionOffsets.keySet.diff(untilPartitionOffsets.keySet)
After resolving partitions to read, KafkaSource creates the instances of KafkaSourceRDDOffsetRange used later as the implementation of Spark's Partition object to Kafka RDD. An interesting point to note here is that KafkaSource always tries to reuse Kafka consumers already present (cached) on executors. It achieves that in the following algorithm:
sorted_executors = sort_executors_by_host_and_id(all_executors) all_executors = count(sorted_executors) for each tp in topic_partitions: tp_hash_code = hash_code(tp) # below field means the executor's index that should read given # topic partition prefered_tp_location = tp_hash_code - (tp_hash_code/all_executors) * all_executors
Since everything in Spark is at the end represented by RDD, KafkaSource creates later an instance of KafkaSourceRDD. Some of its implementations are closely related to things computed previously:
- getPartitions - returns a list of partitions by mapping previously created KafkaSourceRDDOffsetRange objects to KafkaSourceRDDPartitions.
- getPreferredLocations(split: Partition) - KafkaSourceRDDPartition is a case class having 2 fields: index: Int, offsetRange: KafkaSourceRDDOffsetRange. This method uses directly the offsetRange value to return the executors where Kafka consumers for specific topic partition are already defined.
- compute(thePart: Partition, context: TaskContext) - the RDD is created with a flag reuseKafkaConsumer set to true. It's why it'll try to retrieve already existing Kafka consumer to read data from specific partition.
The partition records are returned in the NextIterator[ConsumerRecord[Array[Byte], Array[Byte]]] which next() method calls the instance of CachedKafkaConsumer that, under-the-hood, uses KafaConsumer to read data according to passed offsets. The reading consists on 2 steps:
- Seeking to the specified offset for given partition (org.apache.kafka.clients.consumer.KafkaConsumer#seek(TopicPartition partition, long offset))
- Polling the data for partition belonging to the CachedKafkaConsumer (org.apache.kafka.clients.consumer.KafkaConsumer#poll(long timeout))
The consistency of fetched data is strictly controlled. Every time when offset inconsistencies are detected, e.g. read offset is bigger than the max allowed offset, CachedKafkaConsumer either throws an IllegalStateException or logs a warning with messages like "Skip missing records in ....".
This post described some of information required to understand Kafka integration with Spark structured streaming. The first part recalled a little about the concepts of sources and sinks. The second part shown 2 ways to define streaming source through the format(...) method accepting as well an alias as the full class name. The next part presented how Spark deals with Kafka offsets through to offset-related KafkaConsumer instance created on the driver. The last section explained data reading part. We could see that Spark tries to reuse already created consumer by applying a specific algorithm. We could also observe that it controls every time the consumed offsets by throwing an exception or adding warning if some inconsistency is detected.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- What's new in Apache Spark 3.0 - Apache Kafka integration improvements
- Apache Kafka source in Structured Streaming - "beyond the offsets"
- Apache Kafka sink in Structured Streaming
- Apache Spark Structured Streaming and Apache Kafka offsets management
- org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start() explained
Small zoom at #Kafka integration in #ApacheSpark structured streaming https://t.co/P9NYByLa2b
— bardev (@waitingforcode) September 13, 2017