
Some time ago I found an article presenting ETL patterns. It's quite interesting (link in "Read more" section) but it doesn't provide code examples. That's why I will try to complete it with the implementations for presented patterns in Apache Airflow.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is divided into 4 sections. Each section describes one ETL pattern illustrated with an example of an Apache Airflow DAG. The first presented pattern is sequential pattern, which is the simplest from the 4 patterns. The next section talks about a pattern called parallel split. In the third part, you will discover synchronization pattern whereas in the last one, exclusive choice pattern.
Sequence
The first pattern has not a lot of mystery since it represents a simple sequence of different tasks, executed one after another. Since there is no magic here, I will give you a simple implementation in Apache Airflow just here:
dag = DAG(
dag_id='sequential_pattern',
default_args={
'start_date': utils.dates.days_ago(1),
},
schedule_interval=None,
)
with dag:
read_input = DummyOperator(task_id='read_input')
aggregate_data = DummyOperator(task_id='generate_data')
write_to_redshift = DummyOperator(task_id='write_to_redshift')
read_input >> aggregate_data >> write_to_redshift
Parallel split
Here the sequential character of the pipeline is replaced by a parallel execution of two or multiple branches. This pattern is helpful when you need to load one dataset into multiple different places, with different formats but within the same pipeline. Since it's a little bit more complex than the previous pattern, let's see it in an image:
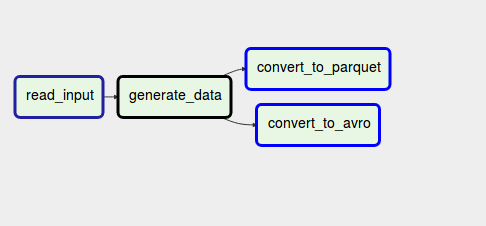
As you can see, the pipeline starts by generating some dataset. Later, this dataset is processed by 2 branches where one of them converts the data into Apache Parquet files whereas another one into Apache Avro files. To implement parallel split in Apache Airflow you can simply set multiple downstream tasks:
dag = DAG(
dag_id='pattern_parallel_split',
default_args={
'start_date': utils.dates.days_ago(1),
},
schedule_interval=None,
)
with dag:
read_input = DummyOperator(task_id='read_input')
aggregate_data = DummyOperator(task_id='generate_data')
convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
convert_to_avro = DummyOperator(task_id='convert_to_avro')
read_input >> aggregate_data >> [convert_to_parquet, convert_to_avro]
Synchronization
The 3rd pattern is the follow-up for parallel split. Synchronization pattern will take the output generated in each of the branches and reconcile it. Thanks to it, you take advantage of parallel processing of branches and still end up with a single process conciliating the branches at the end.

As you can see in the schema, we're generating Parquet files daily and at the end of the generation, we move all of them into an appropriate partition directory. Synchronization pattern in Apache Airflow still uses multiple downstream tasks. The difference is that at the end one task waits for all upstream tasks to terminate:
dag = DAG(
dag_id='pattern_synchronization',
default_args={
'start_date': utils.dates.days_ago(1),
},
schedule_interval=None,
)
with dag:
convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
for hour in range(0, 24):
read_input = DummyOperator(task_id='read_input_hour_{}'.format(hour))
aggregate_data = DummyOperator(task_id='generate_data_hour_{}'.format(hour))
read_input >> aggregate_data >> convert_to_parquet
Exclusive choice
The last pattern also uses branches but it does the opposite of 2 previous ones. Instead of following all branches, it chooses a single one to follow. Hence, it behaves like an ETL if-else expression.
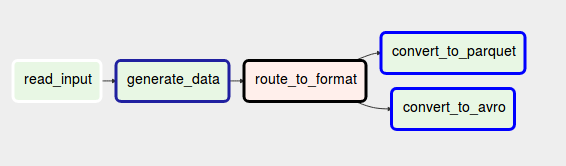
Exclusive choice can be useful in different situations. Imagine that you want to keep your pipeline idempotent, so execute the same application logic. But you don't want to freeze the code and want to be able to change the code from time to time. Exclusive choice can help to achieve this. With this pattern you will execute one branch or another, depending on some condition specified in the condition.
In Apache Airflow you can implement it with BranchOperator:
dag = DAG(
dag_id='pattern_exclusive_choice',
default_args={
'start_date': utils.dates.days_ago(1),
},
schedule_interval=None,
)
with dag:
def route_task():
execution_date = context['execution_date']
return 'convert_to_parquet'if execution_date.minute % 2 == 0 else 'convert_to_avro'
read_input = DummyOperator(task_id='read_input')
aggregate_data = DummyOperator(task_id='generate_data')
route_to_format = BranchPythonOperator(task_id='route_to_format', python_callable=route_task)
convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
convert_to_avro = DummyOperator(task_id='convert_to_avro')
read_input >> aggregate_data >> route_to_format >>
Design patterns also exist in the case of ETL data pipelines. This post presented 4 of them, from the simplest sequential pattern to more complex ones involving multiple, sometimes parallel, branches. If you know any other interesting pattern that deserves to be discussed, add a comment and I will update the post accordingly.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about ETL data patterns with Apache Airflow here:
Related blog posts:
- Data Engineering Design Patterns: Dynamic Data Overwriter
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
In the second post of this week I prepared a short illustration of ETL batch patterns with #ApacheAirflow https://t.co/reyc7RQiez
— Bartosz Konieczny (@waitingforcode) August 4, 2019