
Almost 2 years ago (already!), I wrote a blog post about data pipeline patterns in Apache Airflow (link in the "Read also" section). Since then I have worked with other data orchestrators. That's why I would like to repeat the same exercise but for Azure Data Factory.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the mentioned article, I described 4 patterns. This time I'd like to add 3 new ones. They weren't present in the inspiration paper but are interesting to discover from a Data Factory perspective.
Sequence
That's probably the easiest one. It executes the tasks in a sequence, one after another. In Data Factory, you can create it by connecting the activities. You can see an example in the following picture where after copying the data from an on-premise storage to the cloud, I'm running a data cleansing Databricks Python job:
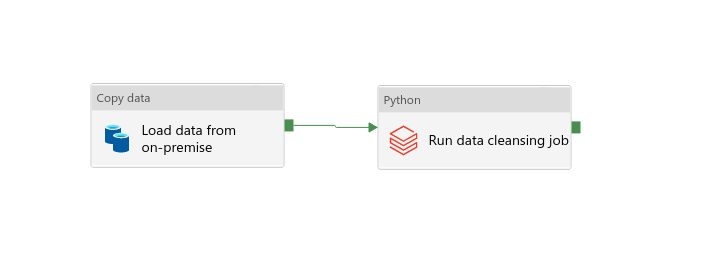
Parallel split
It's a special version of the sequence pattern. It creates 2 or more branches from a common root task and runs them in parallel. It can be a good pattern for the migration scenarios where you might want to keep old and new versions of the pipeline available to the users. You can see an example just below with an "old" Pig job and a "new" Databricks job:
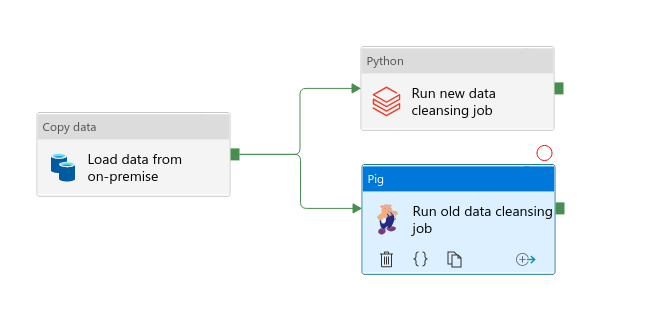
Synchronization
It's the opposite of the parallel split. This time multiple separate but concurrently executed activities merge into a single one. You can use it if the branch tasks are of a different type or when you want to parallelize 2 heavy processes (= parallelized should terminate faster). An example is just below with a branch running a Databricks data validation job and activity loading a lot of data from an external service. Both are the requirements to run the last job processing the input data and enriching it with the external dataset:
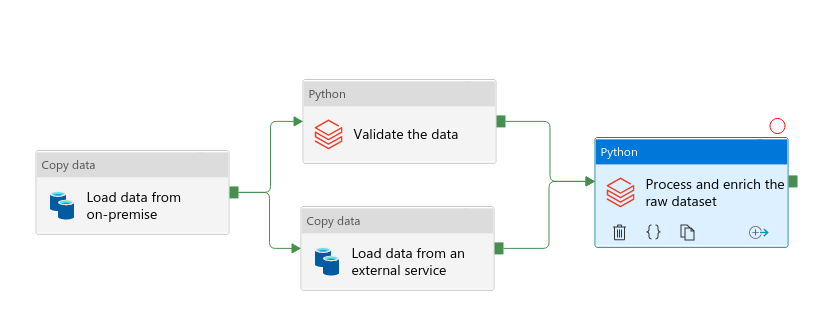
Exclusive choice
The next ETL pattern you can find in Azure Data Factory relies on the if-else statement. Depending on the evaluation of a conditional expression, it either follows the "True" activities or "False" activities. It can be a good solution to handle external changes like a new input dataset location. Below you can see an example where the pipeline runs a legacy pipeline for on-premise datasets from 2000 and a modern pipeline otherwise:
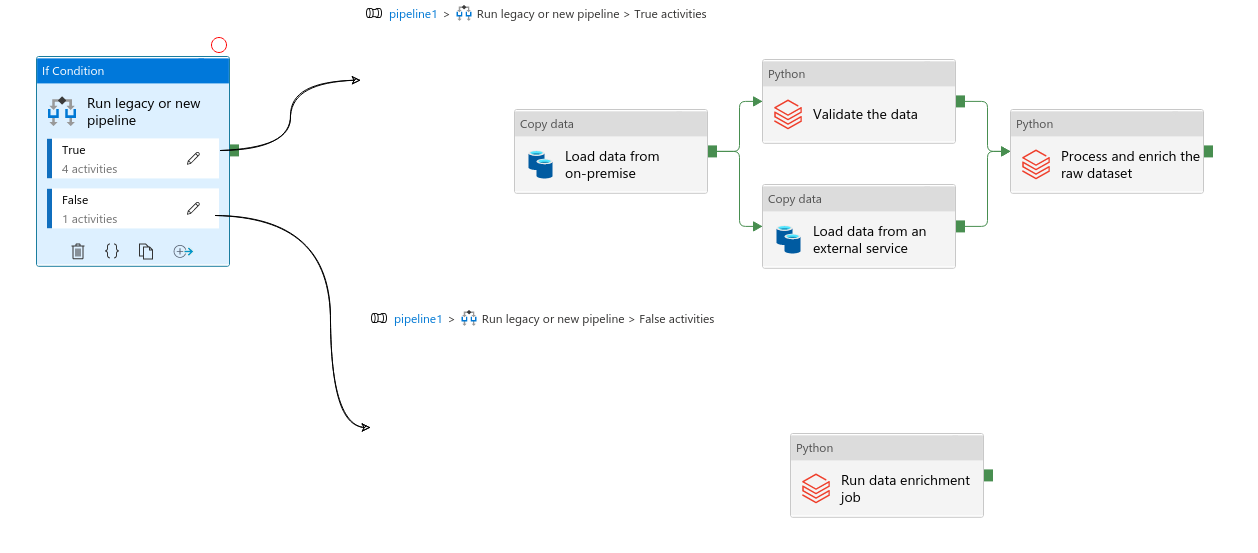
Data sensor
Another pattern you can implement with Azure Data Factory is a data sensor. Use it if you want to process the data once it's fully generated. It can be a good solution for any time-partitioned data sources having a marker indicating the fully written dataset, like the _SUCCESS file in Apache Spark jobs:
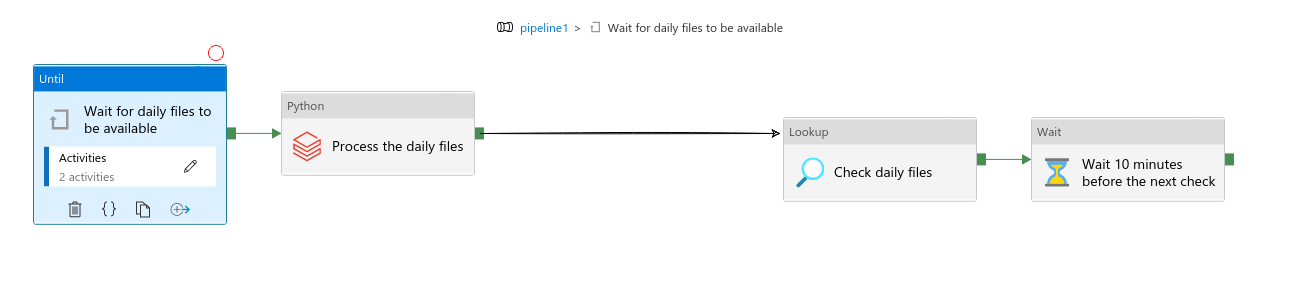
Outcome-dependent execution
In the last pattern you can add a dependency on a parent task result. This result will condition the execution of the downstream tasks, like in the following schema where "Copy default model" runs only if the "Process the daily files" fails:
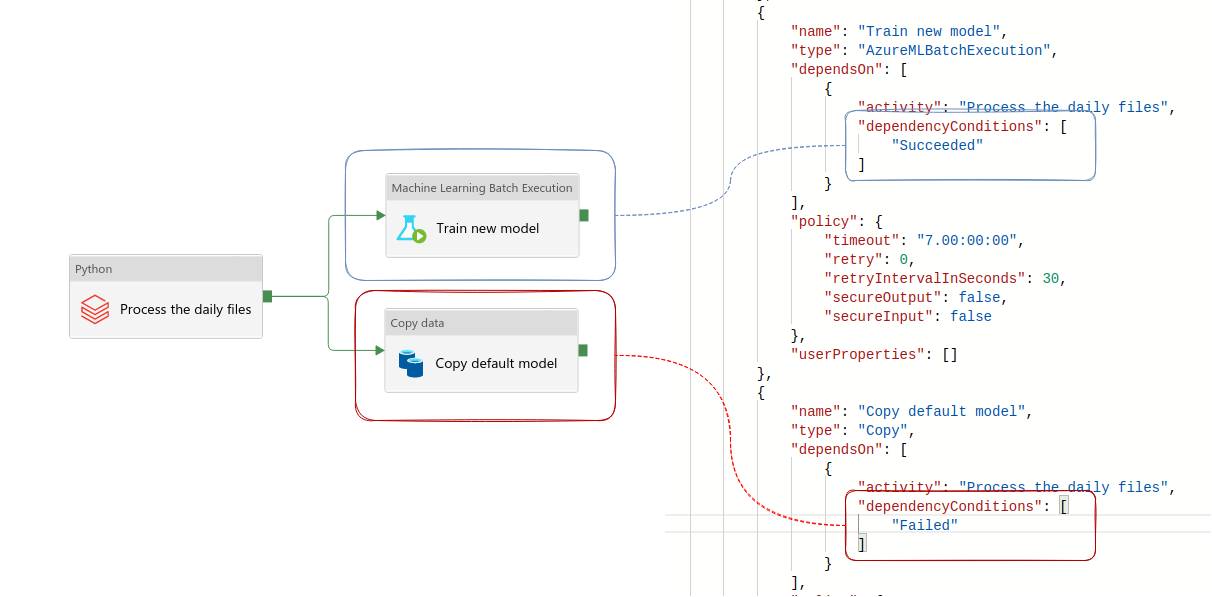
Azure Data Factory remains a data orchestrator despite using a no-code paradigm, and it doesn't require completely new data engineering skills. Sure, you will have it to adapt a different deployment process, but when it comes to the pipelines patterns, you can use the same as in Apache Airflow. They're patterns after all!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data pipeline patterns with Azure Data Factory here:
Related blog posts:
- Azure Synapse Link as Hybrid Transactional/Analytical Processing
- Shedding some light on Azure SQL
- Azure Durable Functions
Apart from blogging, I also like finding patterns. Inspired by an Apache Airflow blog post from 2 years ago, I recently wrote about data pipeline patterns in Azure Data Factory ? https://t.co/XNoNe0SrwJ
— Bartosz Konieczny (@waitingforcode) August 15, 2021