
I must admit it, if you want to catch my attention, you can use some keywords. One of them is "stream". Knowing that, the topic of my new blog post shouldn't surprise you.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Yet another house?
That was my first reaction. Data space already has a data warehouse data lakehouse, and data lake, even though it doesn't include the "house" in the name. All of them are disruptive architectural changes in the data space made possible with the evolving technologies. So, why Streamhouse?
I learned about the concept from the Streamhouse Unveiled the blog post. It identifies a gap in current data architectures that aren't well suited for latency-sensitive scenarios. Typically, you could solve it by adding a streaming broker and real-time processing technologies. It's OK but from the blog post's standpoint, it is the 4th architectural design:
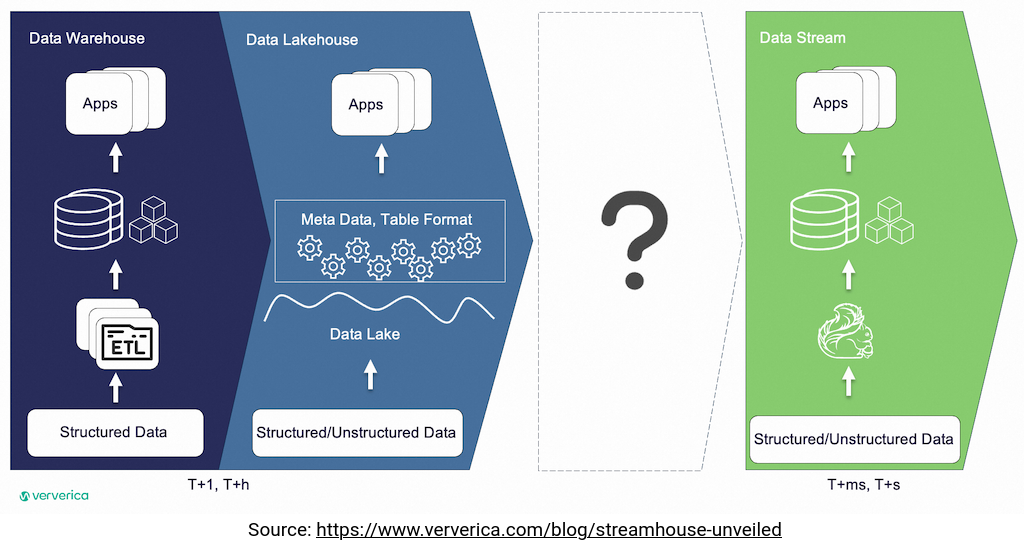
From what you understand already, the missing piece is an in-between architecture, capable of working with both classical batch and real-time scenarios. But with Streamhouse you should be able to have both in the same world.
Log-Structure-Merge trees
But how to do that? Open table file formats work already in streaming context (e.g. Change Data Capture with Delta Lake) and there are a lot of user feedbacks for running streaming jobs in Lakehouse-based architectures.
Turns out, there is a better format for handling latency-sensitive scenarios than the classical analytics columnar storage widely used in Delta Lake or Apache Iceberg. The Log-Structure-Merge tree (LSM). It's already adopted in NoSQL databases well known for their high throughput capacities (Apache Cassandra, ClickHouse) and relies on multiple storage levels, as depicted below:
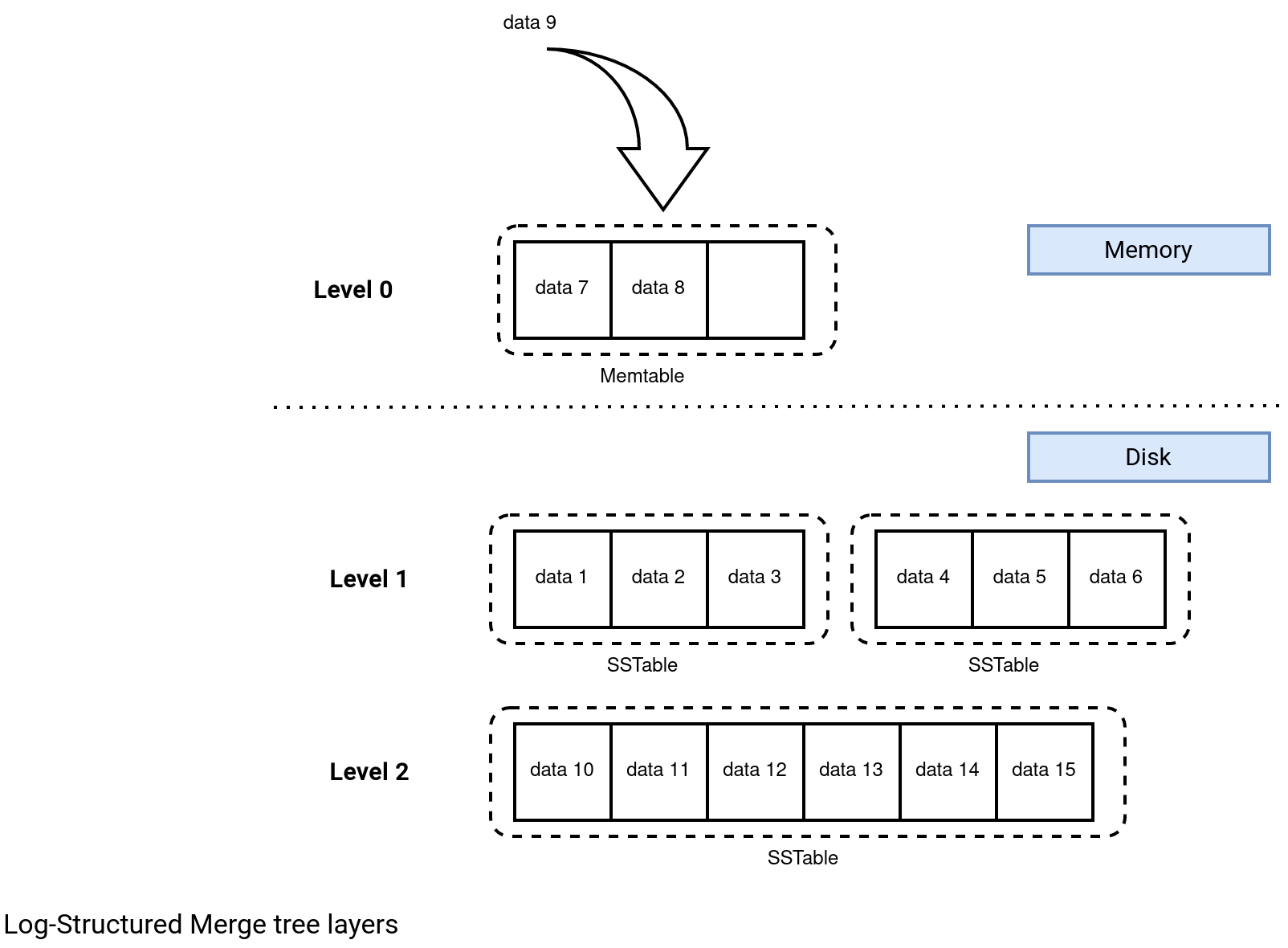
LSM divides the storage in 2 spaces. The first is in memory where a Memtable is living. This structure handles all incoming records and stores them in a sorted buffer. When the buffer becomes full, its content lands on disk in the first level SSTable. At this moment, the SSTables can be small but over time, they are merged into bigger ones. Besides creating bigger files, the merge process also improves the data quality of the upper layer by removing the duplicates and sorting the records by their keys. A duplicate is identified by a key as well and as a result, the merged SSTable stores only the most recent record for each key.
On the reading side, the consumers always start with the highest levels, i.e. from memory to the lowest SSTables. The reading flow follows the data freshness because the most recent values are available either in the Memtable or recent SSTables. Since SSTables store data already sorted, the reading process benefits from sort-based data skipping.
The format relying on LSM trees and referenced as the backbone of the Streamhouse approach is Apache Paimon.
Apache Paimon
LSM trees are only one part characterizing Apache Paimon. Besides, it provides other features, such as:
- High-level files layout. Apache Paimon relies on partitions and buckets to organize the data. Besides the data layout, they also define the concurrency as two writes running simultaneously but working on different buckets won't be concurrent.
- Runners. You can interact with Paimon from common data processing frameworks like Apache Spark and Apache Flink.
- Different table types. Primary Key table is the first type. It relies on a unique property identifying each row so that there is only one record for each key stored. You should already make the link with the LSM merge process and this type of table. Besides the Primary Key, Paimon also has Append-Only table that doesn't implement any key concept, and hence stores data as it. It can be configured as Append For Scalable Table for batch consumers focused on the OLAP functionality, or Append For Queue for consumers caring about the ordering.
- Snapshots. They represent the state of the table at a given moment.
All this together gives the following organization:
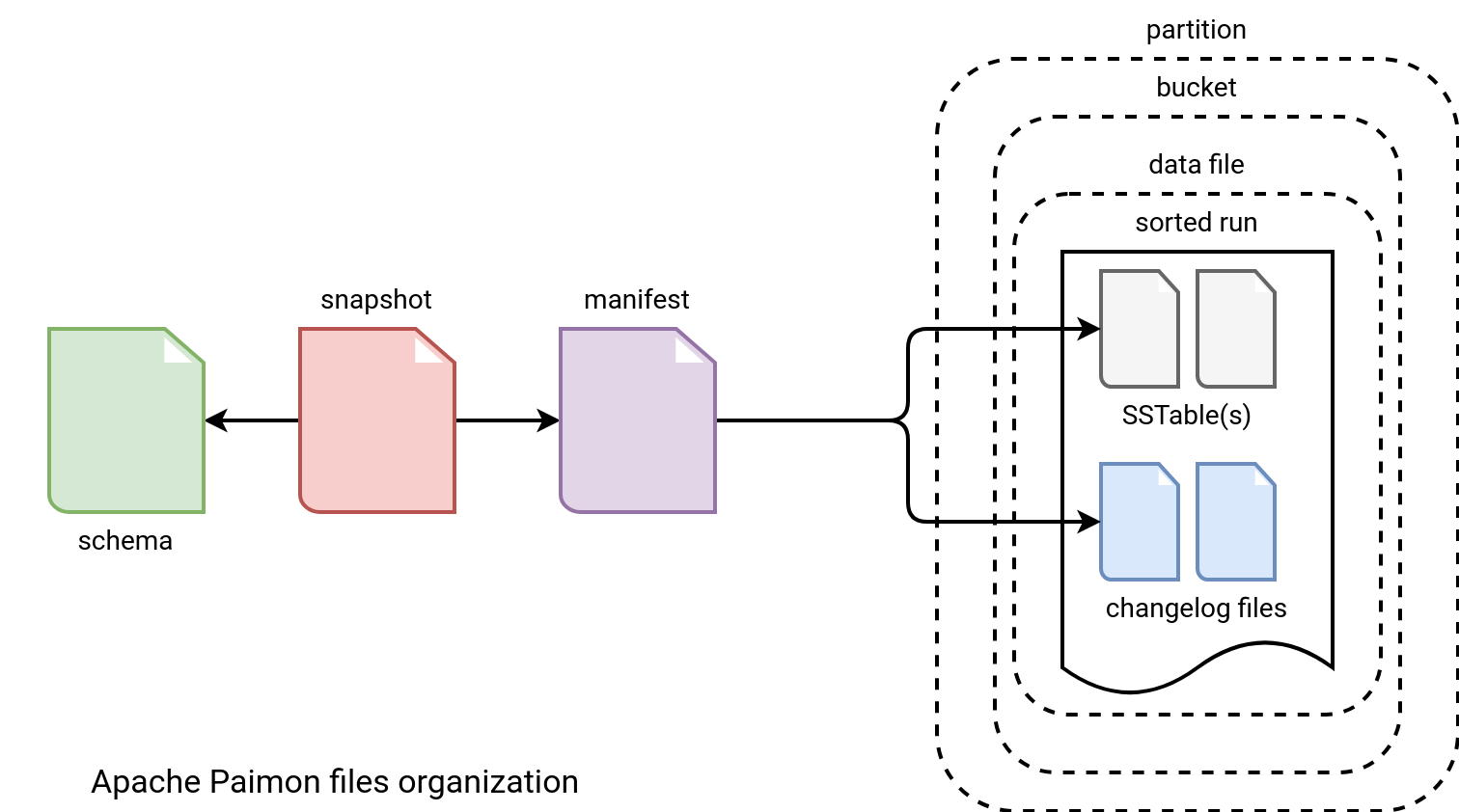
How does it work? The Snapshot references schema files and one or many manifests. The manifests on their side connects to the data and changelog files. The writing flow is greatly explained in the Flink Stream Write section of the documentation.
By the way, the files organization shares several points with the Apache Iceberg's, including snapshots and manifest. I blogged about Apache Iceberg schema last year.
Giannis closing words
To be honest with you, I was pretty unsure about my understanding of Streamhouse. That's why I asked for help a person from whom I've heard about the Streamhouse for the first time, Giannis Polyzos from Ververica, and author of Stream Processing: Hands-on with Apache Flink ,that had landed on my virtual bookshelf a few weeks ago.
Giannis completed my explanation with the following points:
Basically when it comes to Spark and the existing lakehouse tech, things started back in the Hive days and everything is more batch/microbatch oriented which for many use cases is ok. Flink is a different tech / ecosystem though and the main pillars are:
1. Easy ingestion - Flink CDC is huge and Paimon is the only project that integrates heavily with that and allows CDC ingestion with just one command. The big thing with the project is that it uses an incremental snapshot reading algorithm that allows automatic switching between historical and incremental data. So any connector in there can leverage this. In most CDC (i.e Kafka Connect) each connector has its own implementation. This project is unified and will also be donated over the new year to the Apache foundation so it can grow even more. Also has other benefits like automatic schema evolution, binlog client reuse to not put much pressure on the database and more. You can learn more about the Flink CDC here and here).
2. Strong upsert support - Hudi provides some support for upserts support, but wasn't sufficient; Iceberg v2 format also added some, but its pretty basic. Paimon uses LSM to achieve strong upsert support. Compaction is a must. Iceberg doesn't have automatic compaction (unless you use a vendor). Paimon has done lot's of work on that and also compared to the others, instead of having to do a full-merge every time due to the LSM, only the upper levels need to be merged - which is way more resource efficient.
3. Native to Flink - all the others are based on Spark and Flink is an afterthought.
4. Strong streaming reads - Paimon has the concept of consumer id. When doing streaming reads with other tech and snapshots expire, files might be deleted which results in filenotfound exceptions, Paimon leverages consumer ids to account for that.
5. True changelog that Flink uses - when dealing with updates for example you can leverage the LSM and query precious values for updates instead of having to "remember" everything... Time travel also is way more efficient because way less files need to be kept around for snapshots which results in less storage costs because LSM files can be reused and not to mention more functionality it provides.
From less technical perspective, Giannis shares his recommendations on the Streamhouse place in modern data architectures:
Basically at the moment I would say Paimon is a no-brainer if you use Flink and also if you have strong streaming requirements. But if not and you also want to integrate with Databricks or Snowflake, other lakehouse tech might make more sense for the business.
Apache Paimon is still at an early stage but the promise of a data store efficient for various latency requirements is great. Now the question is, will the lakehouse table formats adapt somehow to this challenge as well, or will we need to live in 2 houses?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Streamhouse, the next house to move into? here:
- What is a LSM Tree? Apache Paimon Streamhouse Unveiled Apache SeaTunnel and Paimon: Unleashing the Potential of Real-Time Data Warehousing
Related blog posts:
- Infoshare 2024: Stream processing fallacies, part 2
- Infoshare 2024: Stream processing fallacies, part 1
- Event time skew in stream processing
- Files streaming is quite a challenge
- Stream processing models