
If you read my blog post, you certainly noticed that very often I get lost on the internet. Fortunately, very often it helps me write blog posts. But the internet is not the only place where I can get lost. It also happens to me to do that with Apache Spark code and one of my most recent confusions was about FileSystem and FileContext classes.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Through this article I will share with you what is the difference between these 2 abstractions. Or maybe, there is no difference? The answer is just below.
In this article I will try to spot the differences between these 2 abstractions. Or maybe, there are no differences? The answer is just below.
Checkpoint refactoring
The files responsible for the checkpoint manager are there since the Apache Spark 2.4 release and SPARK-23966 where Tathagata Das made a major refactoring. The goal of SPARK-23966 was to improve the code readability and fix an important inconsistency issue for the checkpoint mechanism used by the default state store and metadata checkpointers (offset, commit, file sink, file source). To give you a better idea of the issue, below you can find the code responsible for the state store checkpointing before SPARK-23966:
private lazy val fs = baseDir.getFileSystem(hadoopConf)
private val tempDeltaFile = new Path(baseDir, s"temp-${Random.nextLong}")
private lazy val tempDeltaFileStream = compressStream(fs.create(tempDeltaFile, true))
private def commitUpdates(newVersion: Long, map: MapType, tempDeltaFile: Path): Path = {
synchronized {
val finalDeltaFile = deltaFile(newVersion)
// scalastyle:off
// Renaming a file atop an existing one fails on HDFS
// (http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/filesystem.html).
// Hence we should either skip the rename step or delete the target file. Because deleting the
// target file will break speculation, skipping the rename step is the only choice. It's still
// semantically correct because Structured Streaming requires rerunning a batch should
// generate the same output. (SPARK-19677)
// scalastyle:on
if (fs.exists(finalDeltaFile)) {
fs.delete(tempDeltaFile, true)
} else if (!fs.rename(tempDeltaFile, finalDeltaFile)) {
throw new IOException(s"Failed to rename $tempDeltaFile to $finalDeltaFile")
}
loadedMaps.put(newVersion, map)
finalDeltaFile
}
}
}
From the snippet, you can see that the writing logic consisted of 3 steps: creating a temporary file, writing all changes to it, and finally, renaming the temporary file to the final one. At first glance, it looks fine. Since the in-memory state is updated only after a successful write, we always end up with a consistent state between the in-memory state store and the checkpointed changes from the current version. However, the SPARK-23966 explains what's wrong with the rename operation in this approach:
1. HDFSOffsetMetadataLog - This uses a FileManager interface to use any implementation of `FileSystem` or `FileContext` APIs. It preferably loads `FileContext` implementation as FileContext of HDFS has atomic renames.
2. HDFSBackedStateStore (aka in-memory state store)
1. Writing a version.delta file - This uses FileSystem APIs only to perform a rename. This is incorrect as rename is not atomic in HDFS FileSystem implementation.
2. Writing a snapshot file - Same as above.
Before writing this blog post, I had been aware of the not atomic rename operation in cloud object store systems but hadn't had any idea of 2 APIs used by Apache Spark!
FileContext or FileSystem?
The interface defining the file checkpointing logic is CheckpointFileManager and it has 2 implementations. The first of them is FileContextBasedCheckpointFileManager and it works on top of Hadoop's FileContext API. It's the one providing the atomic rename in HDFS. The second implementation is FileSystemBasedCheckpointFileManager and it interacts with the FileSystem API. How does Apache Spark know which one to choose? The answer is hidden in the companion object of the interface, and more exactly in the create method defined below:
def create(path: Path, hadoopConf: Configuration): CheckpointFileManager = {
// here Spark tries to load a class from spark.sql.streaming.checkpointFileManagerClass
// If it's not empty; but let's focus here on the built-in classes!
// ...
try {
// Try to create a manager based on `FileContext` because HDFS's `FileContext.rename()
// gives atomic renames, which is what we rely on for the default implementation
// `CheckpointFileManager.createAtomic`.
new FileContextBasedCheckpointFileManager(path, hadoopConf)
} catch {
case e: UnsupportedFileSystemException =>
logWarning(
"Could not use FileContext API for managing Structured Streaming checkpoint files at " +
s"$path. Using FileSystem API instead for managing log files. If the implementation " +
s"of FileSystem.rename() is not atomic, then the correctness and fault-tolerance of" +
s"your Structured Streaming is not guaranteed.")
new FileSystemBasedCheckpointFileManager(path, hadoopConf)
}
As you can see, the prefered version is the one supporting the atomic renames and it's created when the UnsupportedFileSystemException isn't thrown. This exception can be thrown during the initialization of the FileContextBasedCheckpointFileManager when Apache Spark can't find the class corresponding to the used file system. Below you can find the initialization step:
class FileContextBasedCheckpointFileManager(path: Path, hadoopConf: Configuration)
extends CheckpointFileManager with RenameHelperMethods with Logging {
import CheckpointFileManager._
private val fc = if (path.toUri.getScheme == null) {
FileContext.getFileContext(hadoopConf)
} else {
FileContext.getFileContext(path.toUri, hadoopConf)
}
// ...
...and the exception:
public class FileContext {
public static FileContext getFileContext(final URI defaultFsUri,
final Configuration aConf) throws UnsupportedFileSystemException {
UserGroupInformation currentUser = null;
AbstractFileSystem defaultAfs = null;
if (defaultFsUri.getScheme() == null) {
return getFileContext(aConf);
}
// ...
}
public static FileContext getFileContext(final Configuration aConf)
throws UnsupportedFileSystemException {
final URI defaultFsUri = URI.create(aConf.get(FS_DEFAULT_NAME_KEY,
FS_DEFAULT_NAME_DEFAULT));
if ( defaultFsUri.getScheme() != null
&& !defaultFsUri.getScheme().trim().isEmpty()) {
return getFileContext(defaultFsUri, aConf);
}
throw new UnsupportedFileSystemException(String.format(
"%s: URI configured via %s carries no scheme",
defaultFsUri, FS_DEFAULT_NAME_KEY));
}
public static FileContext getFileContext(final URI defaultFsUri,
final Configuration aConf) throws UnsupportedFileSystemException {
UserGroupInformation currentUser = null;
AbstractFileSystem defaultAfs = null;
if (defaultFsUri.getScheme() == null) {
return getFileContext(aConf);
}
try {
currentUser = UserGroupInformation.getCurrentUser();
defaultAfs = getAbstractFileSystem(currentUser, defaultFsUri, aConf);
} catch (UnsupportedFileSystemException ex) {
throw ex;
// ...
}
public abstract class AbstractFileSystem {
private static AbstractFileSystem getAbstractFileSystem(
UserGroupInformation user, final URI uri, final Configuration conf)
throws UnsupportedFileSystemException, IOException {
try {
return user.doAs(new PrivilegedExceptionAction() {
@Override
public AbstractFileSystem run() throws UnsupportedFileSystemException {
return AbstractFileSystem.get(uri, conf);
}
});
// ...
}
public static AbstractFileSystem get(final URI uri, final Configuration conf)
throws UnsupportedFileSystemException {
return createFileSystem(uri, conf);
}
//
public static AbstractFileSystem createFileSystem(URI uri, Configuration conf)
throws UnsupportedFileSystemException {
final String fsImplConf = String.format("fs.AbstractFileSystem.%s.impl",
uri.getScheme());
Class<?> clazz = conf.getClass(fsImplConf, null);
if (clazz == null) {
throw new UnsupportedFileSystemException(String.format(
"%s=null: %s: %s",
fsImplConf, NO_ABSTRACT_FS_ERROR, uri.getScheme()));
}
return (AbstractFileSystem) newInstance(clazz, uri, conf);
}
And starting from here, I got confused.
FileSystem in FileContext?
As you can notice, FileContext also interacts with a FileSystem abstraction! Except that the underlying class representing the FileSystem is necessarily an implementation of AbstractFileSystem abstract class. Let's take a look on its implementation for S3:
public class FileContext {
private final AbstractFileSystem defaultFS; //default FS for this FileContext.
// ...
}
public abstract class DelegateToFileSystem extends AbstractFileSystem {
// ...
}
public class S3A extends DelegateToFileSystem{
public S3A(URI theUri, Configuration conf)
throws IOException, URISyntaxException {
super(theUri, new S3AFileSystem(), conf, "s3a", false);
}
@Override
public int getUriDefaultPort() {
return Constants.S3A_DEFAULT_PORT;
}
}
Surprised? I was. After all the FileContext can use exactly the same classes as FileSystem to access the underlying storage! Moreover, if you check what happens for the HDFS storage, you will notice that FileContext and FileSystem use the same DFSClient for the rename operation. The rename operation which by the way is a metadata operation executed by the NameNode, hence not involving any data blocks copy:
// DistributedFileSystem (FileSystem)
DFSClient dfs;
public boolean rename(Path src, Path dst) throws IOException {
statistics.incrementWriteOps(1);
final Path absSrc = fixRelativePart(src);
final Path absDst = fixRelativePart(dst);
// Try the rename without resolving first
try {
return dfs.rename(getPathName(absSrc), getPathName(absDst));
}
// Hdfs (FileContext)
DFSClient dfs;
public void renameInternal(Path src, Path dst)
throws IOException, UnresolvedLinkException {
dfs.rename(getUriPath(src), getUriPath(dst), Options.Rename.NONE);
}
Just for the record, the rename operation in S3AFileSystem is implemented as copy+delete:
private boolean innerRename(Path source, Path dest)
// ...
if (srcStatus.isFile()) {
LOG.debug("rename: renaming file {} to {}", src, dst);
long length = srcStatus.getLen();
if (dstStatus != null && dstStatus.isDirectory()) {
String newDstKey = maybeAddTrailingSlash(dstKey);
String filename =
srcKey.substring(pathToKey(src.getParent()).length()+1);
newDstKey = newDstKey + filename;
copyFile(srcKey, newDstKey, length);
S3Guard.addMoveFile(metadataStore, srcPaths, dstMetas, src,
keyToQualifiedPath(newDstKey), length, getDefaultBlockSize(dst),
username);
} else {
copyFile(srcKey, dstKey, srcStatus.getLen());
S3Guard.addMoveFile(metadataStore, srcPaths, dstMetas, src, dst,
length, getDefaultBlockSize(dst), username);
}
innerDelete(srcStatus, false);
}
// …
Let's back to the confusion, though. The first reason for my confusion was this coupling between FileContext and FileSystem. After searching a bit I found HADOOP-4952 which explains that FileContext is a newer and simpler API, hiding the underlying file system levels to the end user. It's quite clear if you compare them in the following slide coming from Sanjay Radia's presentation from 2009:
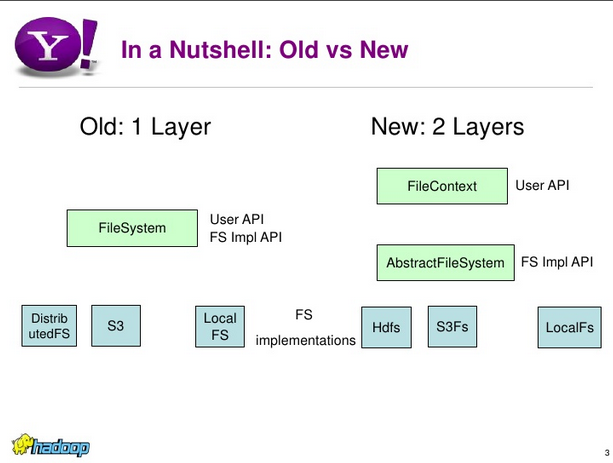
I understood even better this evolution after reading Steve Loughran's comment in SPARK-23966. The FileContext is the recommended approach but it's meant to be atomic as FileSystem for HDFS:
w.r.t FileContext.rename vs FileSystem.rename(), they are both meant to be atomic, and they are on: HDFS, local, posix-compliant DFS's. Whether any object store implements atomic and/or O(1) rename is always ambigiuous: depends on the store and even the path under the store (e.g wasb & locking-based exclusivity).
I would embrace FileContext for its better failure reporting of rename problems, but don't expect anything better atomically. For object stores, the strategy of "write in place" is better. Of course, now you are left with the problem of "when to know what to use". This plugin mech handles that, and when some variant of HADOOP-9565 gets in, there'll be a probe for the semantics of an FS path which could be use by some adaptive connector.
The difference and the reason for preferring FileContext became more clear after that! Nonetheless, I still wanted to see the operations relying on this atomic rename, so on FileContext or FileSystem API.
Atomic rename in Apache Spark
To understand the relationship between the rename operation and Structured Streaming metadata, we have to go back to the CheckpointFileManager, and more precisely, this class:
sealed class RenameBasedFSDataOutputStream(
fm: CheckpointFileManager with RenameHelperMethods,
finalPath: Path,
tempPath: Path,
overwriteIfPossible: Boolean)
extends CancellableFSDataOutputStream(fm.createTempFile(tempPath))
It exposes the createAtomic(path: Path, overwriteIfPossible: Boolean) method used by the checkpoint metadata and the state store writers to generate their checkpointed file atomically:
// BK: createAtomic is called via the CheckpointFileManager implementation
class HDFSBackedStateStore(val version: Long, mapToUpdate: MapType)
extends StateStore {
private lazy val deltaFileStream = fm.createAtomic(finalDeltaFile, overwriteIfPossible = true)
// ...
// BK: HDFSMetadataLog is used by file sink, file source, offset and commit metadata files
class HDFSMetadataLog[T <: AnyRef : ClassTag](sparkSession: SparkSession, path: String)
extends MetadataLog[T] with Logging {
def addNewBatchByStream(batchId: Long)(fn: OutputStream => Unit): Boolean = {
get(batchId).map(_ => false).getOrElse {
// Only write metadata when the batch has not yet been written
val output = fileManager.createAtomic(batchIdToPath(batchId), overwriteIfPossible = false)
try {
fn(output)
output.close()
// ...
The implementation of createAtomic is the same for both CheckpointFileManager implementations:
class FileSystemBasedCheckpointFileManager(path: Path, hadoopConf: Configuration)
extends CheckpointFileManager with RenameHelperMethods with Logging {
override def createAtomic(
path: Path,
overwriteIfPossible: Boolean): CancellableFSDataOutputStream = {
new RenameBasedFSDataOutputStream(this, path, overwriteIfPossible)
}
// ...
}
class FileContextBasedCheckpointFileManager(path: Path, hadoopConf: Configuration)
extends CheckpointFileManager with RenameHelperMethods with Logging {
override def createAtomic(
path: Path,
overwriteIfPossible: Boolean): CancellableFSDataOutputStream = {
new RenameBasedFSDataOutputStream(this, path, overwriteIfPossible)
}
// ...
}
Once the write terminates, the stream is closed and that's the place where the metadata file, so far temporary, is promoted to the final destination. Everything happens inside the close method presented below:
override def close(): Unit = synchronized {
try {
if (terminated) return
underlyingStream.close()
try {
fm.renameTempFile(tempPath, finalPath, overwriteIfPossible)
} catch {
case fe: FileAlreadyExistsException =>
logWarning(
s"Failed to rename temp file $tempPath to $finalPath because file exists", fe)
if (!overwriteIfPossible) throw fe
}
logInfo(s"Renamed temp file $tempPath to $finalPath")
} finally {
terminated = true
}
}
The renameTempFile(srcPath: Path, dstPath: Path, overwriteIfPossible: Boolean) is an abstract method implemented by FileSystem- or FileContext-based checkpoint managers and using the rename function mentioned above:
class FileSystemBasedCheckpointFileManager(path: Path, hadoopConf: Configuration)
extends CheckpointFileManager with RenameHelperMethods with Logging {
protected val fs = path.getFileSystem(hadoopConf)
override def renameTempFile(srcPath: Path, dstPath: Path, overwriteIfPossible: Boolean): Unit = {
// ...
if (!fs.rename(srcPath, dstPath)) {
// FileSystem.rename() returning false is very ambiguous as it can be for many reasons.
// This tries to make a best effort attempt to return the most appropriate exception.
if (fs.exists(dstPath)) {
if (!overwriteIfPossible) {
throw new FileAlreadyExistsException(s"Failed to rename as $dstPath already exists")
}
} else if (!fs.exists(srcPath)) {
throw new FileNotFoundException(s"Failed to rename as $srcPath was not found")
} else {
val msg = s"Failed to rename temp file $srcPath to $dstPath as rename returned false"
logWarning(msg)
throw new IOException(msg)
}
}
}
class FileContextBasedCheckpointFileManager(path: Path, hadoopConf: Configuration)
extends CheckpointFileManager with RenameHelperMethods with Logging {
private val fc = if (path.toUri.getScheme == null) {
FileContext.getFileContext(hadoopConf)
} else {
FileContext.getFileContext(path.toUri, hadoopConf)
}
override def renameTempFile(srcPath: Path, dstPath: Path, overwriteIfPossible: Boolean): Unit = {
import Options.Rename._
fc.rename(srcPath, dstPath, if (overwriteIfPossible) OVERWRITE else NONE)
// TODO: this is a workaround of HADOOP-16255 - remove this when HADOOP-16255 is resolved
mayRemoveCrcFile(srcPath)
}
}
The exploration was not easy. Initially, I thought that Apache Spark code base could provide enough explanation for the use of FileContext or FileSystem. However, after digging a bit and finding similarities presented in the article with DFSClient and S3 file system, I became more confused. Only HADOOP-4952 created by the end of 2008 shed some light on it. Or maybe, not completely. I'm wondering now if we couldn't simplify the code base by getting rid of the FileSystem-based checkpoint manager?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Checkpoint file manager - FileSystem and FileContext here:
- Refactoring all checkpoint file writing logic in a common interface atomic hadoop fs move NativeAzureFileSystem file rename is not atomic
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
FileSystem and FileContext are 2 APIs used to manage checkpoint files in #StructuredStreaming I was quite surprised to see them and decided to check it out in a new blog post ? https://t.co/wBRQaT7q2u
— Bartosz Konieczny (@waitingforcode) May 15, 2021