
I've written a lot about data sources, including Apache Kafka. However, Apache Spark is not only about sources but also about targets called sinks. In this post I will focus on Apache Kafka sink integration and try to answer some question in FAQ mode.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I divided the post into 2 parts. In the first one, I will present a global picture of Apache Kafka sink integration. You'll find there mainly the classes and interaction diagram. In the second one, I will ask some questions and try to answer them in FAQ-mode.
Global overview
Before deepening delve into some implementations details, let's step back and see the classes involved in writing data to an Apache Kafka topic. It's quite important since a lot of them hide the answers to the questions from the next section:
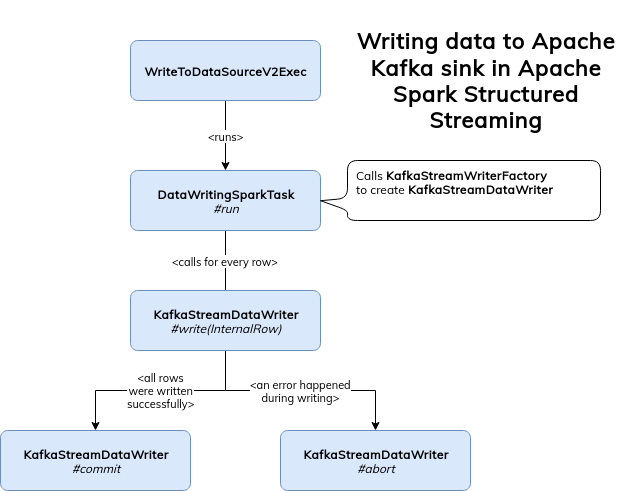
As you can see, apparently the execution flow is quite straightforward. In the beginning, Spark uses the DataWriterFactory associated with the used sink to initialize an instance of the class responsible for writing the processed data. In our case, it creates KafkaStreamDataWriter whose API is composed of 4 key methods: write to write every new row to the sink, commit to mark the operation as successful, abort to abort in case of failure and that flushes all buffered data to Kafka and destroys Kafka producer instance (that being said, I didn't find any use of this method in the code).
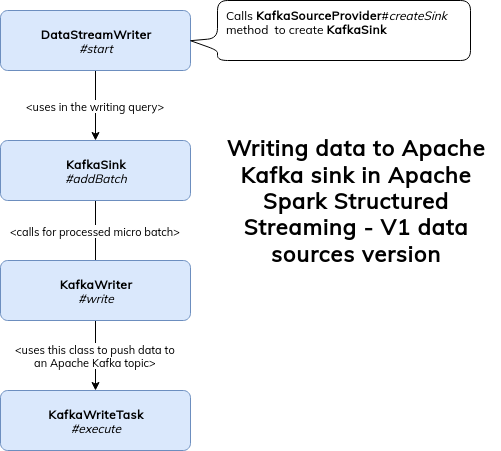
And I could terminate here if KafkaStreamDataWriter wouldn't be a child of KafkaRowWriter abstract class which automatically brings another potential implementation, KafkaWriteTask:
Kafka sink FAQ
Which of KafkaWriteTask and KafkaStreamDataWriter is used?
So first of all, why these 2 possible execution flows? In fact, they represent Apache Spark Structured Streaming evolution over time. Apache Spark 2.3.0 brought a new API for data sources (and sinks) called V2. It addressed the main drawbacks of the previous, Sink-based version, such as:
- high coupling to the upper level API because of DataFrame and SQL context passed in parameters
- physical storage information like partitioning or sorting is kept within the data source and Spark optimizer cannot use them to improve the execution plans
- no columnar interface to improve reading performance on column-based formats
- too general write interface - hard to extend it, for example with a transactions support
As of this writing (2.4.4), both interfaces are still supported, so it explains why there are still 2 different ways to write data to Kafka. FYI, V2 data source will be used by default but you can disable it with spark.sql.streaming.disabledV2Writers configuration entry.
What is the delivery semantic?
The answer is at least once. Why? It comes from the way of writing data to Apache Kafka. It's asynchronous and the producer uses callback's information to figure out the outcome of the write. In case of a failure, it sets the value of the received exception to failedWrite field. Later, during the processing, this field's definition is checked every time and in case of not emptiness, an exception is thrown:
protected def checkForErrors(): Unit = {
if (failedWrite != null) {
throw failedWrite
}
}
// V2 version
class KafkaStreamDataWriter {
def write(row: InternalRow): Unit = {
checkForErrors()
sendRow(row, producer)
}
def commit(): WriterCommitMessage = {
// Send is asynchronous, but we can't commit until all rows are actually in Kafka.
// This requires flushing and then checking that no callbacks produced errors.
// We also check for errors before to fail as soon as possible - the check is cheap.
checkForErrors()
producer.flush()
checkForErrors()
KafkaWriterCommitMessage
}
}
// V1 version - failure can happen in close method
private[kafka010] object KafkaWriter extends Logging {
def write(
sparkSession: SparkSession,
queryExecution: QueryExecution,
kafkaParameters: ju.Map[String, Object],
topic: Option[String] = None): Unit = {
val schema = queryExecution.analyzed.output
validateQuery(schema, kafkaParameters, topic)
queryExecution.toRdd.foreachPartition { iter =>
val writeTask = new KafkaWriteTask(kafkaParameters, schema, topic)
Utils.tryWithSafeFinally(block = writeTask.execute(iter))(
finallyBlock = writeTask.close())
}
}
}
private[kafka010] class KafkaWriteTask {
def close(): Unit = {
checkForErrors()
if (producer != null) {
producer.flush()
checkForErrors()
producer = null
}
}
}
So, if you replay your processing, you'll get the same records sent twice.
What is the role of KafkaWriterCommitMessage? Does it mean the sink supports transactions?
When I read the API for V2 sink, I thought "yes" but in fact no. You can't use transactions in Apache Kafka sink. I'm not sure about the reasons because Kafka's transactional producer seems to fit well with the new V2 interfaces, exposing commit and abort methods to validate or invalidate the transactions. Maybe it's planned for the next releases or maybe Kafka transactions aren't well suited to handle thousands of records at once? If you've any clue, share it via the comment.. Thanks to Jungtaek Lim, who is an Apache Spark contributor, you can understand why:
As Kafka's transactional is per connection, to achieve "transactional write" among multiple writers you'll need to deal with global transaction. While Flink dealt with this via introducing 2PC mechanism in sink side, Spark community didn't want to bring such change on Spark itself as it's going to be non-trivial change.
The "exactly-once" in DSv2 API is a bit different from 2PC - it requires driver to finalize the results from all writers, which is only possible and viable when all writers write the result to the "temporary" spot and there's an operation which "moves" the temporal results into final place. File stream sink with HDFS storage would work, as "rename" operation is atomic and costs O(1). The cost of "rename" is O(N) in object store - I think that's why file stream sink now leverages metadata file instead of renaming.
IMHO, Kafka transaction producer with 2PC cannot be perfect, as transaction timeout should be longer enough to tolerate long downtime but then all other transactions wouldn't be read from reader side. Alternatively we can mitigate the situation via reprocessing the batch, tolerating at-least-once in rare case, not technically exactly-once.
All discussion is in the comments section below this blog post.
So the role of KafkaWriterCommitMessage is purely contractual because it's required by DataWriter interface and transactions aren't implemented for Kafka sink.
How the records are pushed to Apache Kafka topic?
I partially answered that question previously. Structured Streaming sends records in an asynchronous manner and retrieves the outcome of the push via a callback:
private val callback = new Callback() {
override def onCompletion(recordMetadata: RecordMetadata, e: Exception): Unit = {
if (failedWrite == null && e != null) {
failedWrite = e
}
}
}
protected def sendRow(
row: InternalRow, producer: KafkaProducer[Array[Byte], Array[Byte]]): Unit = {
val projectedRow = projection(row)
val topic = projectedRow.getUTF8String(0)
val key = projectedRow.getBinary(1)
val value = projectedRow.getBinary(2)
if (topic == null) {
throw new NullPointerException(s"null topic present in the data. Use the " +
s"${KafkaSourceProvider.TOPIC_OPTION_KEY} option for setting a default topic.")
}
val record = new ProducerRecord[Array[Byte], Array[Byte]](topic.toString, key, value)
producer.send(record, callback)
}
Also, every time a final operation like commit or close is invoked, Apache Spark invokes flush() method of the Kafka producer. It's a blocking method that sends all records buffered by the producer to the configured topic.
How the Kafka producer is managed?
Let's talk now about the producer. Kafka producer is managed through CachedKafkaProducer factory class. As the name suggests, the class not only creates the producer but also manages its cache, ie. the same producer will be reused by many threads if its configuration doesn't change:
/**
* Get a cached KafkaProducer for a given configuration. If matching KafkaProducer doesn't
* exist, a new KafkaProducer will be created. KafkaProducer is thread safe, it is best to keep
* one instance per specified kafkaParams.
*/
private[kafka010] def getOrCreate(kafkaParams: ju.Map[String, Object]): Producer = {
val paramsSeq: Seq[(String, Object)] = paramsToSeq(kafkaParams)
try {
guavaCache.get(paramsSeq)
} catch {
case e @ (_: ExecutionException | _: UncheckedExecutionException | _: ExecutionError)
if e.getCause != null =>
throw e.getCause
}
}
The cache is managed by Google Guava's library and set to 10 minutes. However, this cache configuration causes some problems for any task running for more than 10 minutes simply because the cached producer will be destroyed:
private lazy val guavaCache: LoadingCache[Seq[(String, Object)], Producer] =
CacheBuilder.newBuilder().expireAfterAccess(cacheExpireTimeout, TimeUnit.MILLISECONDS)
.removalListener(removalListener)
.build[Seq[(String, Object)], Producer](cacheLoader)
private val removalListener = new RemovalListener[Seq[(String, Object)], Producer]() {
override def onRemoval(
notification: RemovalNotification[Seq[(String, Object)], Producer]): Unit = {
val paramsSeq: Seq[(String, Object)] = notification.getKey
val producer: Producer = notification.getValue
logDebug(
s"Evicting kafka producer $producer params: $paramsSeq, due to ${notification.getCause}")
close(paramsSeq, producer)
}
}
/** Auto close on cache evict */
private def close(paramsSeq: Seq[(String, Object)], producer: Producer): Unit = {
try {
logInfo(s"Closing the KafkaProducer with params: ${paramsSeq.mkString("\n")}.")
producer.close()
} catch {
case NonFatal(e) => logWarning("Error while closing kafka producer.", e)
}
}
That's the reason why the community tries since 2.4.4 release to overcome that issue. If nothing changes (I'm writing this post after preview-2 release of Apache Spark 3.0), a completely new cache system will be implemented in Spark 3.0, using not only timeout configuration but also references. Thanks to it, the producer will be evicted only when it's not referenced by any writing process.
Besides the cache, Structured Streaming uses the standard KafkaProducer typed to array of bytes: private type Producer = KafkaProducer[Array[Byte], Array[Byte]].
Does the sink supports multiple topics?
If you take a look at KafkaRowWriter constructor, you could think that no:
private[kafka010] abstract class KafkaRowWriter(
inputSchema: Seq[Attribute], topic: Option[String]) {
However, if you analyze the whole code source of this class, you will see that the initial supposition was not true. Apache Spark will, for every incoming row, make a projection where it resolves the target topic either from the constructor (if defined) or directly from the data to write by looking for "topic" column:
private def createProjection = {
val topicExpression = topic.map(Literal(_)).orElse {
inputSchema.find(_.name == KafkaWriter.TOPIC_ATTRIBUTE_NAME)
}.getOrElse {
throw new IllegalStateException(s"topic option required when no " +
s"'${KafkaWriter.TOPIC_ATTRIBUTE_NAME}' attribute is present")
}
topicExpression.dataType match {
case StringType => // good
case t =>
throw new IllegalStateException(s"${KafkaWriter.TOPIC_ATTRIBUTE_NAME} " +
s"attribute unsupported type $t. ${KafkaWriter.TOPIC_ATTRIBUTE_NAME} " +
s"must be a ${StringType.catalogString}")
}
Therefore, if you don't specify the topic via .writeStream..option("topic", "topic_to_write"), you have the possibility to provide fine-grained writes, like I have shown in the following snippet:
What about batch?
Kafka integration also supports batch processing. So you can process, let's say, S3 files, and write them to an Apache Kafka topic. Batch version uses the same classes as the streaming one except that it doesn't distinguish between V1 and V2. Batch producer always uses V1 because KafkaSourceProvider doesn't implement the WriteSupport interface required by V2 API:
private[kafka010] class KafkaSourceProvider extends DataSourceRegister
with StreamSourceProvider
with StreamSinkProvider
with RelationProvider
with CreatableRelationProvider
with StreamWriteSupport
with ContinuousReadSupport
with MicroBatchReadSupport
with Logging {
// ....
}
final class DataFrameWriter[T] private[sql](ds: Dataset[T]) {
def save(): Unit = {
val cls = DataSource.lookupDataSource(source, df.sparkSession.sessionState.conf)
if (classOf[DataSourceV2].isAssignableFrom(cls)) {
val source = cls.newInstance().asInstanceOf[DataSourceV2]
source match {
case ws: WriteSupport =>
val sessionOptions = DataSourceV2Utils.extractSessionConfigs(
// ...
// Streaming also uses the data source V2 API. So it may be that the data source implements
// v2, but has no v2 implementation for batch writes. In that case, we fall back to saving
// as though it's a V1 source.
case _ => saveToV1Source()
In consequence, the batch writer will pass through KafkaWriter's write method presented before.
Apache Spark comes with end-to-end integration of Apache Kafka. You can read data from a topic, process it, and write to another topic. Under-the-hood, the integration is quite straightforward, and so despite the fact of supporting 2 API versions (V1, V2). The at-least-once delivery semantic is guaranteed by the same method, both versions uses the same cached producers whose management will probably be replaced in Spark 3.0.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Kafka sink in Structured Streaming here:
- WriteToDataSourceV2Exec [SPARK-22026][SQL] data source v2 write path A cached Kafka producer should not be closed if any task is using it.
Related blog posts:
- What's new in Apache Spark 3.0 - Apache Kafka integration improvements
- Apache Kafka source in Structured Streaming - "beyond the offsets"
- Apache Spark Structured Streaming and Apache Kafka offsets management
- org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start() explained
- Analyzing Structured Streaming Kafka integration - Kafka source
Previously I wrote few posts about #ApacheKafka data source in #ApacheSpark #StructuredStreaming. Today it's time to focus on the sink part ⏰ https://t.co/66Av9LgNIR
— Bartosz Konieczny (@waitingforcode) January 25, 2020