
Some time ago I got 3 interesting questions about the implementation of Apache Kafka connector in Apache Spark Structured Streaming. I will answer them in this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
As you can imagine, the post is divided into 3 sections. Each one will answer a single question. By the end of the post, you should better understand who is responsible for what in Apache Kafka connector.
Question 1: offset tracking
The first question is about Apache Kafka offsets tracking. Who keeps track of them, driver or executors? Before I will deep delve into the problem, let's recall some basics I shortly presented in Analyzing Structured Streaming Kafka integration - Kafka source post. Apache Kafka source starts by reading offsets to process from the driver and distributes them to the executors for real processing. Hence, we can deduce that from this point of view, offsets are tracked by the driver. You can notice that in the code creating KafkaSourceRDD inside KafkaSource class:
// Calculate offset ranges
val offsetRanges = topicPartitions.map { tp =>
// ...
}
// Create an RDD that reads from Kafka and get the (key, value) pair as byte arrays.
val rdd = new KafkaSourceRDD(
sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
But if you take a deeper look at the code, especially on the partition readers for micro-batch and continuous executions, you'll see that they're also tracking the offsets:
// KafkaMicroBatchInputPartitionReader
override def next(): Boolean = {
if (nextOffset < rangeToRead.untilOffset) {
val record = consumer.get(nextOffset, rangeToRead.untilOffset, pollTimeoutMs, failOnDataLoss)
if (record != null) {
nextRow = converter.toUnsafeRow(record)
nextOffset = record.offset + 1
true
} else {
false
}
} else {
false
}
}
// KafkaContinuousInputPartitionReader
override def next(): Boolean = {
var r: ConsumerRecord[Array[Byte], Array[Byte]] = null
while (r == null) {
if (TaskContext.get().isInterrupted() || TaskContext.get().isCompleted()) return false
// Our consumer.get is not interruptible, so we have to set a low poll timeout, leaving
// interrupt points to end the query rather than waiting for new data that might never come.
try {
r = consumer.get(
nextKafkaOffset,
untilOffset = Long.MaxValue,
pollTimeoutMs,
failOnDataLoss)
} catch {
// We didn't read within the timeout. We're supposed to block indefinitely for new data, so
// swallow and ignore this.
case _: TimeoutException | _: org.apache.kafka.common.errors.TimeoutException =>
// This is a failOnDataLoss exception. Retry if nextKafkaOffset is within the data range,
// or if it's the endpoint of the data range (i.e. the "true" next offset).
case e: IllegalStateException if e.getCause.isInstanceOf[OffsetOutOfRangeException] =>
val range = consumer.getAvailableOffsetRange()
if (range.latest >= nextKafkaOffset && range.earliest <= nextKafkaOffset) {
// retry
} else {
throw e
}
}
}
nextKafkaOffset = r.offset + 1
currentRecord = r
true
}
Executors tracking has another role though. They're tracking the offsets simply to stay synchronized with driver's offsets. You can see that pretty well in the if conditions with range objects. In other words, executor's Kafka consumers will read records as long as the next expected offsets aren't bigger than the end offset sent by the driver.
Question 2: offsets commits
Fine, when we already know who is responsible for offsets tracking, it's time to answer a question about who commits the offsets, driver or executors? How driver which resolves offsets to process at every micro-batch knows what was really consumed? Do the executors may auto-commit offsets?
The answer to this question is less obvious than the previous one. To find it, I did a small grep on "ENABLE_AUTO_COMMIT_CONFIG" property inside /org/apache/spark/sql/kafka010 directory of the source and got this:
def kafkaParamsForDriver(specifiedKafkaParams: Map[String, String]): ju.Map[String, Object] =
ConfigUpdater("source", specifiedKafkaParams)
.set(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, deserClassName)
.set(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserClassName)
// So that consumers in the driver does not commit offsets unnecessarily
.set(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
}
def kafkaParamsForExecutors(
specifiedKafkaParams: Map[String, String],
uniqueGroupId: String): ju.Map[String, Object] =
ConfigUpdater("executor", specifiedKafkaParams)
// So that consumers in executors does not commit offsets unnecessarily
.set(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
}
Does it mean that none of them commits offsets? I had that impression after analyzing remaining classes and more particularly, the implementations of commit(end: Offset) method of KafkaContinuousReader and KafkaMicroBatchReader. The commit method is called at the end of a successful batch execution in MicroBatchExecution or at the end of a successful epoch execution in ContiuousExecution. Accordingly to the documentation, the method should be implemented to "inform the source that Spark has completed processing all data for offsets less than or equal to `end` and will only request offsets greater than `end` in the future.". For Apache Kafka source both implementations are empty so it's another proof that driver and executors consumers don't commit any offsets.
You can also find confirmation for that in the documentation next to enable.auto.commit property stating that "Kafka source doesn’t commit any offset".
Question 3: offset checkpointing
The last unanswered point concerns offset checkpointing. After the previous part, you understood that checkpoints help to keep track of consumed offsets. Who checkpoints them, driver or executors? The answer is the driver. Distributed checkpointing would be hard to implement whereas the one using a centralized actor like driver is much easier. Especially when it's him who orchestrates offsets retrieval.
Internally, the checkpointed offsets are represented by StreamExecution's offsetLog field. And if you are interested in the method which physically persists the offsets, you should search for the invocaitons of HDFSMetadataLog's add(batchId: Long, metadata: T). The offsets are committed before processing the next micro-batch or after processing an epoch in continuous mode (want to learn more about it? You can check my post Continuous execution in Apache Spark Structured Streaming).
To sum up, all 3 answers are resumed in the following image:
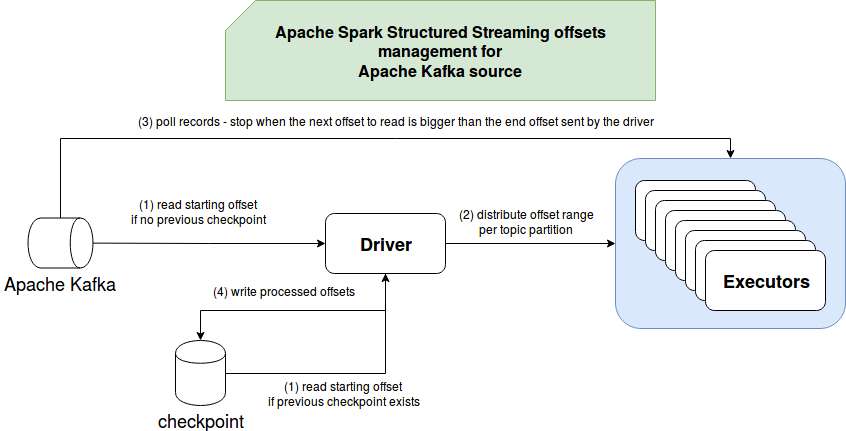
Even though the answers to these 3 questions seem obvious, it's always worth investigating the implementation. As you can learn in this post through the code snippets, Structured Streaming ignores the offsets commits in Apache Kafka. Instead, it relies on its own offsets management on the driver side which is responsible for distributing offsets to executors and for checkpointing them at the end of the processing round (epoch or micro-batch). If you have some questions like the one from this post, feel free to ask. I'm always eager to learn new things.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- What's new in Apache Spark 3.0 - Apache Kafka integration improvements
- Apache Kafka source in Structured Streaming - "beyond the offsets"
- Apache Kafka sink in Structured Streaming
- org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start() explained
- Analyzing Structured Streaming Kafka integration - Kafka source
It's time to write a little about #StructuredStreaming. In today's post I cover offsets management responsibilities for #ApacheKafka data source https://t.co/7gBYKLsvnf
— Bartosz Konieczny (@waitingforcode) July 18, 2019