
Structured Streaming micro-batch mode inherits a lot of features from the batch part. Apart from the retry mechanism presented previously, it also has the same auto-scaling logic relying on the Dynamic Resource Allocation.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Demo code
This time I will start with the demo code. As you can see, I'm using a simple RateStream of 10 partitions. Whenever a processed number is an even one, I'm sleeping the task to simulate some heavy work. To terminate, I'm also configuring the Dynamic Resource Allocation wait period for being very low (15 seconds), so that a new executor can be reclaimed very quickly in each micro-batch:
val inputStream = sparkSession.readStream.format("rate")
.option("numPartitions", 10)
.option("rowsPerSecond", 20)
.load()
val mappedStream = inputStream.as[(Timestamp, Long)].map {
case (_, nr) => {
if (nr % 9 == 0) {
logInfo(s"Sleeping for 1 minute because of the number ${nr}")
Thread.sleep(60000L)
}
nr
}
}
I ran this code on Kubernetes and you can see some commented effect just below:
What happened?
The dynamic resource allocation in Structured Streaming and in SQL shares the same logic. The class responsible for asking the cluster manager to add or remove executors is ExecutorAllocationManager. It communicates with the cluster manager via ExecutorAllocationClient which in my examples was implemented by KubernetesClusterSchedulerBackend.
The allocation manager uses a ExecutorAllocationListener to update the internal statistics about the jobs:
private val stageAttemptToNumTasks = new mutable.HashMap[StageAttempt, Int]
private val stageAttemptToNumRunningTask = new mutable.HashMap[StageAttempt, Int]
private val stageAttemptToTaskIndices = new mutable.HashMap[StageAttempt, mutable.HashSet[Int]]
private val stageAttemptToNumSpeculativeTasks = new mutable.HashMap[StageAttempt, Int]
private val stageAttemptToSpeculativeTaskIndices =
new mutable.HashMap[StageAttempt, mutable.HashSet[Int]]
private val resourceProfileIdToStageAttempt =
new mutable.HashMap[Int, mutable.Set[StageAttempt]]
private val unschedulableTaskSets = new mutable.HashSet[StageAttempt]
private val stageAttemptToExecutorPlacementHints =
new mutable.HashMap[StageAttempt, (Int, Map[String, Int], Int)]
The listener updates each of the above counters when a new stage or task starts and terminates. Later, at a regular interval, the allocation manager checks whether it should add or remove the executors, and communicates this outcome to the cluster manager by calling, respectively, requestTotalExecutors and decommissionExecutors/killExecutors. You can see this activity in the following logs where the driver requests 4 new executors to the Kubernetes cluster manager:
ExecutorAllocationManager: requesting updates: Map(0 -> TargetNumUpdates(4,5))
ExecutorPodsAllocator: Set total expected execs to {0=9}
ExecutorAllocationManager: Requesting 4 new executors because tasks are backlogged (new desired total will be 9 for resource profile id: 0)
ExecutorAllocationManager: Starting timer to add more executors (to expire in 15 seconds)
ExecutorPodsAllocator: ResourceProfile Id: 0 pod allocation status: 5 running, 0 pending. 0 unacknowledged.
ExecutorPodsAllocator: Going to request 4 executors from Kubernetes for ResourceProfile Id: 0, target: 9 running: 5.
ExecutorPodsAllocator: Requested executor with id 6 from Kubernetes.
ExecutorPodsAllocator: Requested executor with id 7 from Kubernetes.
ExecutorPodsAllocator: Requested executor with id 8 from Kubernetes.
ExecutorPodsAllocator: Requested executor with id 9 from Kubernetes.
ExecutorPodsAllocator: ResourceProfile Id: 0 pod allocation status: 5 running, 4 pending. 0 unacknowledged.
ExecutorPodsAllocator: Still waiting for 4 executors for ResourceProfile Id 0 before requesting more.
What can come next?
The dynamic resource allocation is a good way to add more parallelism to the job because it reduces the number of pending tasks due to the insufficient cluster capacity. It's a good strategy for batch jobs working on a fully known dataset. However, the streaming jobs are different. They're working on an unbounded dataset and have an extra goal to process the incoming events as soon as possible. In other words, the auto scaling strategy could optimise not only the parallelism but also the backlog size (= number of pending events).
Other data processing frameworks implement this backlog-based strategy. Apache Beam streaming readers implement a getBacklogBytes method used by the runners in the scaling action. For example, the Dataflow runner will add new workers to handle the increasing backlog. In the opposite situation when the backlog is lower than 10 seconds and the workers use on average less than 75% of the CPUs, it will remove the extra workers. As you can see, the goal here is to minimize the backlog while maximizing worker utilization.
Could we extend Structured Streaming by this backlog optimization part? Apache Kafka data source already has a property called minPartitions to "divide" the workload of big partitions. The property could be generalized to all streaming data sources and be used to dynamically adapt each micro-batch to the input workload by creating new tasks if the backlog grows too much. It could complete (scaling while executing the job) or include (scaling before starting the job) the existing Dynamic Resource Allocation strategy. The problem could appear later in the shuffle stage since the number of shuffle partitions is immutable for the whole Structured Streaming job and hence, we would put much more work on each shuffle task.
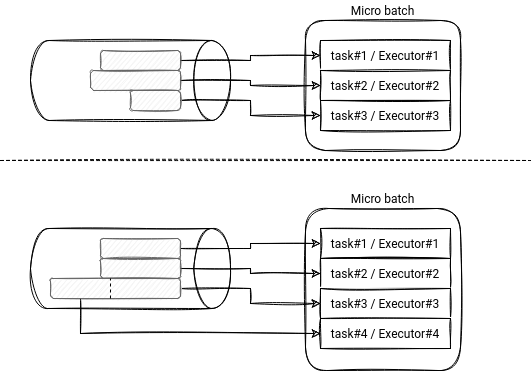
The idea from the last section is just theoretical, without any feasibility study. And extending the Dynamic Resource Allocation is not a new idea. There is already an existing task (SPARK-24815) covering that topic!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Dynamic resource allocation in Structured Streaming here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Does #StructuredStreaming support the Dynamic Resource Allocation? The answer with a short demo in the new blog post ? https://t.co/tK3qbyZVhV
— Bartosz Konieczny (@waitingforcode) March 5, 2022