
So far I played with Great Expectations and discovered the main classes. Today it's time to see how to automate our data validation pipeline.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The pipeline I gonna try to validate looks like that:
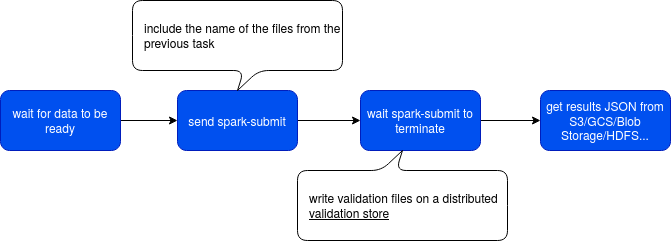
This execution flow has nothing strange regarding a standard way of processing some data. First, we're waiting for the data to process to be available with one of the available sensors. In the second task we prepare the spark-submit with the parameters corresponding to the execution context. After sending this command, the DAG waits for the process to terminate. Since it's hard to communicate directly between the compute and orchestration servers, the validation results are written to some normalized directory and read back in the last step by the DAG. After reading them, the task can throw an exception, if the validation fails.
Stores
Before I show you the code, some precision. First, in the picture I underlined the "validation store". In Great Expectations a store, represented by Store class implementations, is the place where the framework reads or writes the data. You can find then a store for the list of expectations or the validation results. Every store has an associated backend being an implementation of StoreBackend, responsible for the physical manipulation of the files. The following snippet coming from great_expectations.yml shows these 2 concepts:
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
Among the supported backends you will find S3 or GCS connectors, respectively in TupleS3StoreBackend and TupleGCSStoreBackend classes. A single difficulty I see so far is the fact that we cannot easily control the name of the validation results. Files with random names, like the following ones, are generated for every validation run:
test_run \-- 07572f5803f006d1b5ba1c4e499e2549.json \-- 25ace0091de735f5691e53e61b8fa8f3.json \-- 330ac7e2b0f04feab4c199d02d0d00c7.json \-- 6038afa4e51294d813271181dc12bc44.json \-- 6a177d88980f231e7b2a789b75d93b2e.json \-- bf8de2e627a7b48933a4caf9e5734c5d.json \-- d3ae0bbda6b43d51f3b062ddecc324eb.json \-- ddb42540ca2eeacfe0f08fc9f6d485be.json 0 directories, 8 files
The drawback of that approach will be a big number of small files on your bucket - even though you can mitigate that by setting a short TTL of your bucket. Fortunately, these backend classes can also be customized and that will be the approach here.
Getting one partition data
I didn't mention it before but the goal of my pipeline is to run it on top of hourly-partitioned data. That being said, I don't know if it's the right pattern to apply for the validation with Great Expectations, but my goal is to have the feedback about as soon as possible and at the same time, stay in batch mode. When reading the documentation about Batch Kwargs Generator Module, I saw that we could use these generators with RegExes but as far as I understand their purpose, they can be used only for matching. In other words, it cannot be used to select a different partition at every validation run (but if I'm wrong, please fix me in the comment!).
By mistake I found a solution to my problem in the first blog post of the series, where I discovered the possibility to manually configure the batch parameters. To keep things simple, I will use this approach in my code.
The code
The first important task is the one generating the parameters for the spark-submit command. But it's not the hardest one because we can use Airflow's task context and get anything we need. For our use case, we need only the execution time that is the basic for the partition resolution that we can retrieve from {{ ts_nodash }} macro.
The second important component is the data validation task. As said before, it has to use a different partition every hour and this requirement can be easily fulfilled with our input parameters resolved in the above snippet. A harder thing is the store backend. Well, not exactly because depending on what you can afford (small files vs more complex retrieval of validation file if you decide to put all files for a given run together, even the reprocessed one), you can use the built-in solutions. In my case, mostly to make some exercise, I decided to code my backend store that will write one file for every run, even the reprocessed ones:
"""
great_expectations.yml declaration:
# ...
validations_store:
class_name: ValidationsStore
store_backend:
module_name: extensions.custom_backend_store
class_name: IdempotentFileNameStoreBackend
base_directory: uncommitted/validations/
# ...
"""
from great_expectations.data_context.store import TupleFilesystemStoreBackend
class IdempotentFileNameStoreBackend(TupleFilesystemStoreBackend):
def __init__(self, base_directory,
filepath_template=None,
filepath_prefix=None,
filepath_suffix=None,
forbidden_substrings=None,
platform_specific_separator=True,
root_directory=None,
fixed_length_key=False):
super().__init__(base_directory=base_directory,
filepath_template=filepath_template, filepath_prefix=filepath_prefix,
filepath_suffix=filepath_suffix, forbidden_substrings=forbidden_substrings,
platform_specific_separator=platform_specific_separator,
root_directory=root_directory, fixed_length_key=fixed_length_key)
def _set(self, key, value, **kwargs):
key_items = list(key)
key_items[len(key)-1] = 'validation_result'
super()._set(tuple(key_items), value, **kwargs)
However, please notice that having different files is required if you need to archive your results. For example, it can be useful if you have a data producer and want to check how its quality changed after fixing a regression. Another solution, even less cumbersome, is the storage of the results in a key/value store. But to keep things simple, I decided to implement by own store extending already existing TupleFilesystemStoreBackend.
The validation code executed on the cluster would look then like that:
partition_date = sys.argv[1]
context = ge.data_context.DataContext()
input_data_path = f'/home/bartosz/workspace/python-playground/great_expectations_test/partition/{partition_date}'
batch = context.get_batch(batch_kwargs={'datasource': 'spark_df', 'reader_method': 'json', 'path': input_data_path},
expectation_suite_name="logs.warning",
batch_parameters={'partition': partition_date})
results = context.run_validation_operator(
'action_list_operator',
assets_to_validate=[batch],
run_id=f'logs_{partition_date}'
)
print(f'Got result {results}')
And finally, the task retrieving the results from Airflow DAG:
def check_data_validation_results(**context):
partition_date = context['execution_date']
input_data_path = f'/home/bartosz/workspace/python-playground/great_expectations_test/' \
f'great_expectations/uncommitted/validations/logs/warning/logs_{partition_date}/validation_result.json'
with open(input_data_path) as validation_result_file:
validation_result = json.load(validation_result_file)
if not validation_result['success']:
raise RuntimeError(f'Validation failed for batch {partition_date}')
validate_results = PythonOperator(
task_id=validate_results,
provide_context=True,
python_callable=check_data_validation_results
)
I simulated my proposal with decoupled code snippets and omitted a few things for brevity. But the idea is there. Thanks to the flexibility of Great Expectations, I was able not only to read a dynamic (partitioned) dataset to validate but also write it into a custom storage backend.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data validation frameworks - Great Expectations classes
- Data validation frameworks - introduction to Great Expectations
- Data validation frameworks - Deequ and Apache Griffin overview
- Extended JSON validation with Cerberus - error definition and normalization
- Validating JSON with Apache Spark and Cerberus
The final part of my @expectgreatdata exploration is online. As announced previously, it shows a way to integrate Great Expectations with #ApacheAirflow and partitioned data ? https://t.co/l64oH85X2W
— Bartosz Konieczny (@waitingforcode) August 23, 2020