
Message bus is a common architectural design in the Enterprise Design Patterns. But it's also present at a lower level to enable the event-driven behavior. Apache Spark is not an exception. It uses a publish/subscribe approach in various places.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Agnostic design
A message bus architecture involves 3 actors:
- Publishers that generate messages (events).
- Message bus that stores the generated events.
- Subscribers that read all or a part of the generated events.
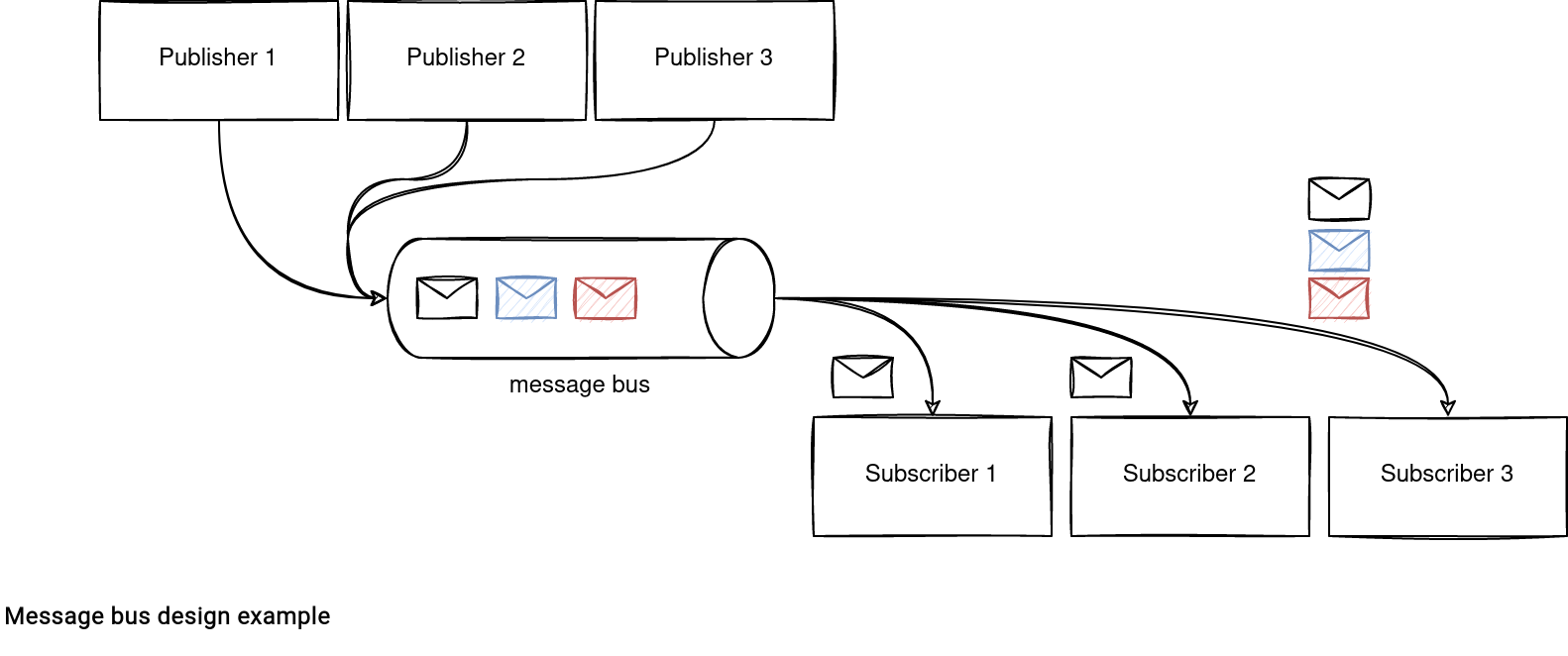
The implementation looks the same in Apache Spark.
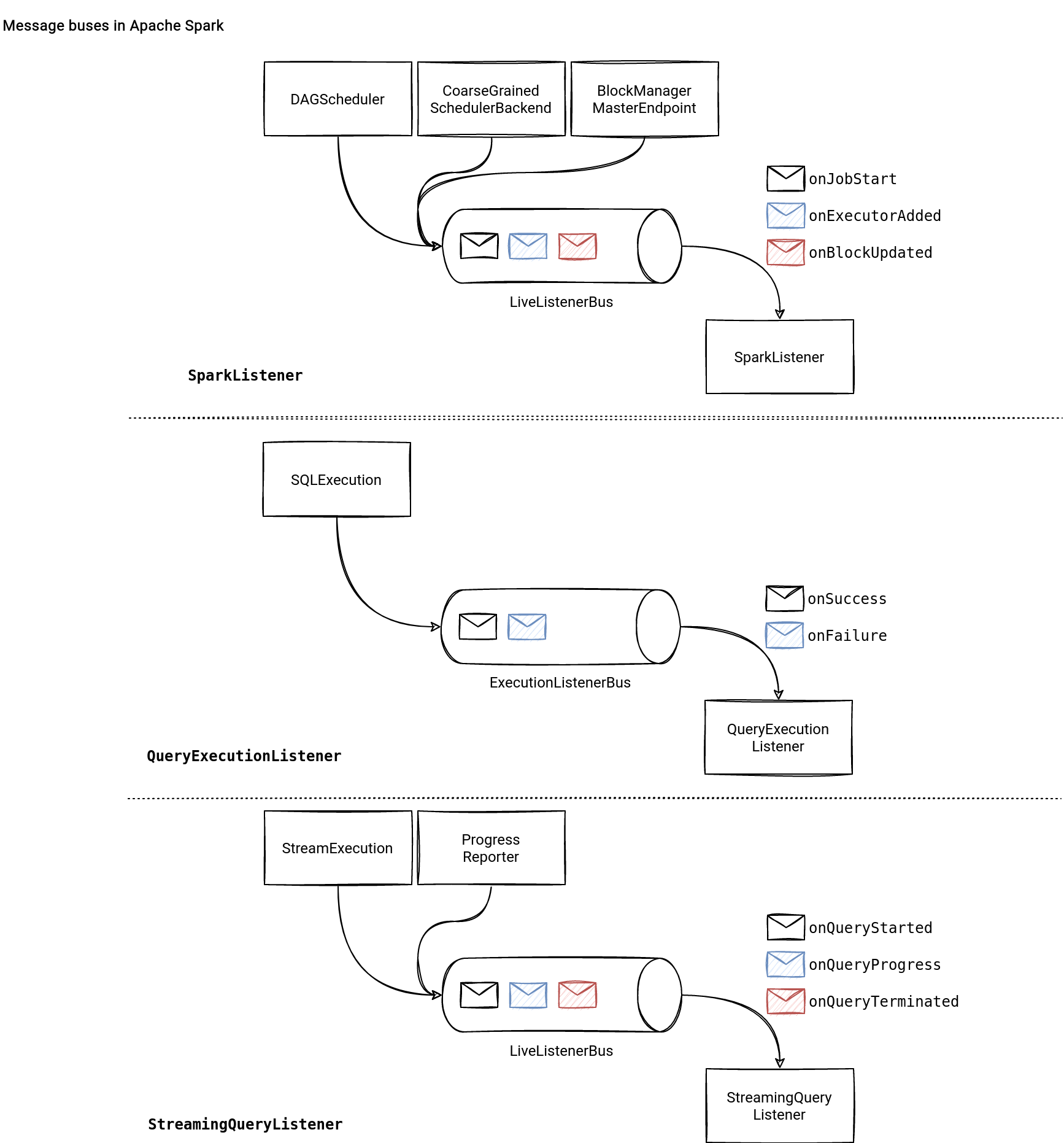
SparkListener
Job-related events are the first type of messages you can listen to in Apache Spark. They expose what happens for:
- The beginning and end of the application, jobs, stages, and tasks.
- Environment changes with new files or JARs added to the execution context.
- Block manager lifecycle. This category contains the events related to the block manager addition and removal.
- RDD unpersist. The event generated when a cached RDD leaves the cache storage.
- Executors and nodes changes. The list of supported actions is pretty long. Among the major aspects, you'll find there the blacklisting and exclusion for the global or stage state, and executor addition or removal.
Apache Spark comes with a handy abstract class called SparkListener that defines no-op event handlers for all existing events. Thanks to this class, if you need to only react on one specific category, you don't have to redefine all on* callback methods.
To register a custom listener, you can call SparkContext#addSparkListener(listener: SparkListenerInterface) function that will add your class to the listeners queue.
An event publication consists of calling the LiveListenerBus#post(event: SparkListenerEvent) with the case class representing the event. Event dispatching to the listeners is a simple pattern matching on the event classes:
private[spark] trait SparkListenerBus
extends ListenerBus[SparkListenerInterface, SparkListenerEvent] {
// ...
protected override def doPostEvent(
listener: SparkListenerInterface,
event: SparkListenerEvent): Unit = {
event match {
case stageSubmitted: SparkListenerStageSubmitted =>
listener.onStageSubmitted(stageSubmitted)
case stageCompleted: SparkListenerStageCompleted =>
listener.onStageCompleted(stageCompleted)
case jobStart: SparkListenerJobStart =>
listener.onJobStart(jobStart)
case jobEnd: SparkListenerJobEnd =>
// ...
QueryExecutionListener
Another category of listeners comes from Apache Spark SQL and the QueryExecutionListener class. It's a poorer sibling of the SparkListener because it only has 2 callbacks:
- onSuccess that defines the handler for a successfully executing Apache Spark SQL query. The outcome is different from the SparkListener because the event contains more information about the executed query, including the logical plan and all statistics you can gather from there.
- onFailure where you can define the handler for a failed query execution.
To register the listeners, you can specify the full class name in the spark.sql.queryExecutionListeners config parameter or directly call the ExecutionListenerManager#register(listener: QueryExecutionListener) method.
The logic responsible for dispatching the event to the handlers is defined inside the ExecutionListenerBus#doPostEvent(listener: QueryExecutionListener, event: SparkListenerSQLExecutionEnd). It uses the pattern matching on top of the SparkListenerSQLExecutionEnd to get the success or failure handler:
class ExecutionListenerManager private[sql](
session: SparkSession,
sqlConf: SQLConf,
loadExtensions: Boolean)
extends Logging {
// ...
override protected def doPostEvent(
listener: QueryExecutionListener,
event: SparkListenerSQLExecutionEnd): Unit = {
if (shouldReport(event)) {
val funcName = event.executionName.get
event.executionFailure match {
case Some(ex) =>
val exception = ex match {
case e: Exception => e
case other: Throwable =>
QueryExecutionErrors.failedToExecuteQueryError(other)
}
listener.onFailure(funcName, event.qe, exception)
case _ =>
listener.onSuccess(funcName, event.qe, event.duration)
}
}
}
StreamingQueryListener
The StreamingQueryListener is the last example of the listeners I want to share with you here. As its name indicates, the class is responsible for the events related to the Structured Streaming queries. It defines 3 callbacks:
- onQueryStarted(event: QueryStartedEvent) invoked when a new micro-batch starts.
- onQueryProgress(event: QueryProgressEvent) called when there are some new information about the micro-batch, such as source and sink progres, or the query execution duration
- onQueryTerminated(event: QueryTerminatedEvent) for a finished query (failed or successful)
There are 2 ways to attach a new listener. The first uses the spark.sql.streaming.streamingQueryListeners configuration entry where you can define a list of listeners to use in the job. The second method calls StreamingQueryManager#addListener(listener: StreamingQueryListener) directly.
When it comes to the dispatch, it's defined in the same doPostEvent method but this time, in the StreamingQueryListenerBus:
class StreamingQueryListenerBus(sparkListenerBus: Option[LiveListenerBus])
extends SparkListener with ListenerBus[StreamingQueryListener, StreamingQueryListener.Event] {
// ...
override protected def doPostEvent(
listener: StreamingQueryListener,
event: StreamingQueryListener.Event): Unit = {
def shouldReport(runId: UUID): Boolean = {
// When loaded by Spark History Server, we should process all event coming from replay
// listener bus.
sparkListenerBus.isEmpty ||
activeQueryRunIds.synchronized { activeQueryRunIds.contains(runId) }
}
event match {
case queryStarted: QueryStartedEvent =>
if (shouldReport(queryStarted.runId)) {
listener.onQueryStarted(queryStarted)
}
case queryProgress: QueryProgressEvent =>
if (shouldReport(queryProgress.progress.runId)) {
listener.onQueryProgress(queryProgress)
}
case queryTerminated: QueryTerminatedEvent =>
if (shouldReport(queryTerminated.runId)) {
listener.onQueryTerminated(queryTerminated)
}
case _ =>
}
}
Example
I hope you saw from the above sections that writing and registering a listener is quite easy. In case you're still confused, below you can find 3 code snippets showing how to define and register each type of listeners:
- SparkListener:
object SparkListenerExample { def main(args: Array[String]): Unit = { val sparkSession = SparkSession.builder().master("local[*]").getOrCreate() sparkSession.sparkContext.addSparkListener(LogPrintingListener) import sparkSession.implicits._ (0 to 100).toDF("nr").repartition(30).collect() } } object LogPrintingListener extends SparkListener { override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = { println(s"Started task with the message: ${taskStart}") } override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = { println(s"Ended task with the message: ${taskEnd}") } } - QueryExecutionListener
object QueryExecutionListenerExample { def main(args: Array[String]): Unit = { val sparkSession = SparkSession.builder().master("local[*]").getOrCreate() sparkSession.listenerManager.register(QueryExecutionPrintingListener) import sparkSession.implicits._ (0 to 100).toDF("nr").count() } } object QueryExecutionPrintingListener extends QueryExecutionListener { override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = { println("=========================================") println(" Print on success ") println(s"${funcName}: ${qe}") println("=========================================") } override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = { println("=========================================") println(" Print on failure ") println(s"${funcName}: Failure!") println("=========================================") } } - StreamingQueryListener
object StreamingQueryListenerExample { def main(args: Array[String]): Unit = { val sparkSession = SparkSession.builder().master("local[*]").getOrCreate() sparkSession.streams.addListener(StreamingQueryPrintingListener) val rateMicroBatchSource = sparkSession.readStream .option("rowsPerSecond", 5) .option("numPartitions", 2) .format("rate").load() import sparkSession.implicits._ val consoleSink = rateMicroBatchSource .select($"timestamp", $"value", functions.spark_partition_id()) .writeStream.format("console").trigger(Trigger.ProcessingTime("2 seconds")) consoleSink.start().awaitTermination() } } object StreamingQueryPrintingListener extends StreamingQueryListener { override def onQueryStarted(event: StreamingQueryListener.QueryStartedEvent): Unit = { println(s">>> Query started ${event}") } override def onQueryProgress(event: StreamingQueryListener.QueryProgressEvent): Unit = { println(s">>> Query made progress ${event}") } override def onQueryTerminated(event: StreamingQueryListener.QueryTerminatedEvent): Unit = { println(s">>> Query terminated ${event}") } }
In addition to the observable metrics Spark listeners are another way to see what happens with your job. The difference between these 2 components is the scope. The metrics operate on the data whereas the listeners apply to the query- or job-related attributes.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect
SparkListener, QueryExecutionListener and StreamingQueryListener are 3 types of listeners in #ApacheSpark I focused on them in the new blog post you can access right here ? https://t.co/wp4MhbTzlA
— Bartosz Konieczny (@waitingforcode) November 12, 2022