
When I first heard about Durable Functions, my reaction was: "So cool! We can now build fully serverless streaming stateful pipelines!". Indeed, we can but it's not their single feature!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Durable functions - easy view
An agnostic durable functions workflow can look like in the following schema:
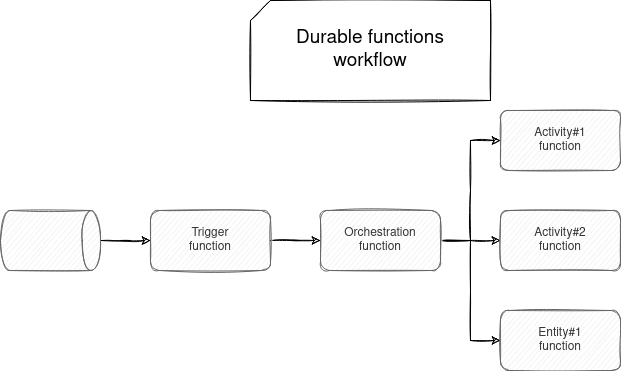
Everything starts with a trigger function. In the schema, it reads some streaming data, but you can also trigger it explicitly from an HTTP endpoint. No surprise, its responsibility is to intercept an event and eventually start the workflow.
In the next step, an orchestration function starts the coordination of all tasks composing the workflow. An interesting thing to notice here is the workflow representation. It's not expressed - at least in the code - as Azure Function. It's simply a method invocation, a little bit like in RPC protocol.
If we translated it to a data processing framework, so far, we've only seen the input reading and execution plan stages. But nothing has been done yet! The work starts after executing the orchestration logic. At this moment, the orchestrator starts one or multiple activities.
Along with the activities, the workflow can also have entity functions. The difference with the activities is their explicit state management and the lack of required orchestrator. The trigger function can directly trigger them as well!
Durable functions - complete view
But that was only for an easy view of the Durable Functions. To manage the orchestration and the state, the framework relies on a storage component which by default is an Azure Storage:
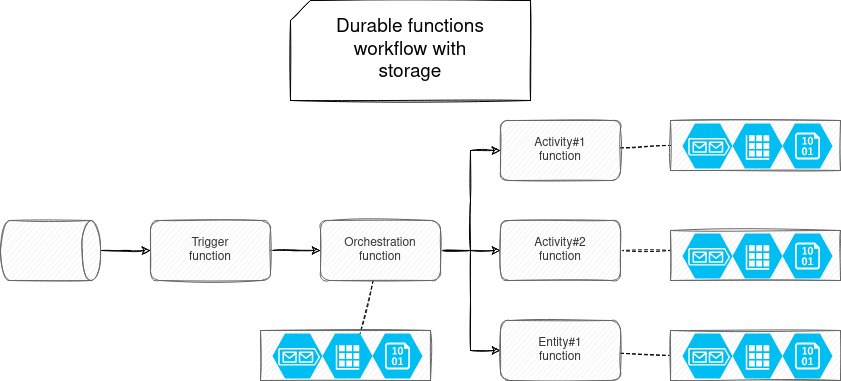
Each function has a component called task hub. It's a Storage Account composed of a: queue, table, and blob. Each of these services has a dedicated role in the workflow. The queue ensures communication between the functions. The table stores the state orchestration information like the activity or entity function status. It's also the place for the entity state - as long as the payload is smaller than the storage limit. When it happens, the framework stores the state in the blob and only references it in the table.
Azure Storage Account is the default and, as of this writing, the most mature storage provider. However, Azure works on more efficient backends like Netherite.
Pipeline example
I could have written much more about the theoretical parts of the Durable Functions, but it's not the goal. With the information presented so far, you should be able to understand an example of the framework. I'm going to use the Storage Emulator so that you can play around with the code even if you don't have an Azure subscription.
The entrypoint for my example will be an HTTP-triggered function. It will do 2 things. To start, it will directly call an entity function to demonstrate the session state management. After that it will trigger an orchestrator.:
async def main(req: func.HttpRequest, starter: str):
run_id = req.params.get('run_id')
client = DurableOrchestrationClient(starter)
entity_state_key = f'my_counter_{run_id}'
entity_id = EntityId(name='session_handler', key=entity_state_key)
await client.signal_entity(entity_id, "add", 2)
await client.signal_entity(entity_id, "get")
instance_id = f'instance{run_id}'
await client.start_new('message_orchestrator', instance_id, {'hellos_count': req.params.get('hellos_count')})
return func.HttpResponse(status_code=202)
The entity function has 2 goals. First, it will read and write the state with the available getters and setters. Second, it will grow to a size that will not be accepted anymore as a serialized entry in the Table Storage. Instead, the state will go to a Blob object and the entry in the table will be transformed to a Blob reference. I omitted the state text for brevity but you can replace it by "Lorem ipsum..." generated text on 11 paragraphs:
When it comes to the orchestrator, it'll call an activity function with 2 different parameters. The activity function will simply return a "Hello world"-like text:
def orchestrator_function(context: df.DurableOrchestrationContext):
logging.info(f'Got input {context.get_input()}')
input_params = context.get_input() # this time, it's a dict!
number_of_hellos = input_params['hellos_count']
result1 = yield context.call_activity('message_logger', f'Text 1 - {number_of_hellos}')
result2 = yield context.call_activity('message_logger', f'Text 2 - {number_of_hellos}')
return [result1, result2]
def main(name: str) -> str:
return f"Hello{name}!"
The code is available in my Github wfc-playground/azure-durable-function project. And you can find it in action in the demo just below:
Durable Functions are a native way to perform data orchestration tasks or stateful processing with Azure Functions. The solution leverages other Azure services to keep the state of the entity and the orchestration runs.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Azure Durable Functions here:
- Durable Functions 2.0 - Serverless Actors, Orchestrations, and Stateful Functions Durable Functions types and features Data persistence and serialization in Durable Functions (Azure Functions) New Storage Providers for Azure Durable Functions
Related blog posts:
- Azure Synapse Link as Hybrid Transactional/Analytical Processing
- Shedding some light on Azure SQL
- Data pipeline patterns with Azure Data Factory
In the first cloud blog post after the break, I played a bit with Azure Durable Functions extension to discover the function types and state management ? https://t.co/I1atSh4LQr
— Bartosz Konieczny (@waitingforcode) October 17, 2021