
If you've used Apache Kafka source in Structured Streaming, you undoubtedly noticed a property called maxOffsetsPerTrigger. According to the documentation, it helps to "limit on maximum number of offsets processed per trigger interval". My initial reaction to this property was, "Cool! We can enforce idempotent processing". I was not wrong, but the blog post will show you that I wasn't entirely right either!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
By "idempotent processing", I mean here the case of reprocessing where the application processes the same offsets as in the first execution. Since by default Apache Kafka partitions are mapped 1:1 to Apache Spark tasks, maxOffsetsPerTrigger should be the idempotent processing guarantee. However, through 3 different use cases, you will see in this blog post that it's not always true and it's not only related to Apache Spark.
Perfect use case
Let's start with the best use case. But before showing it, I will recall the purpose of maxOffsetsPerTrigger. If set, this value defines the total number of offsets to read across all Apache Kafka partitions. You will see the internal details in the last section but for now, let's assume that it divides the number of maxOffsetsPerTrigger by the number of Kafka partitions (it's not exactly true, keep reading to get the exact formula in the last part).
The code I will use for the demo is the same for all 3 use cases, except it will use different checkpoint location and different input topic:
object PerfectUseCaseConsolePrinterFromKafka extends App {
val sparkSession = SparkSession.builder()
.appName("Console printer from kafka").master("local[*]")
.getOrCreate()
val inputKafkaRecords = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:29092")
.option("subscribe", PerfectUseCaseTopicName)
.option("startingOffsets", "EARLIEST")
.option("maxOffsetsPerTrigger", 4)
.load()
.selectExpr("CAST(value AS STRING)")
val writeQuery = inputKafkaRecords
.writeStream
.option("checkpointLocation", PerfectUseCaseCheckpoint)
.format("console")
.option("truncate", false)
writeQuery.start().awaitTermination()
}
There is nothing complicated. The first use case is also pretty straightforward. I will simply start the broker and see what happens when I reprocess the data for the already processed micro-batches. Let me demonstrate that in the video below:
As you saw, if we replay the application multiple times, like in this demo, the processing becomes predictable and our consumer processes the same elements every time. Despite the difference with the first micro-batch, which is empty during the first execution and not empty at the replay.
Less perfect use case
Let's make now our use case more real. In the following picture, you can see how our producer generates the data. You can notice that one of the partitions got new data between the consumer executions. It'll lead to more data processed in the reprocessed micro-batch. You can find the proof for that in the video just below the picture:
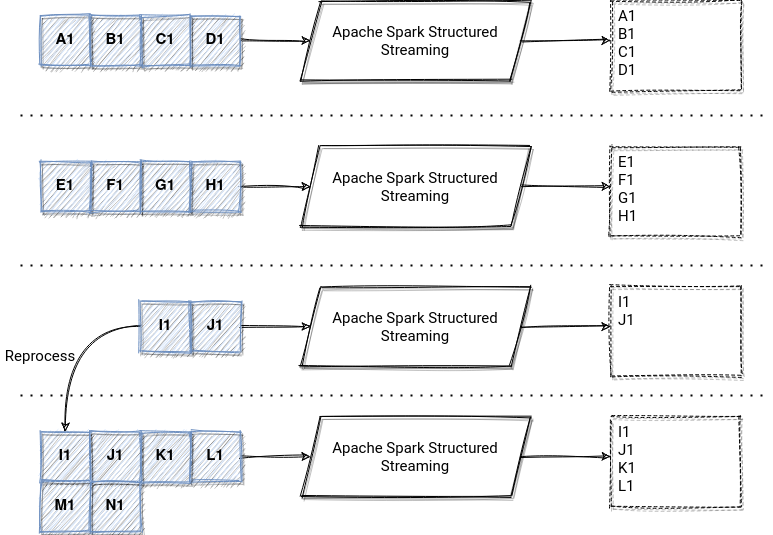
This time, we got slightly different data for the last micro-batch. Between the application stop and restart, the producer sent 4 new records and 2 of them were included in the maxOffsetsPerTrigger boundary.
Another less perfect use case
To terminate, let's see what happens with maxOffsetsPerTrigger and a quite aggressive compression on the topic:
As you could see, an aggressive topic compaction strategy also led to some inconsistencies. During the first execution, we processed "A2", "D2" and "G2" multiple times, whereas after replaying the application, they were present only once.
Why?
The last demo was a great occasion to introduce the internals of maxOffsetsPerTrigger. As you can see in the picture below, we could think that the reprocessed application should include E2 and F2 to the first micro-batch but it didn't happen!
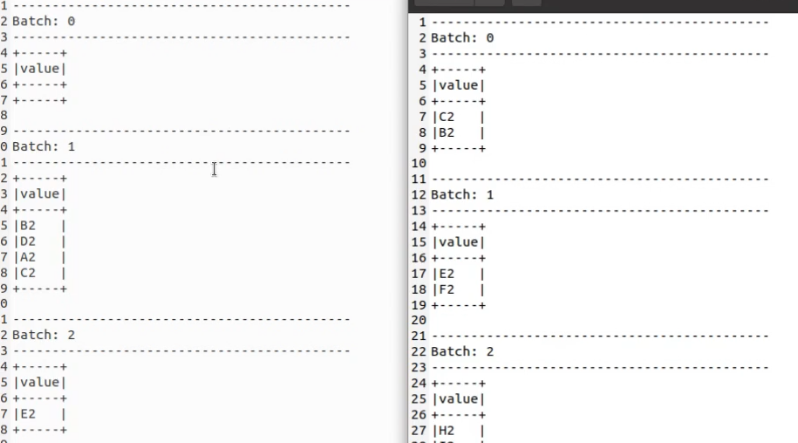
Why? Because of the compaction. The process doesn't change the offsets for the compacted records sharing the same key so in other words, the E2 and F2 didn't take the offsets of the compacted A2 and D2 records. Knowing that, we can ask another question. Does maxOffsetsPerTrigger can't figure out what records were compacted?
It can't because the equation generating the number of records to process looks like that. At the beginning, KafkaSource gets the last available offsets in every Kafka partition. It subtracts it from the first offset to process to get the size of every input partition:
private def rateLimit(
limit: Long,
from: Map[TopicPartition, Long],
until: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {
val fromNew = kafkaReader.fetchEarliestOffsets(until.keySet.diff(from.keySet).toSeq)
val sizes = until.flatMap {
case (tp, end) =>
// If begin isn't defined, something's wrong, but let alert logic in getBatch handle it
from.get(tp).orElse(fromNew.get(tp)).flatMap { begin =>
val size = end - begin
logDebug(s"rateLimit $tp size is $size")
if (size > 0) Some(tp -> size) else None
}
}
val total = sizes.values.sum.toDouble
The limit parameter of this method represents the maxOffsetsPerTrigger property. After this, rateLimit method generates the max offset to fetch for every partition by multiplying the maxOffsetsPerTrigger by the result of the division between the all new offsets available in the partition by the total number of new offsets across all partitions: limit * (size / total). Later, the result is rounded to the integer less than or equal to it.
/** Proportionally distribute limit number of offsets among topicpartitions */
private def rateLimit(
limit: Long,
from: Map[TopicPartition, Long],
until: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {
// ...
val begin = from.getOrElse(tp, fromNew(tp))
val prorate = limit * (size / total)
logDebug(s"rateLimit $tp prorated amount is $prorate")
// Don't completely starve small topicpartitions
val prorateLong = (if (prorate < 1) Math.ceil(prorate) else Math.floor(prorate)).toLong
// need to be careful of integer overflow
// therefore added canary checks where to see if off variable could be overflowed
// refer to [https://issues.apache.org/jira/browse/SPARK-26718]
val off = if (prorateLong > Long.MaxValue - begin) {
Long.MaxValue
} else {
begin + prorateLong
}
logDebug(s"rateLimit $tp new offset is $off")
// Paranoia, make sure not to return an offset that's past end
Math.min(end, off)
Below you can find an image summarizing this computation:
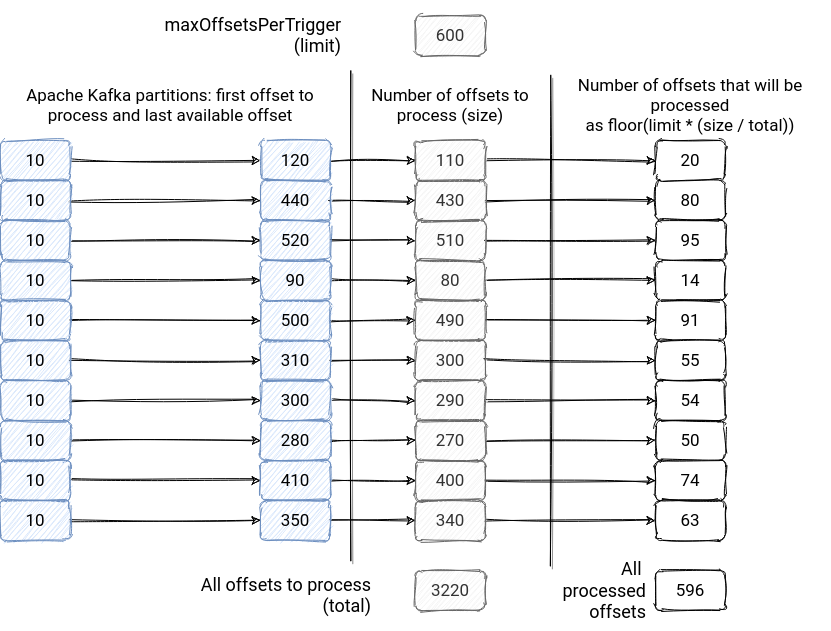
As you can see, the maxOffsetsPerTrigger doesn't guarantee an even distribution across all partitions, hence it doesn't protect against data skew. As you saw before, it doesn't guarantee the idempotency either. It can be broken by compaction or any new data that appeared after restarting the application. However, it's still a good way to control the throughput of the application. Apache Spark will take the last available offset without it, and it can become annoying very fast. Imagine a failed application that you restart after the week-end. Indeed, you will have to process all the events accumulated during the weekend!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Does maxOffsetsPerTrigger guarantee an idempotent processing in #StructuredStreaming? I've analyzed 3 different scenarios to see if it's always the case ? https://t.co/A3j8pD5z6d
— Bartosz Konieczny (@waitingforcode) July 3, 2021