
Even though Apache Spark provides GraphX module, it's still possible to use the framework with other graph-based engines. One of them is Neo4j. But before using its Spark connector, it's good to know some internal execution details - especially the ones related to scalability.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post presents Apache Spark integration with Neo4j with a particular focus on the scalability. The first section describes Neo4j and the way it scales. The next part explains how Neo4j and Apache Spark work together. The final section shows an example of integration with simulated distributed processing.
Neo4j and scalability
One of Neo4j's scalability limitations is its architecture. The database expects the whole graph to fit in a single machine. Thus, the data is not sharded across different servers as we have a habit of seeing that in a lot of distributed data stores. Instead all vertices and edges are stored in a single machine. But does it mean that we must always work with a single server doing writes and reads ?
The answer is no. Neo4j is designed as master-slave architecture so even though there is always 1 node handling all writes (and for performance reasons it should do only writes), we still have a possibility to add multiple read-only replicas that may be used for data retrieval. Thus we can tell that the database scales writes vertically and reads horizontally. Thanks to the read scalability one it's possible to apply graph traversals on subgraphs located in different nodes on the cluster, as in the following image:
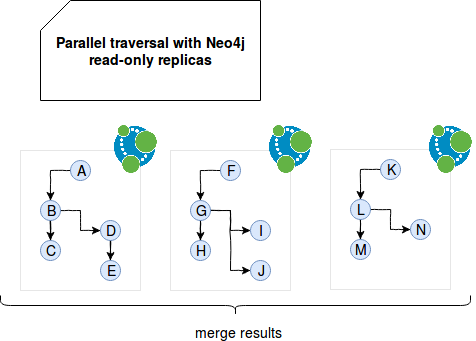
As we can see, it's important to have a "split point", i.e. indicators allowing us to start traversals from different vertices in each node. Obviously right after finding the results, we need to do something with them and return an aggregated final response. And it's here where Apache Spark's connector comes to the aid.
But despite this constraining master-slave architecture, Neo4j comes with some interesting optimizations to accelerate query executions. The master-slave architecture with as many read-only slaves as needed is promoted as Horizontal Availability feature. It helps to guarantee reliability. When the master becomes unavailable one of still running nodes is elected as a new master at its place. Another interesting feature is cache sharding. It applies to the situation when the graph is too big to hold in the memory cache of a single machine. Instead its parts are cached on different nodes in the cluster. The sharding is a kind of cache affinity since users requests are redirected to the node supposed to cache given node.
Neo4j Apache Spark connector
In the analysis we focus on Neo4j-Spark-Connector presented in Neo4j official documentation. Even though it's in development phase it gives a good example on how to parallelize Neo4j reads.
Unsurprisingly the parallelization happens with pretty meaningful methods: partition(int) and batch (int). The former one indicates the number of parallelized processes reading the data and the latter the number of elements retrieved by each of the processes. Under-the-hood these values are used to build an object representing data splits read by every executor:
override protected def getPartitions: Array[Partition] = {
val p = partitions.effective()
Range(0,p.partitions.toInt).map( idx => new Neo4jPartition(idx,p.skip(idx), p.limit(idx))).toArray
}
Neo4j uses the information from partitions to execute defined query only on a part of the whole graph. The database does it with SKIP and LIMIT mechanism well known from classical RDBMS. In consequence Apache Spark's partitions and SKIP-LIMIT construction lead to the queries partitioned exactly as in the case of other master-slave data sources. You can compare Neo4j mechanism with Partitioning RDBMS data in Spark SQL. For Neo4j case the executed queries looks like:
# partition=5 batchSize=3 MATCH (n:Person) RETURN id(n) SKIP 0 LIMIT 3 MATCH (n:Person) RETURN id(n) SKIP 3 LIMIT 3 MATCH (n:Person) RETURN id(n) SKIP 6 LIMIT 3 MATCH (n:Person) RETURN id(n) SKIP 9 LIMIT 3 MATCH (n:Person) RETURN id(n) SKIP 12 LIMIT 3
Apache Spark Neo4j connector example
The tests presented below are done with 2.2.1-M5 version of Neo4j connector. As of this writing, this is still in pre-alpha version. Because of that the tests aren't present in usual Github repository and only were executed locally in Neo4jDataFrameScalaTest class of the connector project. Our first test simply counts the number of added relations with the help of partitioned queries:
val INIT_QUERY = (1 to 20).map(id => s"CREATE (:Person {name: 'user${id}'})-[:LIKES]->(:Something:Something${id%2 == 0} {name: 'thing${id}'})").mkString("\n")
val server: ServerControls = TestServerBuilders.newInProcessBuilder(new File("/tmp/neo4j")).withConfig("dbms.security.auth_enabled", "false")
.withFixture(INIT_QUERY).newServer
// … some lines after some usual SparkContext initialization
val neo = Neo4j(javaSparkContext)
val allRelations = neo.cypher("MATCH (n:Person)-[:LIKES]->(:Something) RETURN id(n) SKIP {_skip} LIMIT {_limit}")
.partitions(5)
.batch(5)
.loadRowRdd
.count
allRelations shouldEqual 20
As expected, 20 relations were found. As you can observe, we overestimated the number of elements - Neo4j will be able to retrieve up to 25 items even though only 20 are present. Now, if we decrease the size of batch to 2, we'll see something different to happen:
val neo = Neo4j(javaSparkContext)
val allRelations = neo.cypher("MATCH (n:Person)-[:LIKES]->(:Something) RETURN id(n) SKIP {_skip} LIMIT {_limit}")
.partitions(5)
.batch(2)
.loadRowRdd
.count
allRelations shouldEqual 10
Yes, only 10 items were retrieved. If you read the post about RDBMS partitioning quoted previously, you'll quickly figure out that this behavior is different from the relational-based data sources where the last partition can return much more or much less rows than previous ones. Let's now back to the first version with the batch size of 5 and try to see if the counter works correctly for more constraining label "Somethingtrue":
val neo = Neo4j(javaSparkContext)
val allRelations = neo.cypher("MATCH (n:Person)-[:LIKES]->(:Somethingtrue) RETURN id(n) SKIP {_skip} LIMIT {_limit}")
.partitions(5)
.batch(5)
.loadRowRdd
.count
allRelations shouldEqual 10
Unsurprisingly, it also worked as expected. For the last test let's see what happens when we forget to specify SKIP clause in the query:
val neo = Neo4j(javaSparkContext)
val allRelations = neo.cypher("MATCH (n:Person)-[:LIKES]->(:Somethingtrue) RETURN id(n) LIMIT {_limit}")
.partitions(5)
.batch(5)
.loadRowRdd
.collect()
.map(row => row.getLong(0))
// It should contain duplicates, as for instance:
// [2,6,10,14,18,2,6,10,14,18,2,6,10,14,18,2,6,10,14,18,2,6,10,14,18]
val idsInSet = allRelations.toSet.size
val idsInArray = allRelations.size
val areDuplicates = idsInArray > idsInSet
areDuplicates shouldBe true
The query executes correctly but it returns duplicated ids. Thus, the connector doesn't provide control at this level and we should take care of query correctness by ourselves. It also doesn't behave the same as the partitioning mechanism for RDBMS where the partitioning clause is generated and appended automatically by Apache Spark engine.
Thus, scaling reads is not impossible. However, it may require some configuration effort. Correctly defined cache sharding, matching executed parallel queries, should also help in faster data processing. Unfortunately, as it was demonstrated in the last section's examples, parallelizing is not a silver bullet - especially if we are unable to define the exact slices. In such case we can miss some present entries that will be ignored because of a fixed limit for each partition.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Neo4j scalability and Apache Spark here:
- Neo4j vs Dgraph - The numbers speak for themselves Neo4j sharding aspect What is the status on Neo4j's horizontal scalability project Rassilon? C.2.4. HAProxy for load balancing
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Spark Connect
This week a new #graph related post on waitingforcode. It presents #ApacheSpark #Neo4j connector. After speaking generally about this graph database, the post focuses more on horizontal scalability of the connector: https://t.co/Nod0q2iMjO
— bardev (@waitingforcode) October 18, 2018