
That's the question. The lack of the processing time trigger means more a reactive micro-batch triggering but it cannot be considered as the single true best practice. Let's see why.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
To understand the ins/outs, let's first remember what a processing time trigger in Apache Spark Structured Streaming is. Put differently, it defines how often a micro-batch should run. For example, a trigger of 1 minute will run a new micro-batch each minute and, ideally, it will process the last minute of data. Why "ideally"? Because if the micro-batch takes longer than 1 minute, you'll have more data.
What does it imply having a processing time-based trigger:
- Assuming an even data generation throughout a day, it involves processing roughly the same amount of data each time. You agree with me, it's not that frequent in real-life, is it?
- Easier observability. Having this static 1 minute interval, it's easier to monitor the job. You can pretty quickly spot any extra latency by just analyzing the trigger times.
- Saving network traffic costs for irregularly incoming data. If the data source doesn't get new data continuously, the processing time trigger can save some network costs by avoiding unnecessary offsets retrieval operations. Typically, if your Apache Kafka topic gets data every 15 seconds, for example from another Structured Streaming job with the processing time enabled, running new micro-batches continuously (without the trigger), doesn't make sense.
Pretty nice, isn't it? Indeed, but this trigger seems to be strongly tied to the micro-batch model, so to the data arriving in micro-batches. But we all know, in streaming and real-time systems it's hard to get such a guarantee. So what happens if, for such use cases, the job doesn't have the processing time trigger?
Job without processing time trigger
What happens if the job doesn't have a processing time trigger? The micro-batch starts as soon as possible after the previously completed one. The details are in the ProcessingTimeExecutor:
case class ProcessingTimeExecutor(processingTimeTrigger: ProcessingTimeTrigger, clock: Clock = new SystemClock()) extends TriggerExecutor with Logging {
// ...
private val intervalMs = processingTimeTrigger.intervalMs
require(intervalMs >= 0)
override def execute(triggerHandler: () => Boolean): Unit = {
while (true) {
val triggerTimeMs = clock.getTimeMillis
val nextTriggerTimeMs = nextBatchTime(triggerTimeMs)
val terminated = !triggerHandler()
if (intervalMs > 0) {
val batchElapsedTimeMs = clock.getTimeMillis - triggerTimeMs
if (batchElapsedTimeMs > intervalMs) {
notifyBatchFallingBehind(batchElapsedTimeMs)
}
if (terminated) {
return
}
clock.waitTillTime(nextTriggerTimeMs)
} else {
if (terminated) {
return
}
}
}
}
def nextBatchTime(now: Long): Long = {
if (intervalMs == 0) now else now / intervalMs * intervalMs + intervalMs
}
The highlighted part shows the code responsible for micro-batch execution without the trigger. As you can see the query is first blocked by the triggerHandler(). In other words, nothing happens as long as the micro-batch is running. Only as soon as the micro-batch completes, the trigger goes to the else part and immediately starts the new loop iteration. It's not the case of the processing time trigger where you can see thread blocking until the next planned schedule (clock.waitTillTime(nextTriggerTimeMs)).
Comparison
To see what happens when there is no trigger associated with a Structured Streaming query. In the image below you can see four different scenarios, all processing the data generated every minute:
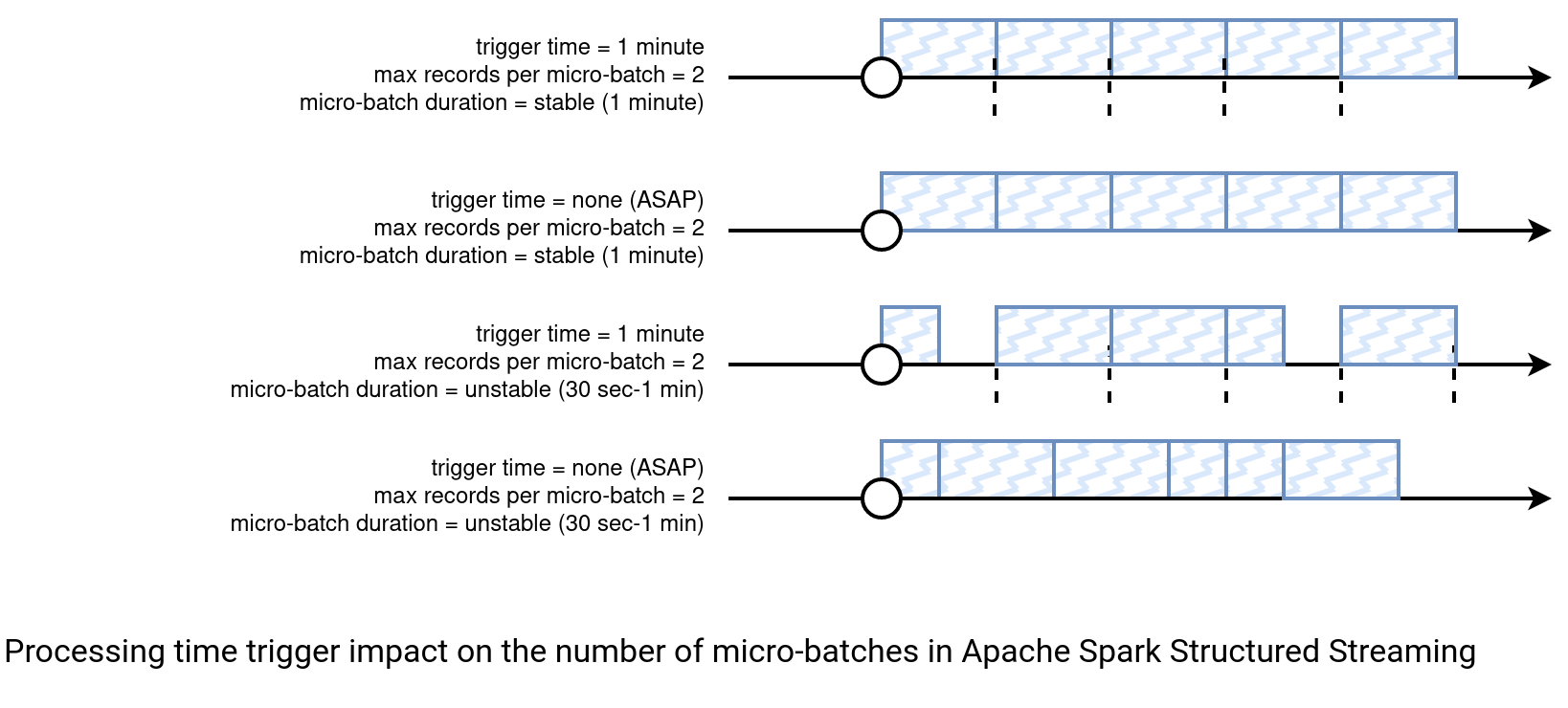
The best case scenario is when the data volume processed in each micro-batch is constant. It's the case for the first two configurations. They suppose a constant micro-batch execution time for simplicity but it's rarely the case! For that reason, take a look at the next two examples. They assume an execution time range between 30 seconds and 1 minute. For the job with the missing trigger defined you can see that it reduces the processing latency. It's not the case for the trigger job where the resources are not fully used.
Of course, it is only an example taking some numbers to better illustrate the impact of the trigger on the job execution. 99%, it won't reflect your production use case when the data generation flow will be more unpredictable.
For that unpredictability for both input data but also output requirements, I won't give you an answer here and say "use the trigger" or "do not use the trigger". Instead, there are some points that you might consider while deciding the configuration. I already shared the ones for the trigger, so let's see now when this trigger-less execution could be useful? There are three major impacts:
- Data sink I/O. With a regular trigger the database will get an I/O hit at more regular intervals, maybe leading into some requests throttling. Without a trigger there is a chance the write will distribute differently and instead of having a heavy operation once each trigger interval, the data sink will handle several consecutive lightweight operations. On the other hand, this will not work great for file systems or object stores because it can easily lead to small file problems. It might also not be optimal for writing OLAP systems, such as data warehouses, where bulk requests can often optimize the storage and the I/O overhead, for example by better compacting or sorting the rows at writing. However, if you're writing data into a streaming broker, there is no such a problem.
- Latency. Obviously, the job processes new data at a lower latency because there is no trigger overhead that might cause a delay between 2 consecutive micro-batches. It's particularly visible if the micro-batch completes earlier than the next trigger.
- Resources optimization. The latency and this point only apply when there is a big difference between the micro-batch duration and the trigger time. For example, if a batch spends 30 seconds on processing the data and the trigger is set to 2 minutes, there will be 1.5 minutes of the unused compute power. As a single unit it seems innocent but if you sum this, it'll be 40 minutes per hour and 960 minutes per day. You can see an example in the previous schema for the last two discussed scenarios.
On the other hand, not having the processing time trigger will:
- Add some unpredictability. You don't know if the job will run every minute. Sometimes you might have 2 or 3 runs per minute, other times only 1. Below you can find an example where a job processes files:
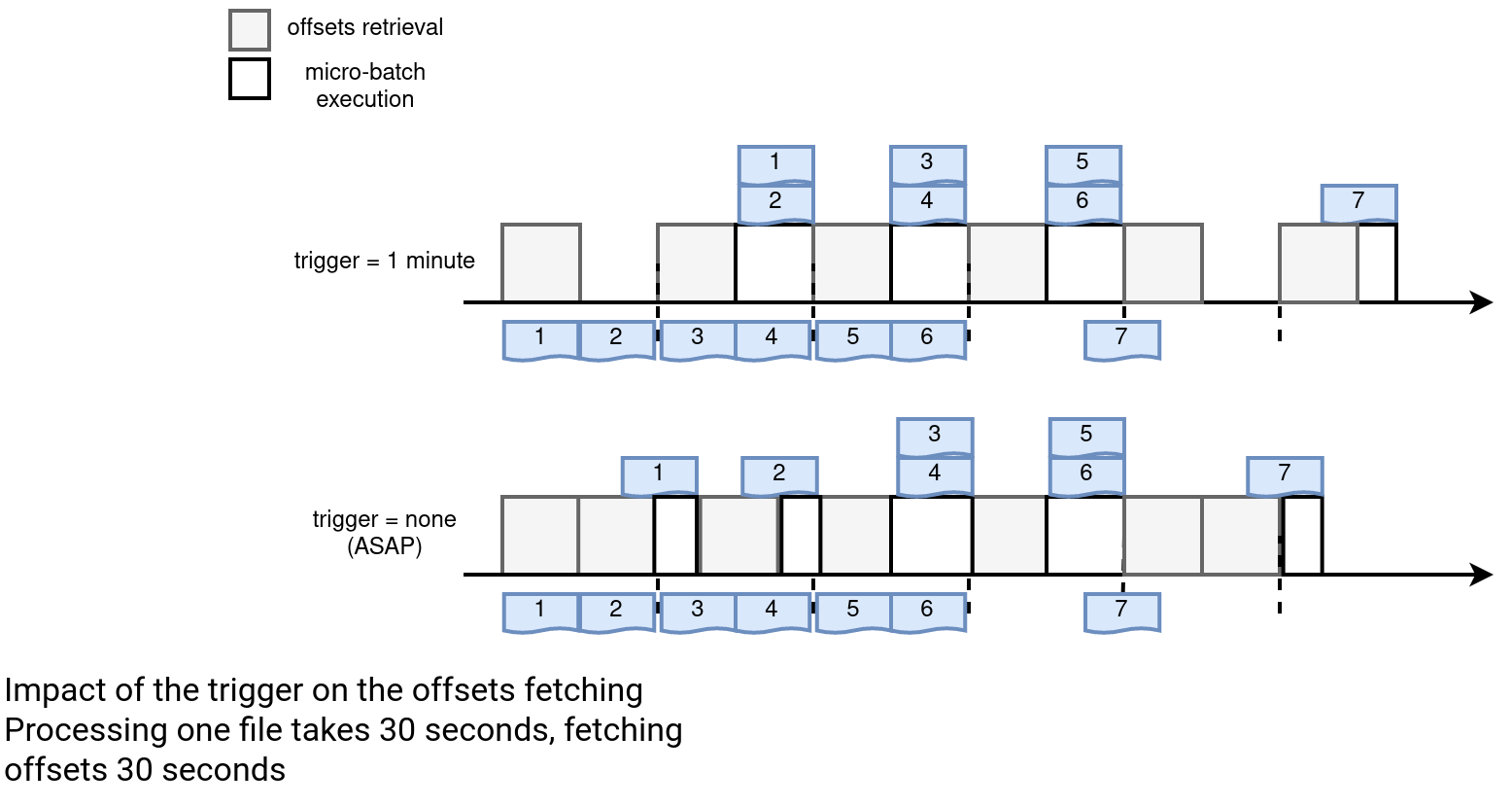 As you can see, the trigger version regularly processes the same number of files whereas the one without the trigger sometimes works on a single file. However, as you can see in our imaginary example, the file number 7 is processed earlier by the latter job version.
As you can see, the trigger version regularly processes the same number of files whereas the one without the trigger sometimes works on a single file. However, as you can see in our imaginary example, the file number 7 is processed earlier by the latter job version.
- Do smaller I/O operations. It's valid for the data sink point from the previous list but also for any I/O sensitive task within the micro-batch itself, such as bulk requests for data enrichment purposes. Having more data to enrich at once might reduce the number of requests because maybe there are some entries having the same enrichment requirement.
- Make more offset retrieval requests. If this operation is heavy, like listing objects in an object store, it might be better to do it rarely, hence use the trigger.
- Impact checkpointing operation for costly operations, such as stream-to-stream joins. Having the micro-batch running more often will perform more interactions with the checkpoints. It can be particularly impactful for the stateful operations if the multiple writes are more costly as if there was a single call.
So be or not to be, a query with a trigger? It depends. You should always apply any recommendation to your use case.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩