
The idea of writing this blog post came to me when I was analyzing Kubernetes changes in Apache Spark 3.1.1. Starting from this version we can use stage level scheduling, so far available only for YARN. Even though it's probably a very low level feature, it intrigued me enough to write a few words here!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Definition
Stage level scheduling defines the resources needed by each stage of an Apache Spark job. It's a relatively new feature because it got implemented only in version 3.1.1 for 2 cluster managers, YARN and Kubernetes. As of this writing (20/07/2021), it's only available in the RDD API with the Dynamic Resource Allocation enabled. What an execution graph with the stage level scheduling enabled looks like? You can see an example just below:
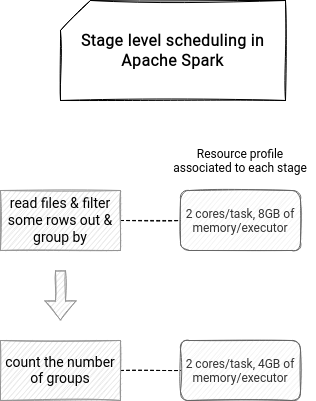
The feature is interesting for any heterogeneous workloads, such as an initial data reduction stage requiring a lot of resources and the next step working on the reduced dataset requiring much less compute power. The author of the feature, Thomas Graves, also quotes a resources optimization example of a ML pipeline preceded by an ETL. The ML part of the job needs GPU, but the ETL doesn't, so enabling it at the beginning of the pipeline would waste this precious resource.
Resource profiles
At the code level, you will find the stage level scheduling under the name of a resource profile. Each resource profile contains the executor and task resources requested for the given stage...:
class ResourceProfile(
val executorResources: Map[String, ExecutorResourceRequest],
val taskResources: Map[String, TaskResourceRequest])
...and among the types of resources, you will find:
object ResourceProfile extends Logging {
// task resources
val CPUS = "cpus"
private[spark] def getCustomTaskResources(
rp: ResourceProfile): Map[String, TaskResourceRequest] = {
rp.taskResources.filterKeys(k => !k.equals(ResourceProfile.CPUS)).toMap
}
// Executor resources
val CORES = "cores"
val MEMORY = "memory"
val OFFHEAP_MEM = "offHeap"
val OVERHEAD_MEM = "memoryOverhead"
val PYSPARK_MEM = "pyspark.memory"
def allSupportedExecutorResources: Array[String] =
Array(CORES, MEMORY, OVERHEAD_MEM, PYSPARK_MEM, OFFHEAP_MEM)
private[spark] def getCustomExecutorResources(
rp: ResourceProfile): Map[String, ExecutorResourceRequest] = {
rp.executorResources.
filterKeys(k => !ResourceProfile.allSupportedExecutorResources.contains(k)).toMap
}
To attach a resource profile to the job, you have to call the withResources(rp: ResourceProfile) method of RDD. Each RDD keeps only one profile, so if you call this method multiple times, it will save the last called one. And this link with the RDD is quite important for the scheduling part. Before submitting the stage, DAGScheduler reads all resource profiles defined in the stage RDDs. If there are multiple profiles, the scheduler merges them by taking the max value for each ExecutorResourceRequest and TaskResourceRequest:
private[scheduler] def mergeResourceProfiles(r1: ResourceProfile, r2: ResourceProfile): ResourceProfile = {
val mergedExecKeys = r1.executorResources ++ r2.executorResources
val mergedExecReq = mergedExecKeys.map { case (k, v) =>
val larger = r1.executorResources.get(k).map( x =>
if (x.amount > v.amount) x else v).getOrElse(v)
k -> larger
}
// Same for tasks just below, omitted for brevity
new ResourceProfile(mergedExecReq, mergedTaskReq)
}
But the merge doesn't happen every time, even for multiple resource profiles in a stage! By default the configuration controlling its execution (spark.scheduler.resource.profileMergeConflicts) is disabled. You should then get an IllegalArgumentException:
throw new IllegalArgumentException("Multiple ResourceProfiles specified in the RDDs for " +
"this stage, either resolve the conflicting ResourceProfiles yourself or enable " +
s"${config.RESOURCE_PROFILE_MERGE_CONFLICTS.key} and understand how Spark handles " +
"the merging them.")
Let's assume that the exception didn't happen. What will be the next step? DAGScheduler creates the Stage with the associated resource profile. That's where it stops and passes the torch to the cluster manager.
Stage level on Kubernetes
The stage level scheduling on Kubernetes relies on the ExecutorPodsSnapshotsStore which is an in-memory store with events management capacity. Apache Spark uses an ExecutorPodsWatcher to listen for all pod-related events. Whenever something happens about the pod specification, it automatically saves this information to the snapshots store:
private class ExecutorPodsWatcher extends Watcher[Pod] {
override def eventReceived(action: Action, pod: Pod): Unit = {
val podName = pod.getMetadata.getName
logDebug(s"Received executor pod update for pod named $podName, action $action")
snapshotsStore.updatePod(pod)
}
Since the snapshot store is also a notifier, it updates the pod information in all subscribed listeners. One of them is ExecutorPodsAllocator:
private[spark] class ExecutorPodsAllocator( conf: SparkConf,
// ...
snapshotsStore: ExecutorPodsSnapshotsStore,
clock: Clock) extends Logging {
def start(applicationId: String): Unit = {
snapshotsStore.addSubscriber(podAllocationDelay) {
onNewSnapshots(applicationId, _)
}
}
The allocator will run every podAllocationDelay (1 second by default) and execute the onNewSnapshots method. Inside this method you will find the logic responsible for starting and stopping the executors, including the ones managed by different resource profiles. Before showing you this in action, some important things from the documentation to keep in mind:
- dynamic resource allocation must be enabled alongside the shuffle files tracking (Kubernetes doesn't have an external shuffle service)
- because of the shuffle tracking features, the executors from the previously used resource profiles may still remain up if they hold the shuffle data on them
- in consequence, you may consume more Kubernetes resources; to reduce the risk, you can play with shuffle tracking timeout (spark.dynamicAllocation.shuffleTracking.timeout), but it can lead to recomputing the lost shuffle data (= choose your trade side, more resources, weaker risk of recomputing vs less resources and a higher risk of recomputing)
Knowing all that it's time to see the stage level scheduling in action:
Stage level scheduling is a relatively new feature in Apache Spark, and it still has some room for improvement, especially the support of the Dataset API. But despite that, it's an interesting evolution that adds some controlled flexibility to the jobs!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Stage level scheduling here:
Related blog posts:
- YARN or Kubernetes for Apache Spark?
- Kubernetes concepts for Apache Spark
- What's new in Apache Spark 3.1 - Kubernetes Generally Available!
- Docker images and Apache Spark applications
- Setting up Apache Spark on Kubernetes with microk8s
Happy to be back with the new blog posts! But before writing about the #ApacheSpark 3.2.0 features, I prepared an article presenting the stage level scheduling feature added in the previous version ? https://t.co/rkqcEjKfdN
— Bartosz Konieczny (@waitingforcode) October 16, 2021