
If you're interested in stream processing, I bet your thinking is technology-based. It's not wrong, after all, the ability to use a tool gives you and me a job. However, for a long-term consideration it's better to reason in terms of patterns or models. Being aware of a more general vision helps assimilate new tools.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Micro-batch - synchronous
The first model is micro-batch. It's probably the easiest one to understand for the data engineers working with batch pipelines only since it's only a continuous variation of them.
Let's say you used to work with batch jobs triggered every hour to process the data accumulated in the past hour. It's the batch. The micro-batch will divide this hourly range into multiple smaller ones, which implies:
- Less data processed in each batch unit.
- Smaller hardware needs since the big batch dataset is processed incrementally, in smaller chunks, over the hour.
- Lower latency as the processing takes data almost as soon as it arrives ["almost" because it depends on the micro-batch duration].
However, the micro-batch model also suffers from the batch heritage. It's especially visible for the data skew problem. If one task within the micro-batch must process more data than the others, this task will block the processing and increase the overall latency and so even if the other tasks are fast.
Additionally, the micro-batch often has a higher latency since it inherits the batch schedule behavior. Put another way, it runs every x seconds/minutes and processes all data accumulated during that period. It can be disabled, though, but still the latency should be higher due to this batch unit.
Example: Apache Spark Structured Streaming.
Micro-batch - asynchronous
Thankfully, the micro-batch doesn't have to be a blocking one. There is an asynchronous version that overcomes the data skew problem. Here, the trigger mechanism is task-based, meaning that each of them will still process a bulk of records but they won't necessarily start at the same time. As a result, a skewed task will have more latency but the other ones will not.
Since the tasks are isolated, it might be difficult to perform aligned aggregations for the micro-batches, as for the synchronous version.
Examples: Apache Spark Structured Streaming continuous mode [experimental].
Dataflow
Another pattern is the dataflow one. It's often defined as a graph of operators that represents data flowing from the source(s) to the sink(s). That's clear but if you compare this definition with Apache Spark, you may be lost. After all, Apache Spark also represents its internal computation as a graph. If you don't believe me, try to analyze the visual query representation in Spark UI:
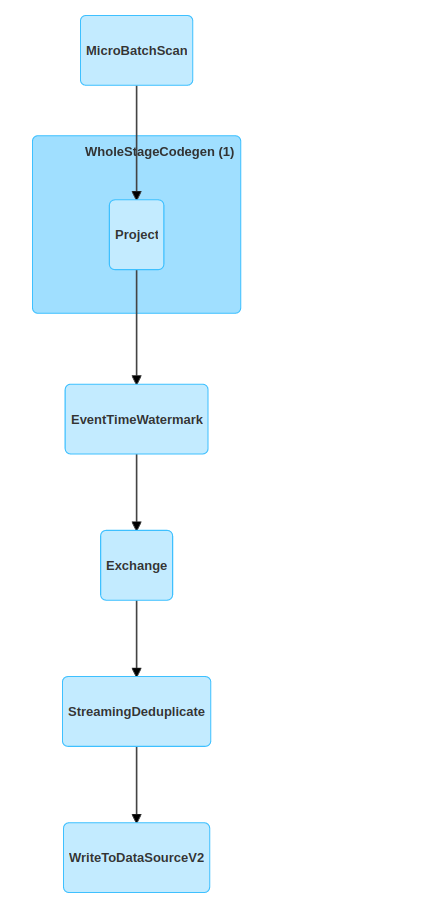
That's why it's better to use a definition more adapted to the streaming models. The big difference with the micro-batch and the dataflow is that the tasks are fully isolated. Crystal clear? Not really, I'm still confused since we've been talking about an asynchronous micro-batch just before.
To get an even better understanding, we must go back to the data source operator. Below is what happens in micro-batch for an Apache Kafka data source:
- Start a new micro-batch unit as soon as the previous micro-batch completes or the micro-batch time trigger fires (e.g. for a trigger set to 15 seconds, a new micro-batch is scheduled every 15 seconds).
- Resolve the offsets to process.
- Propagate the offsets for each task.
- Start as many tasks as possible.
- Wait until all tasks complete.
- Perform some checkpointing logic if necessary.
- Start again with another micro-batch.
The dataflow is different and the logic can be:
- Start one data source task for each Kafka partition.
- Fetch the offsets and propagate them to the next operator.
- Pass the result from this operator to another one.
- Fetch new offsets to process and pass to the closest operator to the data source.
- Repeat...
Visually it gives something like:
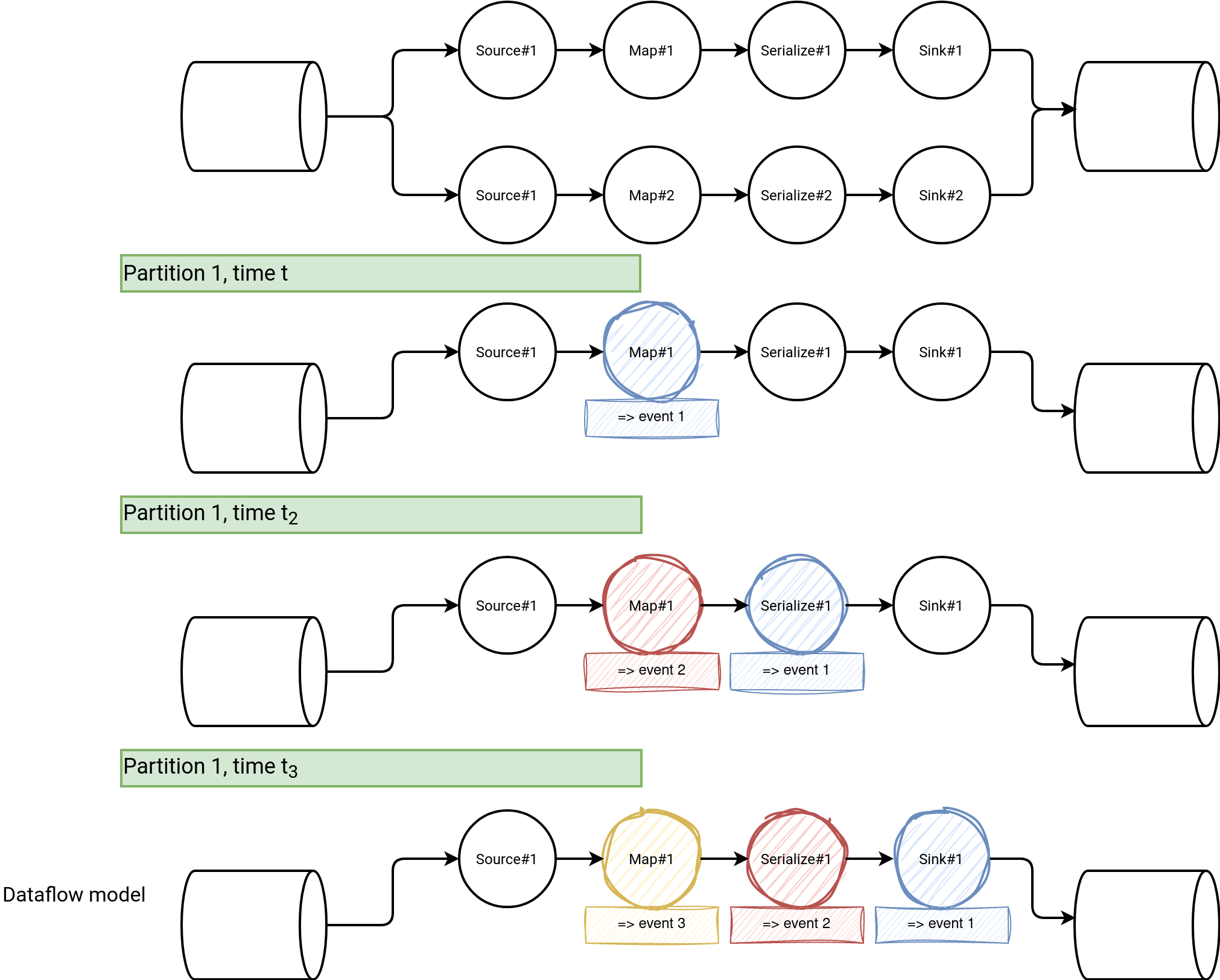
What happens here? As you can see, the nodes of the dataflow graph doesn't need to be synchronized, i.e. the Map#1 won't process the 3 events all together as it would happen in the micro-batch. Instead it processes each record and passes it to the next operator as soon as possible. Just after, it starts processing the next record, and so on and so on. Of course, if one record cannot be processed, it won't move to the next operator.
Besides this data processing semantic, there are also other differences that I will quote in the next section to better understand the difference between the dataflow and the continuous update model.
Examples: Apache Flink, GCP Dataflow.
Continuous update model
Another key point of the dataflow model is that it considers streaming data assets, as windows, as being completed at some point. It's when the watermark cames into play and decides whether a window should be closed and as a result, the job shouldn't accept any other input events for it. It means no more no less than very late records won't be integrated to the window.
It's not the case of the continuous update model which doesn't consider streaming assets as completed and always updates them, even when the events are really old. The data model is considered then as a stream of revisions where each change updates the computation state.
This continuous refinement model can have some state reset capability, for example, to handle alerting scenarios. In that case, an alert will fire whenever the alerting condition is met for the first time. That's fine. But without the reset capability, it'll fire for all subsequent events, even if they occur one day later and shouldn't be considered as alarming.
Example: Kafka Streams.
Are things a bit clearer now? I know, the boundaries between some models are still blurry. For example, the difference between an asynchronous micro-batch and the dataflow model is rather subtle. The same for the one between the dataflow and the continuous update if we accept not using the watermark in the dataflow model. But I hope that despite these points, the 4 stream processing models will help you move on in your stream processing journey!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩