
In my previous post I presented a very simplified version of a Great Expectations data validation pipeline. Today, before going further and integrating the pipeline with a data orchestration tool, it's a good moment to see what's inside the framework.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this article, I will present 6 important classes involved in the definition of the data validation pipeline. You don't need such deep understanding to run your own Great Expectations pipelines (the official doc should be sufficient for that), but since I don't like to run things without prior understanding, I will give a try and analyze the implementation details 🤓
DataContext
That's the key of any Great Expectations project, a little bit like a SparkSession in Apache Spark applications. The DataContext instance defines the execution context in terms of data sources, expectations and data stores. It's also the class used when you call great-expectations init method. It'll then create the project structure alongside all required files.
Later on, you will interact with your DataContext instance to:
- retrieve the batch data to validate from the get_batch method
- validate the retrieved batch with run_validation_operator method
- programmatically modify the data sources or expectation suites, both for read and write operations
But DataContext is not the single context class available on Great Expectations. Another one is BaseDataContext that is the parent for DataContext and doesn't tend to keep the changes made programmatically in sync with the configuration files. Apart from it, there is also ExplorerDataContext. This class is actually a small mystery for me because the single difference is that initializes a field being an instance of ExpectationExplorer. From the code, we can see that it creates an HTML widget where the results of the expectation are set. The difference is that the widget seems to work only on Jupyter notebooks. I didn't succeed to run it though because on the "PandasDataset' object has no attribute 'data_asset_name'" error.
ExpectationSuite
As the name indicates, this class represents all data validation rules (expectations) defined by the user. It's uniquely identified by a name and stores the list of all rules. Every rule is composed of a type and an arbitrary dictionary called kwargs where you find the properties like catch_exceptions, column, like in this snippet:
{
'expectation_type': 'expect_column_values_to_not_be_null',
'kwargs': {
'column': 'source'
}
}
Every expectation starts with an expect_ prefix and basically they're abstract methods defined in every dataset. So every expectation is specialized depending on the used backend and for instance, in case of an Apache Spark DataFrame column values uniqueness, it looks like:
def expect_column_values_to_be_unique(
self,
column,
mostly=None,
result_format=None,
include_config=True,
catch_exceptions=None,
meta=None,
):
return column.withColumn('__success', count(lit(1)).over(Window.partitionBy(column[0])) <= 1)
For the column length expectation, the method is:
def expect_column_value_lengths_to_equal(
self,
column,
value, # int
mostly=None,
result_format=None,
include_config=True,
catch_exceptions=None,
meta=None,
):
return column.withColumn('__success', when(length_(column[0]) == value, lit(True)).otherwise(lit(False)))
From these 2 snippets you can see one thing. Every expectation is applied separately on the dataset. From Apache Spark and especially big datasets, it can be problematic because Apache Spark will read the dataset once per expectation. Does it really happen? No because SparkDFDataset has a persist attribute that controls whether the input DataFrame should be cached or not, and if not set, it defaults to true:
def __init__(self, spark_df, *args, **kwargs):
# Creation of the Spark DataFrame is done outside this class
self.spark_df = spark_df
self._persist = kwargs.pop("persist", True)
if self._persist:
self.spark_df.persist()
super(SparkDFDataset, self).__init__(*args, **kwargs)
DataSource
The next class is DataSource and its name is also quite self-explanatory. It defines then the place where the data we validate is living. The class also exposes get_batch method that is used by DataContext's get_batch.
DataSource's get_batch method is abstract. Every specific data source like a Spark DataFrame or a SQL table, is responsible for implementing it. Let's check the details for the former example:
if "path" in batch_kwargs or "s3" in batch_kwargs:
path = batch_kwargs.get("path")
path = batch_kwargs.get("s3", path)
reader_method = batch_kwargs.get("reader_method")
reader = self.spark.read
for option in reader_options.items():
reader = reader.option(*option)
reader_fn = self._get_reader_fn(reader, reader_method, path)
df = reader_fn(path)
elif "query" in batch_kwargs:
df = self.spark.sql(batch_kwargs["query"])
elif "dataset" in batch_kwargs and isinstance(batch_kwargs["dataset"], (DataFrame, SparkDFDataset)):
df = batch_kwargs.get("dataset")
# We don't want to store the actual dataframe in kwargs; copy the remaining batch_kwargs
batch_kwargs = {k: batch_kwargs[k] for k in batch_kwargs if k != 'dataset'}
if isinstance(df, SparkDFDataset):
# Grab just the spark_df reference, since we want to override everything else
df = df.spark_df
# Record this in the kwargs *and* the id
batch_kwargs["SparkDFRef"] = True
batch_kwargs["ge_batch_id"] = str(uuid.uuid1())
As you can see, depending on the configuration the DataFrame will be built differently. If we want to process some files, we'll use Apache Spark readers. If the reader is not supported (no reader_method in batch_kwargs or the failure of automatic resolution in SparkDFDatasource#_get_reader_fn, we can directly query a table or work on the dataset created outside Great Expectations. But the last option seems to be working only in a programmatic definition of the data source, like I did in the previous blog post. Just to show you the opposite way, we can work on batches that way:
batch = context.get_batch({'datasource': 'spark_df', 'reader_method': 'json',
'path': '/./input_test.json'}, expectation_suite)
BatchKwargs
You will see, a lot of parts of Great Expectations use Kwargs-like classes. Just to recall, in kwargs in Python is a structure that accepts named arguments. And if you check their implementation in Great Expectations, you will see that the Kwarg-like classes are dictionaries:
class IDDict(dict):
_id_ignore_keys = set()
class BatchKwargs(IDDict):
pass
class MetricKwargs(IDDict):
pass
And more exactly, where they're used? You saw an example before where get_batch method required batch_kwargs parameters describing the data source. Internally, the logic of creating the physical dataset to validate was resolved in this place (Spark case):
if "path" in batch_kwargs or "s3" in batch_kwargs:
# If both are present, let s3 override
path = batch_kwargs.get("path")
path = batch_kwargs.get("s3", path)
reader_method = batch_kwargs.get("reader_method")
reader = self.spark.read
Another way to create batch_kwargs is to use any implementation of BatchKwargsGenerator or the one defined under datasource's batch_kwargs_generators key in the configuration file. Unfortunately, I didn't manage how to do use these generators. I tried the DataContext's build_batch_kwargs by specifying the data source name and the generator name, but it always ended with an error (ex. "'NoneType' object has no attribute 'update'" on line 72, in _get_iterator, asset_definition.update(datasource_batch_kwargs)). I tried to find the examples but all of them used directly created batch_kwargs, like I did in the previous section. So maybe generators are something that is not supposed to be used in the pipeline definition?
Batch
The Batch class represents the dataset that will be validated. Still depending on the data source type, it will be built differently depending on the provided kwargs. In the case of an Apache Spark source, the batch will contain the built DataFrame alongside the metadata information from the configuration:
return Batch(
datasource_name=self.name,
batch_kwargs=batch_kwargs,
data=df,
batch_parameters=batch_parameters,
batch_markers=batch_markers,
data_context=self._data_context
)
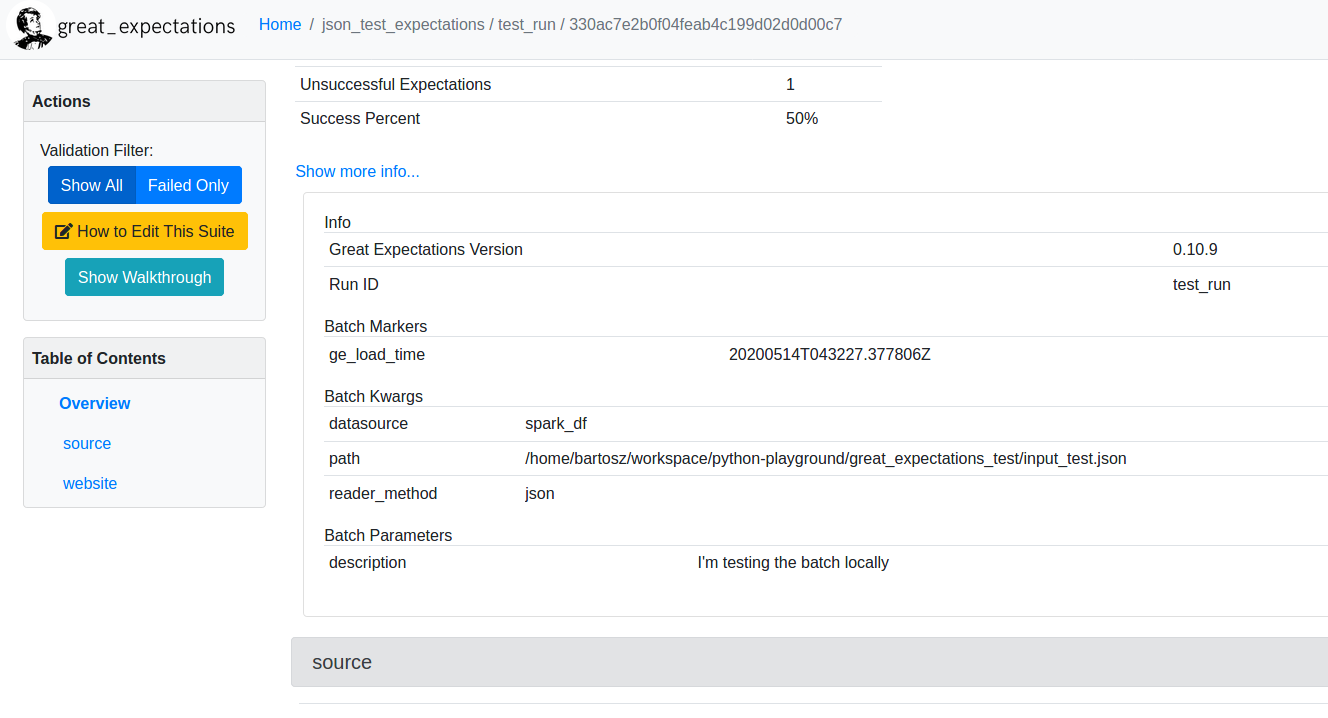
From the above snippet you can see some of the properties of the validated Batch. Unsurprisingly, it stores the physical data to validate (data attribute), but also some other parameters like batch_parameters (eg. asset or partition name, so all information describing the particular batch instance) or batch_markers (metadata about the given batch, like load time represented as ge_load_time in Spark source). The batch_parameters can be passed in the get_batch method, that way:
batch = context.get_batch({'datasource': 'spark_df', 'reader_method': 'json',
'path': '/home/bartosz/workspace/python-playground/great_expectations_test/input_test.json'},
expectation_suite,
batch_parameters={'description': "I'm testing the batch locally"})
Regarding batch_markers, they seem to be generated internally by Great Expectations. Both can be visualized at the end on the Great Expectations summary for every validation run:
ValidationOperator
This is the final class in our exploration responsible for the data validation (it couldn't be different, classes and variables are quite well named in the project; "There are two hard things in computer science: cache invalidation and naming things" if you don't know why I'm highlighting this point). ValidationOperator is an abstract class implemented by:
- ActionListValidationOperator - this operator validates every batch and passes the validation results to every action defined in the configuration. Among these actions you can find the operations like StoreValidationResultAction (store validation results) or UpdateDataDocsAction (updates the documentation generated by the validation).
- WarningAndFailureExpectationSuitesValidationOperator - as the previous one, it can invoke some custom actions on the validation results but unlike ActionListValidationOperator, it divides the expectations into "critical" and "warnings". It lets you stop the validation pipeline when one of the critical rules is broken. How does the operator know which one is considered as critical? You define these 2 classes in the configuration file and later use these keys to group your expectations depending on the criticality level.
The physical validation is performed inside the run method which returns an object with the validation outcome.
In this second blog post about Great Expectations we've discovered the main classes involved in a data validation code. We learned about a DataContext that coordinates the whole execution and more the "worker" parts like ExpectationSuite, Batch, and ValidationOperator. In the next blog post from the series, I will check how to orchestrate the validation pipeline.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data validation frameworks - Great Expectations and orchestration
- Data validation frameworks - introduction to Great Expectations
- Data validation frameworks - Deequ and Apache Griffin overview
- Extended JSON validation with Cerberus - error definition and normalization
- Validating JSON with Apache Spark and Cerberus
The second part of @expectgreatdata exploration is online. If you want to learn more about the key classes responsible for the data validation logic in Great Expectations, read ? https://t.co/lspt9ncnrA
— Bartosz Konieczny (@waitingforcode) August 9, 2020