
I've written my first Kubernetes on Apache Spark blog post in 2018 with a try to answer the question, what Kubernetes can bring to Apache Spark? Four years later this resource manager is a mature Spark component, but a new question has arisen in my head. Should I stay on YARN or switch to Kubernetes?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Spoiler alert, in the blog post you won't find a clear recommendation because it always depends on the context. You might have a team familiar with YARN and not feeling the positive impact of switching to Kubernetes. On the other hand, you might be supported by a DevOps team experienced with Kubernetes and making them work on YARN would kill their productivity. So instead of answering the question directly I'm going to say "It depends", and invite you to compare YARN and Kubernetes features, so that you can make this decision on your own!
Technology
At a high level YARN and Kubernetes use the same concept to run Apache Spark jobs, the containers (although, Kubernetes hide them behind pods that can run one or multiple containers, but overly simplified, let's consider them as same). It's the result of the resource allocating executing the Apache Spark code. But it couldn't live alone. In both technologies they're a part of a more sophisticated infrastructure.
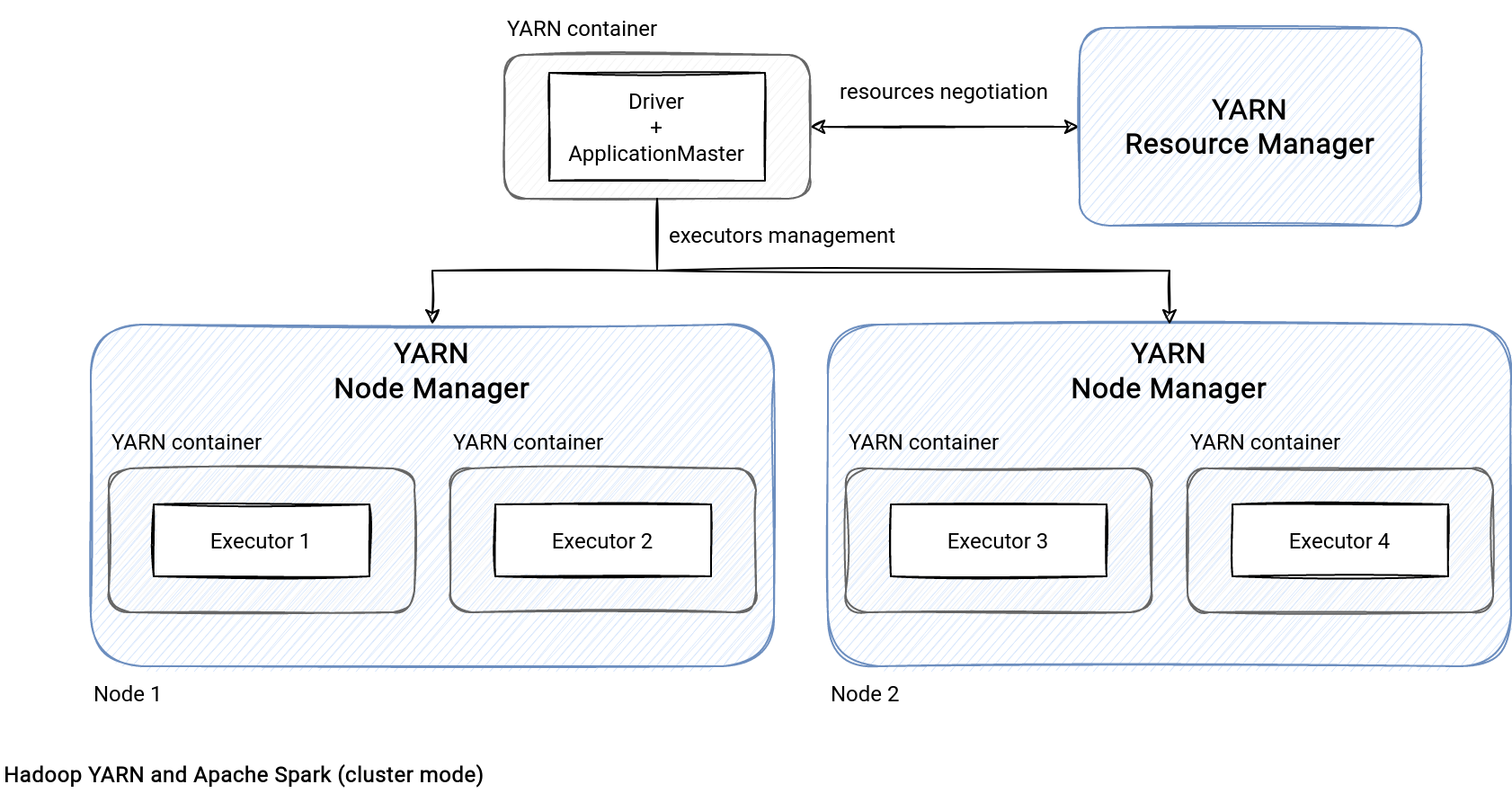
Apache Spark on YARN relies on 2 YARN components called the Resource Manager and Node Manager. The former is responsible for allocating the submitted job resources on the cluster nodes. Its responsibility doesn't stop with the allocation, though! Each node of the cluster has a Node Manager that monitors the activity of the created containers and sends this information to the Resource Manager. To close the communication loop, there is an Application Master component to communicate with the Resource Manager directly about the compute resources initialization. How does it relate toKubernetes? Quite similar actually!
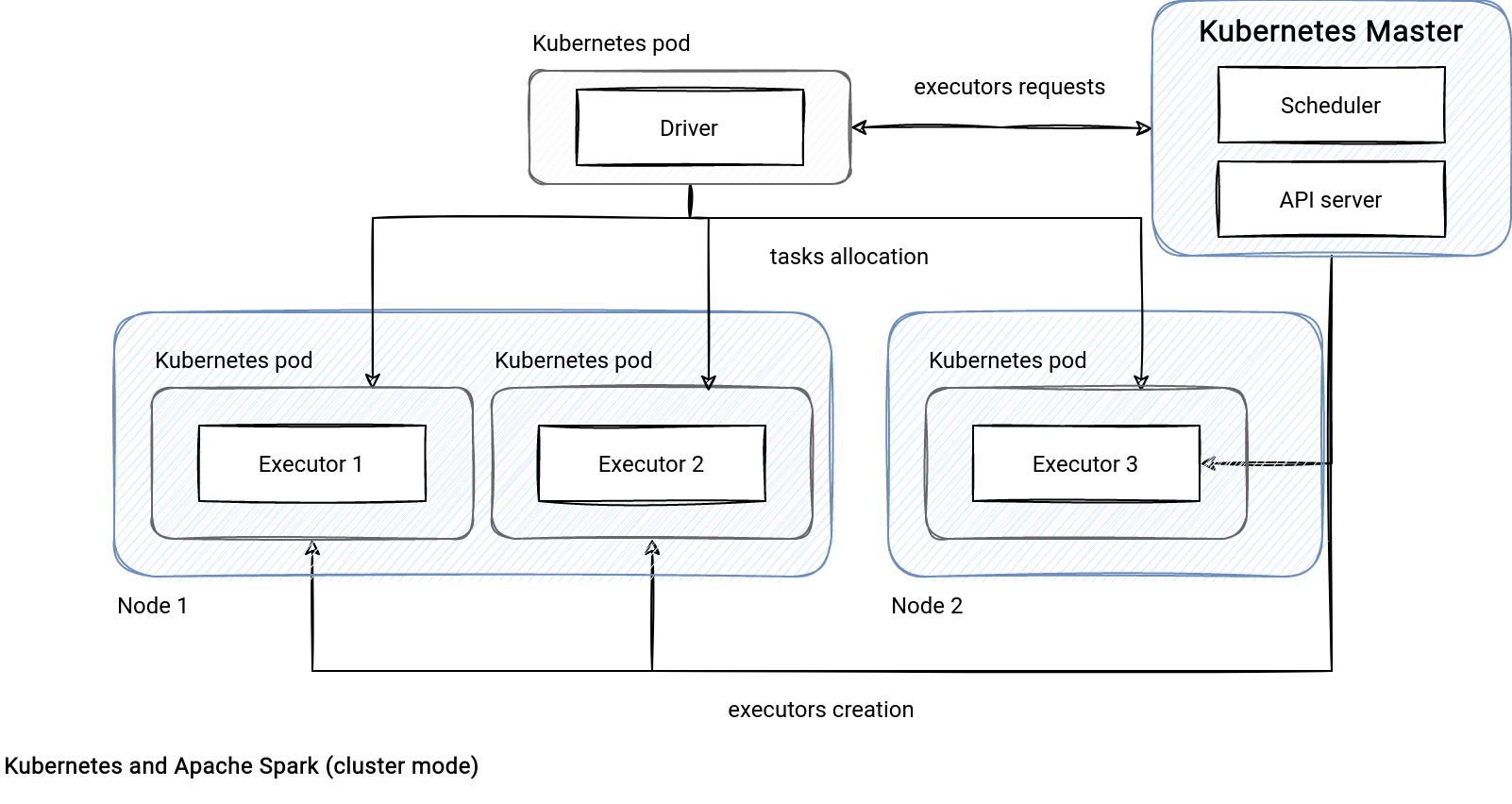
The Kubernetes workflow starts with the driver pod creation. After, the driver asks Kubernetes to schedule executor pods and once the allocation is finished, it starts submitting the tasks for execution.
The workflow is not the single similarity for both solutions. Another one that might be the most impacting (I bet you know the errors like Container killed by YARN for exceeding memory limits?!) is the memory allocation. Apache Spark is not the single memory consumer because both, YARN and Kubernetes, require a definition of the memory overhead. This overhead represents the memory part used by the OS or the off-heap storage. It defaults to 10% meaning that 10% of the executor memory will be taken for not-job related activity.
Scalability
An Apache Spark job can scale at 2 different levels, locally within the job and externally, on the cluster. The former approach uses the existing compute power to launch more tasks simultaneously. The feature you're looking for here is the Dynamic Resource Allocation and despite this apparent simplicity [after all, it's "just" a conf], it has some difficult aspects from a resource manager standpoint. The shuffle files. Any downscaling action shouldn't lose the executors storing the shuffle data needed in the job.
To mitigate that risk, YARN relies on an external shuffle service which is a process running on other nodes of the cluster. Kubernetes doesn't support this service yet but it does support dynamic allocation. Instead of keeping the shuffle files alive with the external service, it relies on the shuffle files tracking feature, so that the executors storing the shuffle files will be alive as long as the job needing the shuffle data.
That was the first scaling level. The second one is the external, so the cluster-based. What if the Dynamic Resource Allocation works great but the cluster doesn't have room anymore to handle new tasks? It's where the cluster-based scaling goes into action. Kubernetes has an extra component called cluster-autoscaler. It's the tool that adjusts the size of the cluster if scheduled pods can't be run. It would obviously happen if the Dynamic Resource Allocation scheduled an executor pod on the cluster lacking the free space.
The cluster-based scaling part in YARN mostly relies on the cloud provider's auto scaling capabilities, such as EMR Auto Scaling on AWS, or Dataproc auto scaling policy on GCP.
Isolation
Another important point is the workload isolation. If we talk about a multi-tenant environment here, the isolation is much harder to achieve on YARN. YARN is a single cluster with already some dependencies pre-installed. It may pretty easily lead to dependency hell problem where the class loader loads bad versions of the libraries from the cluster and provokes the method not found or class not found exceptions. There are various solutions to this issue and the most common one is Shading. However, it adds an extra overhead to the build process by rewriting the conflicting libraries.
Kubernetes doesn't have this dependency hell problem. Each Apache Spark job is a packaged container, so it has its own isolated scope without the risk of the conflict. On the other hand, the cost of building the package can be higher because you'll need to include all the dependencies in the image. While for YARN, some of them might be already installed on the cluster.
Besides the dependency hell, Kubernetes isolation helps testing new versions of Apache Spark easier. It's just a dependency bump in the build files while for YARN - if we consider the cloud-based scenario - it's often the synonym of waiting for the cloud provider to upgrade the version of the service.
To know more about the isolation aspect, I invite to the great Spark+AI Summit 2020 talk of Jean-Yves Stephan and Julien Dumazert, Running Apache Spark on Kubernetes: Best Practices and Pitfalls. The screenshot above comes from the talk and summarizes greatly the differences between YARN and Kubernetes:

Other factors
Although scalability is one of the main important attributes for a resource manager, it's not the single one. There are many others that are important but probably less visible:
- Cost. I saw at least 2 articles proving the superiority of Kubernetes in this field. In the first one Itai Yaffe and Roi Teveth shared their feedback on migrating EMR YARN-based batch jobs to Kubernetes at Nielsen. The outcome was outstanding, almost 30% cost reduction! Also AWS itself gives some hints how to save money on running Apache Spark on EKS. According to the benchmark, the same workloads executed on EKS were even 61% cheaper than for YARN!
- Performance. This time AWS shared their benchmark for TPC-DS framework results executed on top of YARN and EKS. In summary, the jobs executed on EKS finished 5% faster than their YARN-base counterparts. Knowing that the time is money on the cloud, it should also stand for lower costs of Kubernetes workloads.
- Local development and CI/CD integration. Another important aspect is the possibility to run the workloads locally and integrate them to the CI/CD. Apache Spark on Kubernetes is only the story of Docker images, so they can be deployed and tested anywhere (local Kubernetes, cloud Kubernetes service, on-premise installation, ...). The same is not true for YARN. Even though Docker images exist - I've created one 4 years ago - the integration to the development lifecycle seems less obvious than for Kubernetes.
- Community. If I haven't missed any big news, Kubernetes has been getting more community attention than YARN in terms of new features and big releases. YARN seems to be the legacy resource manager still used for a lot of existing Apache Spark jobs, though.
- Ops. That's probably the biggest problem for widespread Kubernetes adoption. The ops part for YARN is limited. You must know that there are the driver and executors on the cluster, but the technical details, such as YARN containers or node manages, are hidden. It's not the case for Kubernetes where the first contact mentions Kubernetes-related components, such as pods, volumes, or secrets, or Docker images creation. This ops gap might still be the reason why YARN will still be there for a while.
- People. People are the last on the list but quite important factor. If you can't compose your team and find the data engineers willing to work with Kubernetes instead of YARN - so to potentially leave their comfort zone - then it seems you have no other choice than staying with YARN.
The topic of resource managers is not easy, exactly as answering the question on which one from YARN and Kubernetes, you should use for your future Apache Spark workloads. Hopefully, the elements presented in this article will help you make this decision!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about YARN or Kubernetes for Apache Spark? here:
- Executor memory configuration Cluster Autoscaler Setting up, Managing & Monitoring Spark on Kubernetes Running Apache Spark on Kubernetes: Best Practices and Pitfalls
Related blog posts:
- Kubernetes concepts for Apache Spark
- Stage level scheduling
- What's new in Apache Spark 3.1 - Kubernetes Generally Available!
- Docker images and Apache Spark applications
- Setting up Apache Spark on Kubernetes with microk8s
Kubernetes or YARN for #ApacheSpark ? It's an easy question to ask but more difficult to answer. I'm not giving a firm answer either and only tried to compare different aspects of these resource managers in the first blog post after the break ? https://t.co/bwa61xSAjb
— Bartosz Konieczny (@waitingforcode) September 3, 2022