
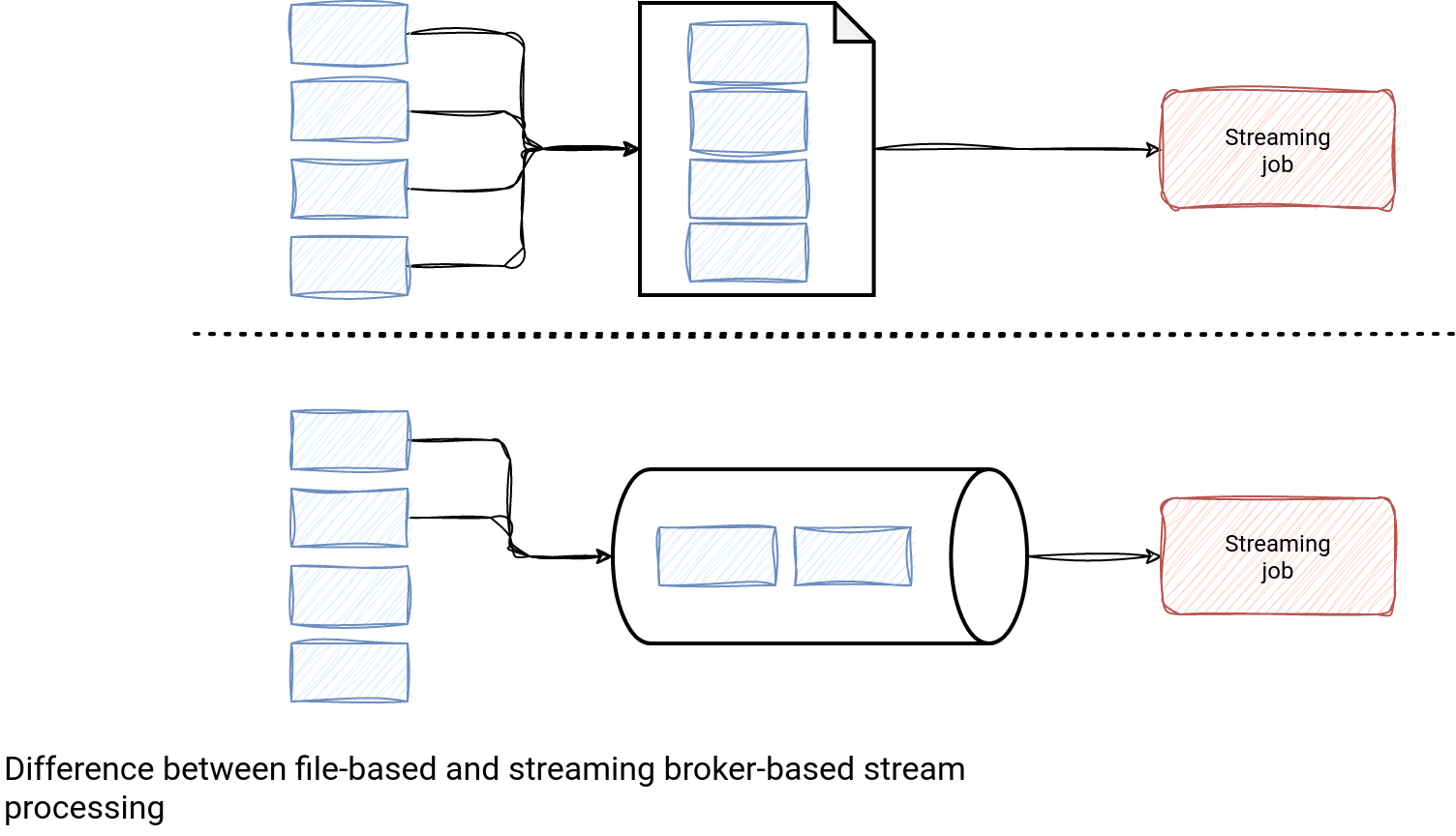
It's technically possible to process files in a continuous way from a streaming job. However, if you are expecting some latency sensitive job, this will always be slower than processing data directly from a streaming broker. Why?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
To understand why, let's see first what are the steps required for a data processing job to process files continuously; I'm going to try be the most agnostic possible here:
- Detecting new files to process - unless the job can subscribe to any notification, it'll detect new files as a difference between the already processed files and the new files created since the previous run. It involves 2 other points.
- Storing already processed files - typically, it'll be the memory-first storage for a faster access and a cheap fault-tolerance storage for resilience.
- Analyzing new files - it's often a listing request to the storage layer. The list of returned results is compared with the list of already processed files and the difference represents the files to process in the next job execution.
If you extend this to the Apache Spark Structured Streaming, it's worth adding:
- Infinite storage for the already processed files - the files in the checkpoint location can grow to the point causing the Out-Of-Memory errors.
- Latency - the infinite storage impacts the processing latency, especially when it comes to writing GB-sized files to the remote storage during the checkpoint process.
Besides, there is also a serious consequence for processing data from files - even the ones created with the brand new table file formats; at least regarding the processing latency. With files you can process the data once the file gets fully written. Put differently, if creating a file takes 30 seconds, your best latency will be 30 seconds.
File names from a streaming broker?
Even though it addreses the issue with the data retrieval overhead, it's still less efficient than the data processed directly from a streaming broker. The latency nature is due to the files themselves. Stream consumers must wait for the files to be fully created before they could even read the first line.
It's not the case for non-transactional streaming consumers. They can start processing the data as soon as the first row arrives to the stream.
Therefore streaming file names from a streaming data source and later reading them in a batch manner from your data processing framework only addresses the data preparation issue. However, most of the time solving it will be enough to see a significant performance improvement.
Streaming broker
Let's now compare this with processing data from a streaming broker. It involves:
- Tracking the last processed position in each partition - a little bit like for tracking the list of files but you can already see the storage footprint is by far smaller.
- Sending a data fetch request with the last processed position to the streaming broker - there is no step consisting of mixing already processed with the not processed yet elements. The streaming broker can quickly identify the records to process and return them to the processing job.
- Updating the last processed position in the checkpoint files - here too there is a significant difference. The update request contains the positions per partition only! So this process should be also much faster than for the file-based sources.
When it comes to the processing latency, there is no such a thing like waiting for the file to be created. Still, the data producer can work in a transactional mode and as a result, the data will be visible only after the commit. However, it can be mitigated by having smaller transactions which is not a valid solution for the files. Having more of them would increase the checkpoint size and would have a stronger memory pressure for the cache of already processed files.
Don't get me wrong, considering files as an unbounded data source of a streaming job does still make sense. You should be only aware of what processing the files from a streaming job implies and for example avoid considering them in the context of low latency requirements.
PS. After publishing this blog post, Itai Yaffe shared with me some interesting talks from the past Data+AI Summits discussing the streaming files problem. Thank you, Itai, for completing the blog post! Hopefully you, my reader, will enjoy the talks as I did!
- Stream, Stream, Stream Different Streaming Methods with Apache Spark and Kafka - I. Yaffe, Nielsen
- Road to a Robust Data Lake: Utilizing Delta Lake & Databricks to Map 150 Million Miles of Roads
- Improving Apache Spark Application Processing Time by Configurations, Code Optimizations, etc.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩