
Observability is a hot topic nowadays, not only for the data but also the software industry. Apache Spark innovates in this field a lot, including new metrics for Structured Streaming and an important update added in the 3.0.0 release that I missed at the time, which are the observable metrics.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In a nutshell
Observable metrics compute aggregated metrics on the data processed in the job and return them after reaching the completion point of the query. This completion point is the end of the batch job and so generated metrics are later accessible from a QueryExecutionListener or a getter of the Observation instance.
Need an example? Let's check this out:
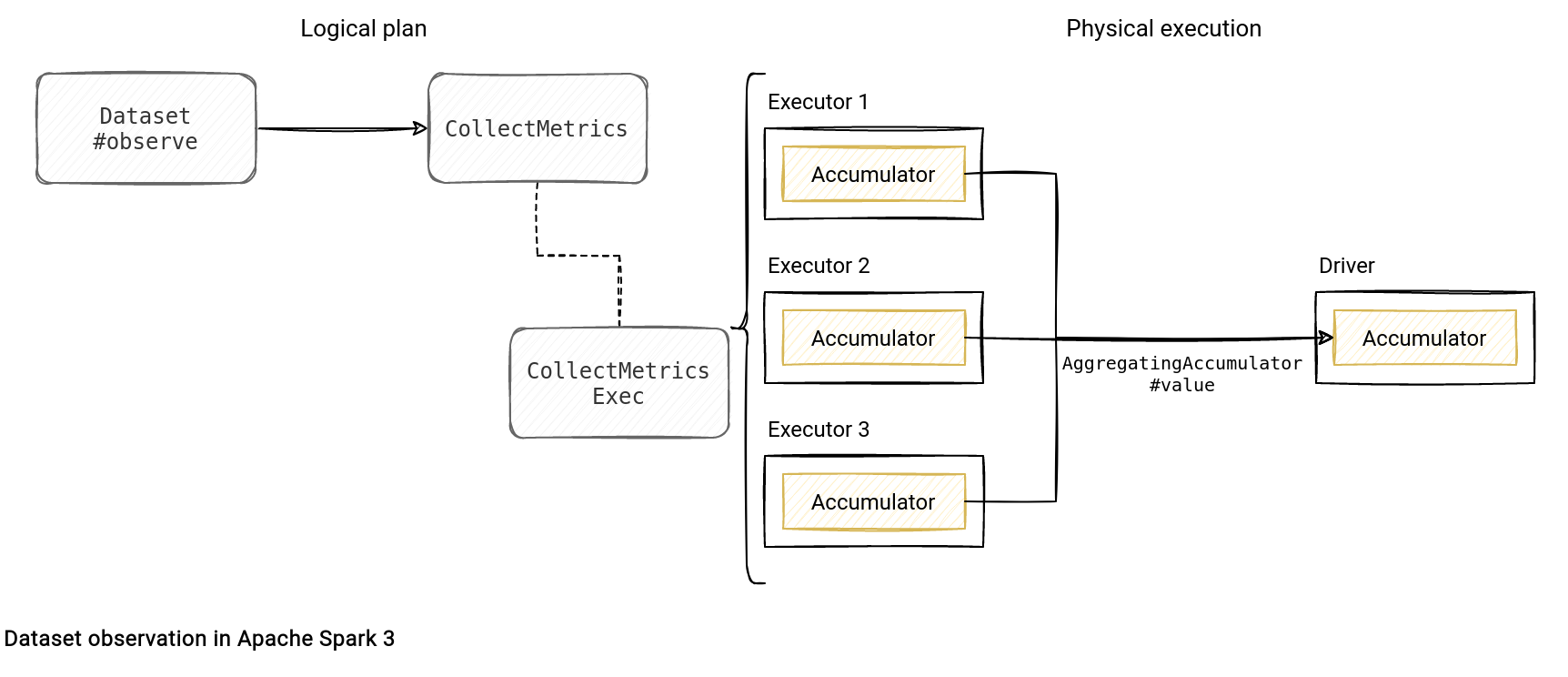
Execution plan
What happens under-the-hood? As for many things in Apache Spark, we find here the wrapping (I've covered it for the first time in the iterators in Apache Spark blog post). The initial execution plan is wrapped by a CollectMetrics node than in its turn, at the physical execution, wraps the call of each row:
private[sql] object Dataset {
// ...
def observe(name: String, expr: Column, exprs: Column*): Dataset[T] = withTypedPlan {
CollectMetrics(name, (expr +: exprs).map(_.named), logicalPlan)
}
object BasicOperators extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
// ...
case logical.CollectMetrics(name, metrics, child) =>
execution.CollectMetricsExec(name, metrics, planLater(child)) :: Nil
case class CollectMetricsExec(
name: String,
metricExpressions: Seq[NamedExpression],
child: SparkPlan)
extends UnaryExecNode {
// …
override protected def doExecute(): RDD[InternalRow] = {
val collector = accumulator
collector.reset()
child.execute().mapPartitions { rows =>
val updater = collector.copyAndReset()
TaskContext.get().addTaskCompletionListener[Unit] { _ =>
if (collector.isZero) {
collector.setState(updater)
} else {
collector.merge(updater)
}
}
rows.map { r =>
updater.add(r)
r
}
}
}
As you can see in the snippet, the physical node defines a local (driver) accumulator that gets later copied for each task and updated before returning the transformed row of the partition. The metrics remain local and only the call of the CollectMetricsExec#collect(plan: SparkPlan) method triggers the merge on the driver. This function gets called by the observedMetrics from the demo code presented previously:
class QueryExecution(
val sparkSession: SparkSession,
val logical: LogicalPlan,
val tracker: QueryPlanningTracker = new QueryPlanningTracker,
val mode: CommandExecutionMode.Value = CommandExecutionMode.ALL) extends Logging {
// ...
/** Get the metrics observed during the execution of the query plan. */
def observedMetrics: Map[String, Row] = CollectMetricsExec.collect(executedPlan)
CollectMetricsExec
The physical node responsible for the observation is the CollectMetricsExec. Inside you can find not only the observation logic mentioned before but also the answer why the observer accepts an accumulator or a literal only. The answer is related to the component used to collect the statistics in the run, the AggregatingAccumulator:
case class CollectMetricsExec(
name: String,
metricExpressions: Seq[NamedExpression],
child: SparkPlan)
extends UnaryExecNode {
private lazy val accumulator: AggregatingAccumulator = {
val acc = AggregatingAccumulator(metricExpressions, child.output)
acc.register(sparkContext, Option("Collected metrics"))
acc
}
The accumulator doesn't accept anything else than the aggregation expression. Additionally, an aggregator is supposed to "aggregate", so to represent something in a more concise manner. Otherwise, it could be too impactful for the processing logic itself by the increased memory and network transfer (accumulators get merged after combining the results computed locally on executors).
Besides listeners, there is another great way to "listen" what happens in your job. The good news is that the observation API is relatively easy to set up!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Observable metrics here:
Related blog posts:
How to observe a Dataset in #ApacheSpark ? With the observation API which is the topic of the new blog post you can read just here ? https://t.co/KiYVop9kKo
— Bartosz Konieczny (@waitingforcode) September 24, 2022