
Unit tests are the backbone of modern software but they only verify a particular unit of the application. What to do if we wanted to check the interaction between all these units? One of the solutions are automated integration tests. While they are relatively easy to implement against data in-rest, they are more challenging for streaming scenarios.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Broad and narrow integration tests
Martin Fowler defines the integration tests as:
The point of integration testing, as the name suggests, is to test whether many separately developed modules work together as expected. It was performed by activating many modules and running higher level tests against all of them to ensure they operated together. These modules could parts of a single executable, or separate.
Does it mean we should then test the steps from the ingestion pipeline to the data exposition layer in data architectures? Yes, if we consider the integration tests in terms of broad tests. It's another term shared by Martin Fowler about the integration tests. It describes the scenario requiring all parts of the pipeline up and ready.
On the opposite side, Martin Fowler defines narrow tests. Their name comes from the "narrow" word because instead of having a single big test case, narrow tests are a group of multiple narrowly scoped tests, often sharing a similar scope to the unit tests.
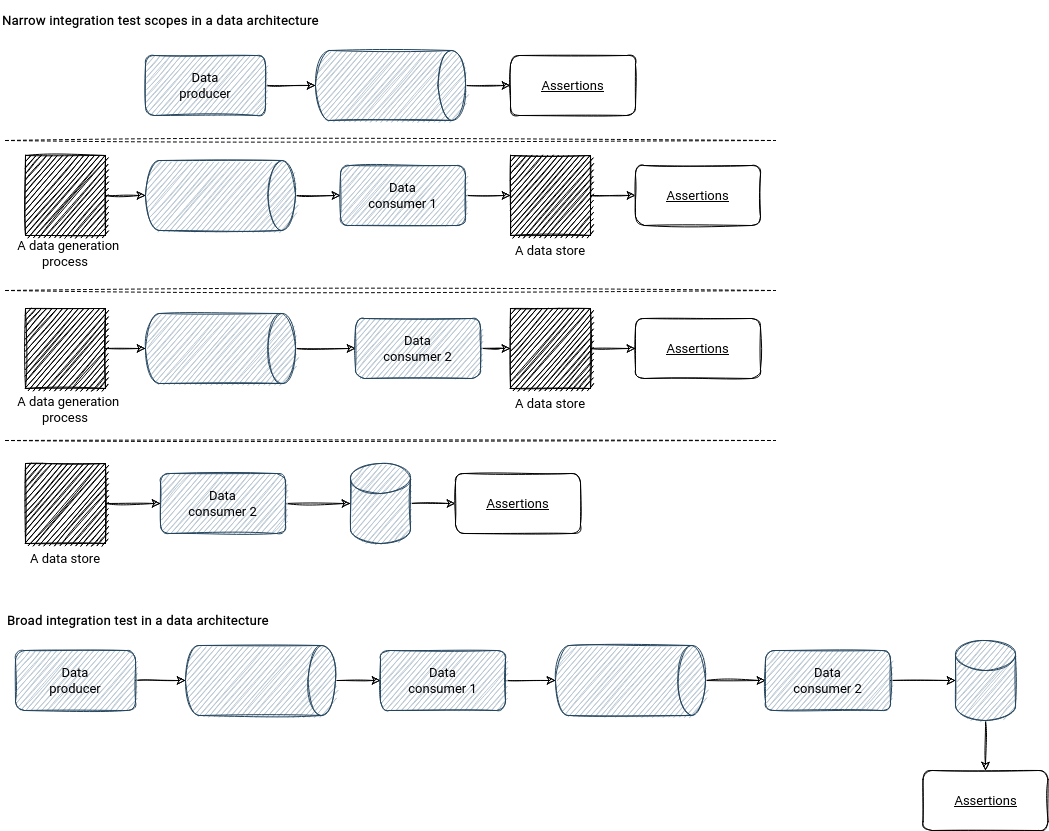
The risk of narrow tests is desynchronizing with the real world. For example, the Data consumer 1 from the picture could work on an old data schema and still not be able to detect the issues. To reduce this risk, Martin Fowler introduces a concept of contract tests that compares the schema of the test component with the schema from the production environment.
A good integration test
A good integration test should be:
- Predictable. The last thing you want is a randomly failing test. When it happens first, you'll look for the code errors, but next time, you'll probably ignore the error.
- Readable. There is nothing worse than an unreadable test case. To keep the tests readable and maintainable, you won't ingest millions of test records in the integration test scenario. If you want to check the throughput, you should consider performance testing.
- (relatively) Fast. Due to the usage of real data stores, the integration tests will take more time than unit tests. However, they shouldn't be too long to run and get feedback.
- Isolated. Running multiple integration tests in parallel can accelerate the testing phase. Therefore, each test case should be correctly isolated.
- Relevant. Executing integration tests against obsolete input data won't give you the extra delivery confidence. Instead, it'll be a false hope that everything will work great after the deployment on production. You should ensure that the integration test dataset follows the changes made on the input. How? You can automatically compare the test dataset with the production data. If you have a schema registry, it should be easy. Otherwise, you can add an acceptance criterion to evolve the test schema when the production schema changes.
However, writing integration tests is not easy. It's hard to find a good and automated way to generate input data synchronized with the production. Besides a DSL and the contract tests, I haven't found a better approach. Additionally, they're also challenging for some streaming scenarios, especially the timely and stateful processing jobs.
Are you ready for the coding section? If yes, let's move on to the next part where you will see a test example for a Structured Streaming job.
Integration test for Structured Streaming
I wanted to simulate integration tests for an Apache Kafka data processing job that dispatches the data to the topics with valid and invalid data. The job itself is very straightforward, but please notice that it's quite extensible. This extensibility is the key for the integration test logic:
object DataDispatcher {
private val objectMapper = new ObjectMapper()
objectMapper.registerModule(DefaultScalaModule)
def main(args: Array[String]) = {
val dataDispatcherConfig = objectMapper.readValue(args(0), classOf[DataDispatcherConfig])
val sparkSession = SparkSession.builder()
.appName("Data dispatcher").master("local[*]")
.getOrCreate()
val inputKafkaRecords = getInputTopicDataFrame(sparkSession, dataDispatcherConfig)
.selectExpr("CAST(CAST(key AS STRING) AS INT)", "CAST(value AS STRING)")
// It's a dummy logic. Obviously a production code could be more complex
// and the business logic functions should be then unit tested.
val dataWithTopicName = inputKafkaRecords.withColumn("topic", functions.when(
inputKafkaRecords("key") % 2 === 0, dataDispatcherConfig.invalidDataTopic
).otherwise(dataDispatcherConfig.validDataTopic))
.selectExpr("CAST(key AS STRING)", "value", "topic")
val writeQuery = dataWithTopicName
.writeStream
.option("checkpointLocation", dataDispatcherConfig.checkpointLocation)
.format("kafka")
.option("kafka.bootstrap.servers", dataDispatcherConfig.bootstrapServers)
if (dataDispatcherConfig.isIntegrationTest) {
writeQuery.start().awaitTermination(30000L)
} else {
writeQuery.start().awaitTermination()
}
}
private def getInputTopicDataFrame(sparkSession: SparkSession, dataDispatcherConfig: DataDispatcherConfig): DataFrame = {
sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", dataDispatcherConfig.bootstrapServers)
.option("subscribe", dataDispatcherConfig.inputTopic.name)
.options(dataDispatcherConfig.inputTopic.extra)
.load()
}
}
case class DataDispatcherConfig(bootstrapServers: String, inputTopic: InputTopicConfig,
validDataTopic: String,
invalidDataTopic: String,
checkpointLocation: String,
isIntegrationTest: Boolean = false)
case class InputTopicConfig(name: String, extra: Map[String, String] = Map.empty)
To implement an integration test, you can use different approaches. Depending on the trade-off you can make (performance vs. reliability), you can create a test topic on your test environment, ingest the data, and run the processing job locally or from a cluster, depending on the trade-off you can make (performance vs. reliability). For my case, I'm assuming that the performance and simplicity are most important. That's why I'm running the test with Scalatest and a local Docker image:
private var kafkaContainer: KafkaContainer = _
private lazy val bootstrapServers = kafkaContainer.getBootstrapServers
private lazy val commonConfiguration = {
val props = new Properties()
props.setProperty("bootstrap.servers", bootstrapServers)
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("auto.offset.reset", "earliest")
props.setProperty("group.id", "standard_client")
props
}
private val inputTopicName = "input"
private val validDataTopicName = "topic_valid"
private val invalidDataTopicName = "topic_invalid"
private val checkpointLocation = "/tmp/spark-it/checkpoint"
private val objectMapper = new ObjectMapper()
objectMapper.registerModule(DefaultScalaModule)
before {
println("Starting Kafka")
kafkaContainer = new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:6.2.1"))
kafkaContainer.start()
println("Creating topics")
val kafkaAdmin = AdminClient.create(commonConfiguration)
val topicsToCreate = Seq(inputTopicName, invalidDataTopicName, validDataTopicName).par
topicsToCreate.foreach(topic => {
kafkaAdmin.createTopics(Seq(new NewTopic(topic, 3, 1.toShort)).asJava)
})
println("Sending data")
val kafkaProducer = new KafkaProducer[String, String](commonConfiguration)
(0 to 6).foreach(id => kafkaProducer.send(new ProducerRecord[String, String](inputTopicName, s"${id}",
s"v${id}")))
kafkaProducer.flush()
FileUtils.deleteDirectory(new File(checkpointLocation))
}
after {
println("Stopping Kafka")
kafkaContainer.stop()
}
"data dispatcher" should "copy invalid records to topic_invalid and valid records to topic_valid" in {
val dataDispatcherConfig = DataDispatcherConfig(
bootstrapServers = bootstrapServers,
inputTopic = InputTopicConfig(name = inputTopicName,
extra = Map("startingOffsets" -> "EARLIEST", "maxOffsetsPerTrigger" -> "2")),
validDataTopic = validDataTopicName, invalidDataTopic = invalidDataTopicName,
checkpointLocation = checkpointLocation,
isIntegrationTest = true
)
val configJson = objectMapper.writeValueAsString(dataDispatcherConfig)
val dataDispatcher = DataDispatcher.main(Array(configJson))
val dataConsumer = new KafkaConsumer[String, String](commonConfiguration)
dataConsumer.subscribe(Seq(validDataTopicName, invalidDataTopicName).asJava)
val data = dataConsumer.poll(Duration.ofSeconds(30))
val dispatchedRecords = data.asScala.groupBy(record => record.topic())
.map {
case (topic, records) => (topic, records.map(record => (record.key(), record.value())))
}
dispatchedRecords(validDataTopicName) should have size 3
dispatchedRecords(validDataTopicName) should contain allOf (
("1", "v1"), ("3", "v3"), ("5", "v5")
)
dispatchedRecords(invalidDataTopicName) should have size 4
dispatchedRecords(invalidDataTopicName) should contain allOf (
("0", "v0"), ("2", "v2"), ("4", "v4"), ("6", "v6")
)
}
Let me go through the code and explain it a bit. At the beginning I'm creating a new test context. It covers the isolation and, I hope, the readability point of the good integration test checklist:
private var kafkaContainer: KafkaContainer = _
private lazy val bootstrapServers = kafkaContainer.getBootstrapServers
private lazy val commonConfiguration = {
val props = new Properties()
props.setProperty("bootstrap.servers", bootstrapServers)
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("auto.offset.reset", "earliest")
props.setProperty("group.id", "standard_client")
props
}
private val inputTopicName = "input"
private val validDataTopicName = "topic_valid"
private val invalidDataTopicName = "topic_invalid"
private val checkpointLocation = "/tmp/spark-it/checkpoint"
private val objectMapper = new ObjectMapper()
objectMapper.registerModule(DefaultScalaModule)
before {
println("Starting Kafka")
kafkaContainer = new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:6.2.1"))
kafkaContainer.start()
println("Creating topics")
val kafkaAdmin = AdminClient.create(commonConfiguration)
val topicsToCreate = Seq(inputTopicName, invalidDataTopicName, validDataTopicName).par
topicsToCreate.foreach(topic => {
kafkaAdmin.createTopics(Seq(new NewTopic(topic, 3, 1.toShort)).asJava)
})
println("Sending data")
val kafkaProducer = new KafkaProducer[String, String](commonConfiguration)
(0 to 6).foreach(id => kafkaProducer.send(new ProducerRecord[String, String](inputTopicName, s"${id}",
s"v${id}")))
kafkaProducer.flush()
FileUtils.deleteDirectory(new File(checkpointLocation))
}
Further, in the test itself, I'm defining the configuration referencing all the properties related to the integration test Kafka instance. Remember when I mentioned the extendibility of the dispatching app? That's the moment when I'm leveraging this property. Additionally, I'm trying to make the test predictable by setting the maxOffsetsPerTrigger property. Although it's not relevant for the job itself, it could be for the scenario involving timely stateful processing with unordered data, or the test scenario verifying the output of each micro-batch:
val dataDispatcherConfig = DataDispatcherConfig(
bootstrapServers = bootstrapServers,
inputTopic = InputTopicConfig(name = inputTopicName,
extra = Map("startingOffsets" -> "EARLIEST", "maxOffsetsPerTrigger" -> "2")),
validDataTopic = validDataTopicName, invalidDataTopic = invalidDataTopicName,
checkpointLocation = checkpointLocation,
isIntegrationTest = true
)
val configJson = objectMapper.writeValueAsString(dataDispatcherConfig)
val dataDispatcher = DataDispatcher.main(Array(configJson))
At the end of the test, I must admit, it's not as short as I would like to, I'm comparing the results generated by the job with the expected outcome:
val dataConsumer = new KafkaConsumer[String, String](commonConfiguration)
dataConsumer.subscribe(Seq(validDataTopicName, invalidDataTopicName).asJava)
val data = dataConsumer.poll(Duration.ofSeconds(30))
val dispatchedRecords = data.asScala.groupBy(record => record.topic())
.map {
case (topic, records) => (topic, records.map(record => (record.key(), record.value())))
}
dispatchedRecords(validDataTopicName) should have size 3
dispatchedRecords(validDataTopicName) should contain allOf (
("1", "v1"), ("3", "v3"), ("5", "v5")
)
dispatchedRecords(invalidDataTopicName) should have size 4
dispatchedRecords(invalidDataTopicName) should contain allOf (
("0", "v0"), ("2", "v2"), ("4", "v4"), ("6", "v6")
)
Testcontainers and Docker used in my example are only two of many other components you might use in the integration tests. If you're working with the cloud services, instead of them you'll probably use Terraform to manage the infrastructure from the test pipeline. If you prefer running the processing job on a cluster, it's probable you'll create the job with spark-submit. Nonetheless, the best practices are general and I hope they'll help you write good integration tests!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Integration tests and Structured Streaming here:
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Integration tests in #StructuredStreaming ? Today I wrote a short blog post about this topic ? https://t.co/r3XcDlCcYY
— Bartosz Konieczny (@waitingforcode) April 2, 2022