
During my last Spark exploration of the RPC implementation one class caught my attention. It was StateStoreCoordinator used by the state store that is an important place in Structured Streaming pipelines.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post presents the Apache Spark Structured Streaming state store. The first section gives a general idea about it. The second part focuses on its API while the last one shows a sample code involving state store.
State store defined
The queries in Structured Streaming are different than the queries in batch-oriented Spark SQL. In the batch processing the query is executed against bounded amount of data, thus the computed results can be final. It's not the case for the streaming processing where the results can grow infinitely. So growing results are stored in a fault-tolerant state store.
The purpose of the state store is to provide a reliable place from where the engine can read the intermediary result of Structured Streaming aggregations. Thanks to this place Spark can, even in the case of driver failure, recover the processing state to the point before the failure. In the analyzed version (2.2.1), the state store is backed by a HDFS-like distributed filesystem. And in order to guarantee recoverability, at least 2 most recent versions must be stored. For instance, if the batch#10 fails in the middle of processing, then the state store will probably have the states for batch#9 and a half of batch#10. Spark will restart the processing from the batch#9 because it's the last one completed successfully. As we'll discover in the next part, a garbage collection mechanism for too old states exists as well.
Technically the state store is an object presented in each partition, storing the data as key-value pairs and, as already told, used for streaming aggregations. The object is the implementation of org.apache.spark.sql.execution.streaming.state.StateStore trait. As told in the previous paragraph, the single supported store is actually HDFSBackedStateStore.
State store implementation details
To have a better idea about what happens under-the-hood, without entering a lot into details now (as promised, stateful aggregations will be covered in further post), the image below should help:
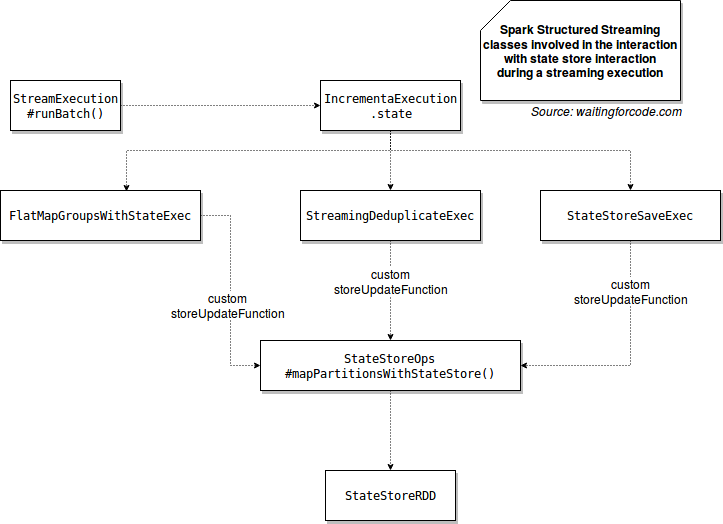
The diagram above shows the method generating org.apache.spark.sql.execution.streaming.state.StateStoreRDD. As its name indicates, this RDD is responsible for the execution of computations against available state stores. The implementation of StateStoreRDD is pretty simple since it retrieves the state store for given method and partition, and executes the storeUpdateFunction: (StateStore, Iterator[T]) => Iterator[U] function passed by one of callers on it:
override def compute(partition: Partition, ctxt: TaskContext): Iterator[U] = {
var store: StateStore = null
val storeId = StateStoreId(checkpointLocation, operatorId, partition.index)
store = StateStore.get(
storeId, keySchema, valueSchema, storeVersion, storeConf, confBroadcast.value.value)
val inputIter = dataRDD.iterator(partition, ctxt)
storeUpdateFunction(store, inputIter)
}
The StateStoreRDD is the only place accessing to state store object. Before resolving the mystery of storeUpdateFunction, let's inspect the StateStore trait contract:
- def id: StateStoreId - returns the id of given state store. The id is represented by StateStoreId instance and is described by: checkpoint location, operator id and partition id. The first attribute comes either from checkpointLocation option or spark.sql.streaming.checkpointLocation property. The second one represents the id for the current stateful operator in the query plan. It's defined in IncrementalExecution and updated at every SparkPlan execution. The last property is related to the partition id of underlying RDD.
- def version: Long - defines the version of the data. It's incremented with every update. Firstly it's updated locally and keep in pending state. Only after the commit to the state store the locally changed version is considered as the new current version for the aggregation.
At this moment it's important to mention that Spark won't keep all versions. org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider#cleanup method keeps only last X versions where X corresponds to the number defined in the spark.sql.streaming.minBatchesToRetain property. It defines the minimum number of batches that must be retained to made the processing recoverable. - def commit(): Long - it commits the local changes and returns the new version of state store. In the case of HDFSBackedStateStore changes are progressively saved to a temporary file by each partition. The file is located in a HDFS-compatible file system directory: checkpointLocation/operatorId/partitionId. From that is created this file representing all the updates ($version.delta).
- CRUD methods - Spark doesn't commit all state as it. Each key can be either added/updated (def put(key: UnsafeRow, value: UnsafeRow): Unit) or removed (def remove(key: UnsafeRow): Unit or def remove(condition: UnsafeRow => Boolean): Unit). In the case of any errors the current state will be cleaned with def abort(): Unit.
The amount of written data depends on the used output mode. If it's complete, then Spark writes all rows to the state store. If it's append or update it writes only the rows that before the watermark. - def filter(condition: (UnsafeRow, UnsafeRow) => Boolean): Iterator[(UnsafeRow, UnsafeRow)] - StateStore also exposes the filtering method that returns the rows matchig defined condition. Currently it's used by FlatMapGroupsWithStateExec to retrieve expired keys. The filter method should be fail-safe, i.e. do not fail during the filtering when some of states are updated. The iterated entries are backed by java.util.concurrent.ConcurrentHashMap instance that provides this fail-safe guarantee since it iterates over snapshot map representation.
The StateStore has a companion object defining helper methods to create and retrieve stores by their ids. Another useful class is StateStoreProvider implementation (HDFSBackedStateStoreProvider). It's used in the companion object methods to get given store and execute maintenance task (cleaning old states). The maintenance task is also responsible for generating snapshot files. These file consolidate multiple state store files (delta files) into a single snapshot file. The snapshot file reduces the lineage of delta files by taking the delta files of the last version and saving all changes in a single file.
This whole logic can be resumed as follows: the executors write local changes (added/updated/removed rows) to a file stream representing a temporary delta file. At the end they call commit method that: closes the stream, creates the delta file for given version, logs this fact with the Committed version... message and changes the state of the store from UPDATING to COMMITTED. The commit method is called from the storeUpdateFunction presented above. Apart that, there is also a background task making some maintenance work, i.e. consolidating finalized delta files into 1 single file called snapshot file and removing old snapshot and delta files.
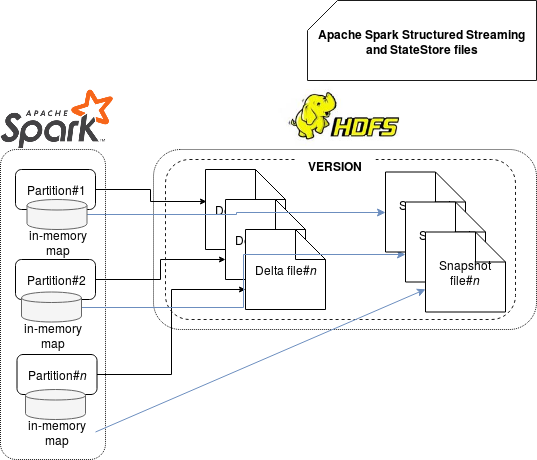
State store files
The state store deals with 2 kinds of files: delta and snapshot. The delta file contains the state representation of the results for each query execution. It's constructed from temporary delta file supplied by the state changes registered in given partition (state store is related to a partition and each partition stores the versioned state data in a hash map). The name of that temporary file is resolved from the s"temp-${Random.nextLong}" pattern. At the end, i.e. when commit method is called, the final delta file (s"$version.delta") is created for the new version.
Spark also runs a maintenance thread that will take the in-memory map of the state store and save it into a .snapshot file. This operations will occur only when the number of created delta files reached the value specified in spark.sql.streaming.stateStore.minDeltasForSnapshot configuration property.
The following schema summarizes all of that:
Regarding to the storeUpdateFunction quoted previously, it defines what to do with the data generated in given micro-batch. Its implementation depends a lot of the object defining it. For instance in the case of StateStoreSaveExec, this function handles the data according to the output mode used by the writer and either it outputs: all rows every time (complete mode), only the rows evicted from the data store (append mode) or only the updated rows (update mode). In the case of StreamingDeduplicateExec operator, Spark saves the firstly encountered rows in the state store. This detection is done by the following snippet:
val result = baseIterator.filter { r =>
val row = r.asInstanceOf[UnsafeRow]
val key = getKey(row)
val value = store.get(key)
if (value.isEmpty) {
store.put(key.copy(), StreamingDeduplicateExec.EMPTY_ROW)
numUpdatedStateRows += 1
numOutputRows += 1
true
} else {
// Drop duplicated rows
false
}
}
The FlatMapGroupsWithStateExec uses the state store to obviously save the generated state but also to handle rows expiration.
State store example
The 2 tests below prove that the state store is used only in the streaming processing and that different version are managed by the engne:
"stateful count aggregation" should "use state store" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val testKey = "stateful-aggregation-count-state-store-use"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.groupBy("id")
.agg(count("*"))
inputStream.addData((1, "a1"), (1, "a2"), (2, "b1"),
(2, "b2"), (2, "b3"), (2, "b4"), (1, "a3"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("id")} -> ${row.getAs[Long]("count(1)")}"))
.start()
query.awaitTermination(15000)
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 2
readValues should contain allOf("1 -> 3", "2 -> 4")
// The assertions below show that the state is involved in the execution of the aggregation
// The commit messages are the messages like:
// Committed version 1 for HDFSStateStore[id=(op=0,part=128),
// dir=/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128] to file
// /tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128/1.delta
val commitMessages = logAppender.getMessagesText().filter(_.startsWith("Committed version"))
commitMessages.filter(_.startsWith("Committed version 1 for HDFSStateStore")).nonEmpty shouldEqual(true)
// Retrieval messages look like:
// version 0 of HDFSStateStoreProvider[id = (op=0, part=2), dir =
// /tmp/temporary-cb59691c-21dc-4b87-9d76-de108ab32778/state/0/2] for update
// (org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider:54)
// It proves that the state is updated (new state is stored when new data is processed)
val retrievalMessages = logAppender.getMessagesText().filter(_.startsWith("Retrieved version"))
retrievalMessages.filter(_.startsWith("Retrieved version 0 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
// The report messages show that the state is physically loaded. An example of the message looks like:
// Reported that the loaded instance StateStoreId(/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state,0,3)
// is active (org.apache.spark.sql.execution.streaming.state.StateStore:58)
val reportMessages = logAppender.getMessagesText().filter(_.startsWith("Reported that the loaded instance"))
reportMessages.filter(_.endsWith("state,0,1) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,2) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,3) is active")).nonEmpty shouldEqual(true)
}
"stateless count aggregation" should "not use state store" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val data = Seq((1, "a1"), (1, "a2"), (2, "b1"), (2, "b2"), (2, "b3"), (2, "b4"), (1, "a3")).toDF("id", "name")
val statelessAggregation = data.groupBy("id").agg(count("*").as("count")).collect()
val mappedResult = statelessAggregation.map(row => s"${row.getAs[Int]("id")} -> ${row.getAs[Long]("count")}").toSeq
mappedResult should have size 2
mappedResult should contain allOf("1 -> 3", "2 -> 4")
logAppender.getMessagesText() shouldBe empty
}
The state store is a required element to handle the aggregation results changing in each micro-batch execution. As shown, it's strongly related to the output mode used by the writer. The mode defines which rows (all or not expired) will be saved in the new version of the state. At the time of writing the only supported store is a HDFS-like distributed file system but the StateStore trait seems to be easily adaptable to storage engines. However, the state store exists only in structured streaming pipelines. It was proven in the tests defined in the 3rd section.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about StateStore in Apache Spark Structured Streaming here:
- State Store: A new framework for state management for computing Streaming Aggregates StateStore — Streaming Aggregation State Management State Store for Streaming Aggregation Taking Spark Streaming to the Next Level with Datasets and DataFrames
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Another post about #ApacheSparkStructuredStreaming, this time a focus on state store https://t.co/1kGF1AS3bR
— bardev (@waitingforcode) March 9, 2018