
When I published my blog post about Deequ and Apache Griffin in March 2020, I thought that there was nothing more to do with data validation frameworks. Hopefully, Alexander Wagner pointed me out another framework, Great Expectations that I will discover in the series of 3 blog posts.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
It's the first post presenting Great Expectations. Since you can find a lot of information in the official documentation, I will try to focus on how to start to work with the framework, still trying to explain some implementation details. In this introductory part, you will discover the main components of the framework with a very simple data validation pipeline.
Building blocks
Great Expectations is a Python data validation framework. But don't get me wrong, it doesn't perform any data validation on its own. Instead, it delegates the physical execution of your validation rules to the available backends like PySpark or Pandas. A nice thing is that you can also plug it to Apache Airflow to have a fully automated data validation pipeline. It's a more advanced concept, but since it's close to my center of interest, I will describe in one of the next blog posts.
What do you need to do to write your own data validation rules? To run your pipeline you will need:
- One or multiple data sources with the dataset you want to validate.
- At least one data validation rule called expectation. You will understand why it's called so when you will see the code of the next section.
- A data store to save the results of your validations but also the definitions of your expectations. Because yes, the whole configuration is stored in .yaml and .json files. To generate these files, and globally the whole structure of the project, the framework provides very convenient CLI. The great_expectations init command should help you in the setup.
This short introduction should be sufficient to understand the code snippets from the next part.
Basic example
No worries if this part seems too high level, I will focus on the implementation details in the next blog post :) Meantime, let's continue with our basic example. The main requirement to run a Great Expectations pipeline is to define a great_expectations.yml file. I'm using here the default one generated by the CLI introduced above:
config_version: 1.0
datasources:
spark_df:
module_name: great_expectations.datasource
data_asset_type:
module_name: great_expectations.dataset
class_name: SparkDFDataset
class_name: SparkDFDatasource
config_variables_file_path: uncommitted/config_variables.yml
plugins_directory: plugins/
validation_operators:
action_list_operator:
class_name: ActionListValidationOperator
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
evaluation_parameter_store:
class_name: EvaluationParameterStore
expectations_store_name: expectations_store
validations_store_name: validations_store
evaluation_parameter_store_name: evaluation_parameter_store
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
anonymous_usage_statistics:
enabled: true
data_context_id: 396f985e-a877-4533-9284-71e1f901f228
The expectations could also be defined in the configuration file but to keep the most things possible in a single place, I will define them in the application code:
expectation_suite = ExpectationSuite(
expectation_suite_name='json_test_expectations',
expectations=[
{
'expectation_type': 'expect_column_values_to_not_be_null',
'kwargs': {
'column': 'source'
}
},
# I'm introducing the check on a not existing column on purpose
# to see what types of errors are returned
{
'expectation_type': 'expect_column_to_exist',
'kwargs': {
'column': 'website'
}
}
]
)
Do you remember when I said that you will understand why the validation rules are called expectations? As you can see in the snippet, all the rules start by expect_ prefix, hence quite naturally we can call them expectations :] After that, I'm loading the dataset to validate from PySpark:
spark = SparkSession.builder.master("local[2]")\
.appName("JSON loader").getOrCreate()
# file comes from https://github.com/bartosz25/data-generator
json_dataset = spark.read.json('/home/bartosz/workspace/python-playground/great_expectations_test/input_test.json',
lineSep='\n')
I didn't succeed to configure a JSON file as a valid source and that's the reason I'm loading it here from Apache Spark DataFrame - but you will see in my 3rd post from the series that we can do it differently, without involving Apache Spark. Later on, I'm defining the validation part which must start with DataContext initialization:
context = ge.data_context.DataContext()
# BK: I didn't find a way to overcome this limitation. The `datasource` parameter
# has to be specified in the `batch_kwargs` and it also has to exist in the
# `great_expectations_cli.yml` configuration.
batch_kwargs = {'datasource': 'spark_df', 'dataset': json_dataset}
batch = context.get_batch(batch_kwargs, expectation_suite)
As of this moment, nothing happens but remember the concept of batch that represents a part of the dataset to validate, or the whole dataset like in our case. To execute the validation, we have to call run_validation_operator and apply it to the batches we created so far:
# BK: As above, the operator's name must be defined in the `great_expectations_cli.yml` file
results = context.run_validation_operator(
'action_list_operator', assets_to_validate=[batch], run_id='test_run'
)
The result variable is an object that contains, among others:
- a success field to say whether the batches break or don't break the expectations
- a results array that will contain the validation result for every expectation
Below you can find a snippet with these 2 response components:
{
'success': False,
'details': {
ExpectationSuiteIdentifier::json_test_expectations: {
'validation_result': {
"statistics": {
"evaluated_expectations": 2,
"successful_expectations": 1,
"unsuccessful_expectations": 1,
"success_percent": 50.0
},
"success": false,
"results": [
{
"expectation_config": {
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "source",
"result_format": "SUMMARY"
},
"meta": {}
},
"success": true,
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_message": null,
"exception_traceback": null
},
"result": {
"element_count": 2,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"partial_unexpected_index_list": null
}
},
{
"expectation_config": {
"expectation_type": "expect_column_to_exist",
"kwargs": {
"column": "website",
"result_format": "SUMMARY"
},
"meta": {}
},
"success": false,
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_message": null,
"exception_traceback": null
},
"result": {}
}
],
// ...
}
But that's not all. Great Expectations also offers a way to directly visualize your data visualization records! If you call context.open_data_docs() at the end of your pipeline, you will be able to visualize the Python object presented before in your browser:
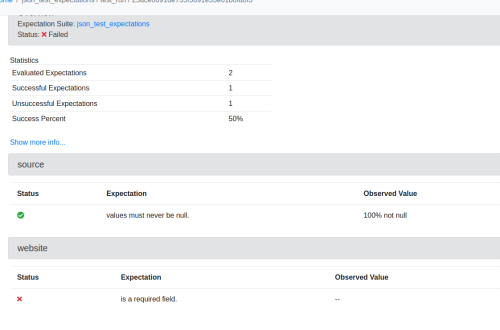
In this first post about the Great Expectations framework I presented its main components like data sources and expectations, and also wrote a very basic data validation pipeline to see them in action. In the next blog post I will focus more on the implementation details to discover how these components work together.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data validation frameworks - introduction to Great Expectations here:
Related blog posts:
- Data validation frameworks - Great Expectations and orchestration
- Data validation frameworks - Great Expectations classes
- Data validation frameworks - Deequ and Apache Griffin overview
- Extended JSON validation with Cerberus - error definition and normalization
- Validating JSON with Apache Spark and Cerberus
Are you looking for a #data validation framework ? ? The series on the blog continues, and this time you can discover Great Expectations (@expectgreatdata)! The first of 3 posts is online https://t.co/sz3AWJSP2G
— Bartosz Konieczny (@waitingforcode) July 26, 2020