
Some time ago I was asked by Sunil whether it was possible to load the initial state in Apache Spark Structured Streaming like in DStream-based API. Since the response was not obvious, I decided to investigate and share the findings through this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post starts with a short reminder of the state initialization in Apache Spark Streaming module. The next sections talk about the methods you can use to do the same in Apache Spark Structured Streaming library.
Initializing state in Streaming
Initializing the state in the DStream-based library is straightforward. You simply need to create a key-based RDD and pass it to StateSpec's initialState method:
"streaming processing" should "start with initialized state" in {
val conf = new SparkConf().setAppName("DStream initialState test").setMaster("local[*]")
val streamingContext = new StreamingContext(conf, Durations.seconds(1))
streamingContext.checkpoint("/tmp/spark-initialstate-test")
val dataQueue = new mutable.Queue[RDD[OneVisit]]()
// A mapping function that maintains an integer state and return a UserVisit
def mappingFunction(key: String, value: Option[OneVisit], state: State[UserVisit]): Option[(String, String)] = {
var visitedPages = state.getOption().map(userVisitState => userVisitState.visitedPages)
.getOrElse(Seq.empty)
value.map(visit => visit.page).foreach(page => visitedPages = visitedPages :+ page)
state.update(UserVisit(key, visitedPages))
Some((key, visitedPages.mkString(", ")))
}
val initialStateRdd = streamingContext.sparkContext.parallelize(Seq(
UserVisit("a", Seq("page1", "page2", "page3")),
UserVisit("b", Seq("page4")),
UserVisit("c", Seq.empty)
)).map(visitState => (visitState.userId, visitState))
val visits = Seq(
OneVisit("a", "page4"), OneVisit("b", "page5"), OneVisit("b", "page6"),
OneVisit("a", "page7")
)
visits.foreach(visit => dataQueue += streamingContext.sparkContext.makeRDD(Seq(visit)))
val stateSpec = StateSpec.function(mappingFunction _)
.initialState(initialStateRdd)
InMemoryKeyedStore.allValues.clear()
streamingContext.queueStream(dataQueue)
.map(visit => (visit.userId, visit))
.mapWithState(stateSpec)
.foreachRDD(rdd => {
rdd.collect().foreach {
case Some((userId, pages)) => InMemoryKeyedStore.addValue(userId, pages)
}
})
streamingContext.start()
streamingContext.awaitTerminationOrTimeout(10000)
InMemoryKeyedStore.getValues("a") should have size 2
InMemoryKeyedStore.getValues("a") should contain allOf("page1, page2, page3, page4", "page1, page2, page3, page4, page7")
InMemoryKeyedStore.getValues("b") should have size 2
InMemoryKeyedStore.getValues("b") should contain allOf("page4, page5", "page4, page5, page6")
}
Under-the-hood, the DStream stateful operation works on a MapWithStateRDD and the initial state is simply considered as the input RDD in the stateful computation:
/** Method that generates an RDD for the given time */
override def compute(validTime: Time): Option[RDD[MapWithStateRDDRecord[K, S, E]]] = {
// Get the previous state or create a new empty state RDD
val prevStateRDD = getOrCompute(validTime - slideDuration) match {
case Some(rdd) =>
if (rdd.partitioner != Some(partitioner)) {
// If the RDD is not partitioned the right way, let us repartition it using the
// partition index as the key. This is to ensure that state RDD is always partitioned
// before creating another state RDD using it
MapWithStateRDD.createFromRDD[K, V, S, E](
rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime)
} else {
rdd
}
case None =>
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)
}
Initializing state in Structured Streaming - stream-static join
My first thought about the initializing state in Structured Streaming oriented to the API. But unfortunately I didn't find any method to bootstrap the computation state. Because of that I tried first to implement the state management by combining the datasets. The first working version used a stream-static left join:
private val MappingFunctionJoin: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (key, values, state) => {
val materializedValues = values.toSeq
val defaultState = materializedValues.headOption.map(row => Seq(row.getAs[String]("state_name"))).getOrElse(Seq.empty)
val stateNames = state.getOption.getOrElse(defaultState)
val stateNewNames = stateNames ++ materializedValues.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be initialized with a join" in {
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("state_id", "state_name")
val testKey = "state-load-join"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
inputStream.addData((1L, "page1"), (2L, "page2"))
val initialDataset = inputStream.toDS().toDF("id", "name")
val joinedDataset = initialDataset.join(stateDataset, $"id" === $"state_id", "left")
val query = joinedDataset.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunctionJoin)
.writeStream
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 2
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2, page2", "old_page1, page1")
}
Even though it worked as expected, I was not satisfied. First, the mapping function became more complex. It was not anymore a simple state accumulation function because it needed to manage the state initialization too. Also, the solution required to keep the static dataset in memory all the time - even when the initial state was not needed. Because of these 2 drawbacks, I turned out into another approach based on the state checkpointing.
Initializing state in Structured Streaming - checkpoint
In Structured Streaming you can define a checkpointLocation option in order to improve the fault-tolerance of your data processing. When the checkpoint directory is defined, the engine will first check whether there are some data to restore before restarting the processing. And among the data to restore, you will find the state accumulated during the previous execution.
The idea is, with much or less effort, to transform the initial state stored maybe in some NoSQL or relational store, into the checkpointed state used by the streaming processing:
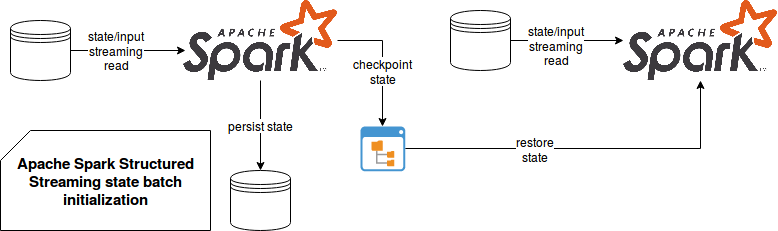
Aside from the state, the checkpoint also stores the information about the data source. And since the sources used for the state initialization and streaming processing may be different, it's pretty dangerous to mix them and like you will see later, it won't work correctly. On the other side, state manipulation has more flexible semantic according to the documentation:
"Any change to the schema of the user-defined state and the type of timeout is not allowed. Any change within the user-defined state-mapping function are allowed, but the semantic effect of the change depends on the user-defined logic."
As I mentioned before, this solution, or rather a hack, works fine when the data source is the same for the initialization and the real processing step. It's much harder to implement for the incompatible sources. Therefore, even though that hack looks very similar to the DStream initial state, it's not advised because of the checkpointing semantics. Unless you are sure to have the same data sources and that by chance will be consistent across query runs. You can observe both points in the following test cases illustrating compatibility and incompatibility:
private val MappingFunction: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (_, values, state) => {
val stateNames = state.getOption.getOrElse(Seq.empty)
val stateNewNames = stateNames ++ values.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be initialized for the same data source" in {
val testKey = "state-init-same-source-mode"
val checkpointDir = s"/tmp/batch-checkpoint${System.currentTimeMillis()}"
val schema = StructType(
Seq(StructField("id", DataTypes.LongType, false), StructField("name", DataTypes.StringType, false))
)
val sourceDir = "/tmp/batch-state-init"
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("id", "name")
stateDataset.write.mode(SaveMode.Overwrite).json(sourceDir)
val stateQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(",")))
.start()
stateQuery.awaitTermination(45000)
stateQuery.stop()
val newInputData = Seq((1L, "page1"), (2L, "page2")).toDF("id", "name")
newInputData.write.mode(SaveMode.Overwrite).json(sourceDir)
val fileBasedQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
fileBasedQuery.awaitTermination(45000)
fileBasedQuery.stop()
InMemoryKeyedStore.getValues(testKey) should have size 4
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2", "old_page1",
"old_page2, page2", "old_page1, page1" )
}
"the state" should "not be initialized for different data sources" in {
val testKey = "state-init-different-source-mode"
val checkpointDir = s"/tmp/batch-checkpoint${System.currentTimeMillis()}"
val schema = StructType(
Seq(StructField("id", DataTypes.LongType, false), StructField("name", DataTypes.StringType, false))
)
val sourceDir = "/tmp/batch-state-init"
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("id", "name")
stateDataset.write.mode(SaveMode.Overwrite).json(sourceDir)
val stateQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", checkpointDir)
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(",")))
.start()
stateQuery.awaitTermination(45000)
stateQuery.stop()
// Cleans the checkpoint location and keeps only the state files
cleanCheckpointLocation(checkpointDir)
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val inputDataset = inputStream.toDS().toDF("id", "name")
inputStream.addData((1L, "page1"), (2L, "page2"))
val mappedValues = inputDataset
.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
val query = mappedValues.writeStream.outputMode("update")
.option("checkpointLocation", checkpointDir)
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(","))).start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 4
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page2", "old_page1", "page2", "page1")
}
private def cleanCheckpointLocation(checkpointDir: String): Unit = {
FileUtils.deleteDirectory(new File(s"${checkpointDir}/commits"))
FileUtils.deleteDirectory(new File(s"${checkpointDir}/offsets"))
FileUtils.deleteDirectory(new File(s"${checkpointDir}/sources"))
new File(s"${checkpointDir}/metadata").delete()
}
Initializing state in Structured Streaming - direct lookup
After the unsuccessful checkpoint tries I decided to turn toward a much simpler solution. The mapping function defined in the previous section creates an empty sequence for every key seen for the first time. However, we can approach the problem from another side and instead of loading the whole state within a batch, we can load it only when it's needed. Of course, it doesn't fit the case when the initial state contains some information that we want output even though there are no new data about it. But at least that solution is much cleaner than the previous one hacking the checkpoints system.
The new mapping function looks like in the following snippet. Instead of returning an empty sequence, it looks for the data in some key-value store, or any other store guaranteeing O(1) lookup:
private val MappingFunctionKeyValueLoad: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (key, values, state) => {
val stateNames = state.getOption.getOrElse(KeyValueStore.State(key))
val stateNewNames = stateNames ++ values.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be loaded with key-value store" in {
val testKey = "state-load-key-value"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
inputStream.addData((1L, "page1"), (2L, "page2"), (1L, "page3"))
val initialDataset = inputStream.toDS().toDF("id", "name")
val query = initialDataset.groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunctionKeyValueLoad)
.writeStream
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(", ")))
.start()
query.awaitTermination(60000)
InMemoryKeyedStore.getValues(testKey) should have size 2
InMemoryKeyedStore.getValues(testKey) should contain allOf("old_page1, page2",
"old_page1, old_page2, page1, page3")
}
Among the iterated solutions, this one seems the easiest. Unlike JOIN-based approach, it doesn't persist the data when it's not required anymore. Also, it won't try to hack the semantics of Structured Streaming library, like the proposal using the checkpoints. On the other side, it could require some extra pre-processing step to put the data into a key-value store. In addition, it won't generate the records which don't have any new incoming data and therefore may be not acceptable by some pipelines where the state must be fully recovered.
Initializing the state could be pretty useful in all scenarios requiring data reprocessing. For instance, if you have some stateful processing on some Kafka topic and you must to switch the data source and, for instance, consume the data from another streaming broker system, it can be difficult to do with the current implementation. As stated in the documentation, "changes to subscribed topics/files are generally not allowed as the results are unpredictable". Without an easy way to move the state, such scenarios will be difficult to achieve. Of course, you can use one of the described approaches but they're rather the hacks than built-in solutions like DStream's initialState.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Initializing state in Structured Streaming here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Last days I have been playing with #ApacheSpark #StructuredStreaming state initialization to find a way to imitate the DStream initialState behavior. In the today's post I cover some of analyzed solutions (joins, checkpoints hack and k/v store): https://t.co/1ctZULPk7l
— Bartosz Konieczny (@waitingforcode) February 27, 2019