
In my previous post I shared with you an approach called crypto-shredding that eventually can end up as a solution for the "right to be forgotten" point of GDPR. One of its drawbacks was performance degradation due to the need to fetch and decrypt every sensible value. To overcome it, I thought first about a cache but ended up by understanding that it's not the cache but something else! And I will explain this in the blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
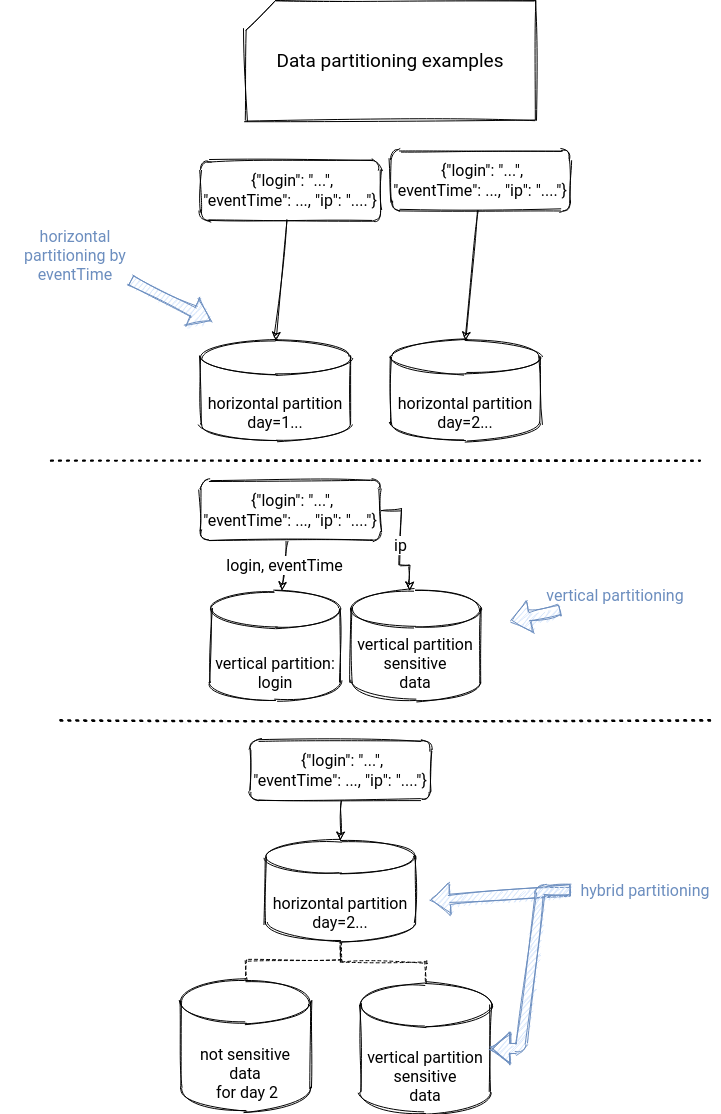
Partitioning - not only horizontal
Partitioning is a way to organize the storage of a dataset to achieve something. One of the most common goals, and at the same time, the most popular partitioning strategy, is horizontal partitioning that divides a dataset into multiple subsets. Do you process your data hourly and want to keep the amount of processed data consistent over hours? Partition it horizontally, by day and hour, so that your batch job will always work on a single hour. If not, you will probably end up with one big job processing the whole day - much difficult to control - or eventually, with hourly-based jobs filtering the input data where the last job will need to process the whole day.
But horizontal partitioning is not the single available strategy. Another one is vertical partitioning. Instead of dispatching the complete rows in different partitions, it will first divide the row into multiple partitions and dispatch them in various places. But we could also opt for a hybrid model with a subset of data put into vertical partitions, and the rest of it partitioned horizontally.
Right to be forgotten architecture
What's the link with the right to be forgotten? The picture above shows it pretty clearly. The data stored in the vertical partition can be limited to sensitive data; i.e., the attributes that can identify a user, like an IP address or an address. In that scenario, if you were asked to "forget" a user, you could overwrite the vertically partitioned dataset without the user sensitive information, or, if you want to keep the restore capability, encrypt them with the encryption key shared to the user and kept active for a fixed time.
Let's see now how to adapt the vertical partitioning to the Kappa architecture presented in the previous post on crypto-shredding:
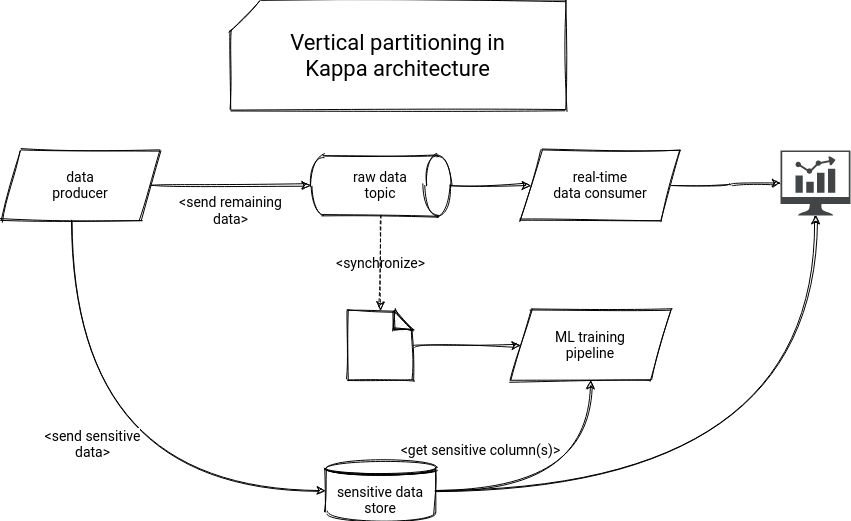
The picture is very similar, except for a few details. First, the data producer doesn't read anything. Remember that it was retrieving the encryption keys from the data encryption store for the crypto-shredding. Here, it splits the input row into 2 parts and sends one of them to this sensitive data store. The remaining data, not judged as sensitive, is later processed in the client pipelines. Whenever a pipeline needs this sensitive data, it can fetch it directly from the data store.
The good thing here is that you can easily control who can see what. Modern cloud data stores like BigQuery or Redshift, supports row- and column-level permission controls. Thanks to the physical separation of the sensitive data, you may decide that one pipeline can only query a subset of columns or rows. You can even build a view on top of this sensitive data store and expose it flexibly to the consumers. The flexibility can be translated as doing anything with the data. For example, you can expose all the columns as they are, but you also could expose some of the anonymized.
Is it all rosy?
But the vertical partitioning also has drawbacks. The first is the performance because, exactly like for crypto-shredding, we have to join the main dataset with the vertically partitioned data. It doesn't guarantee that we will not need to reprocess the raw data in the future. It can still happen if we forgot about adding one or multiple attributes to the sensitive data store. Besides, in our schema, you saw a single database with the sensitive data. And what if it's not adapted to all use cases? We could create multiple pipelines for that:
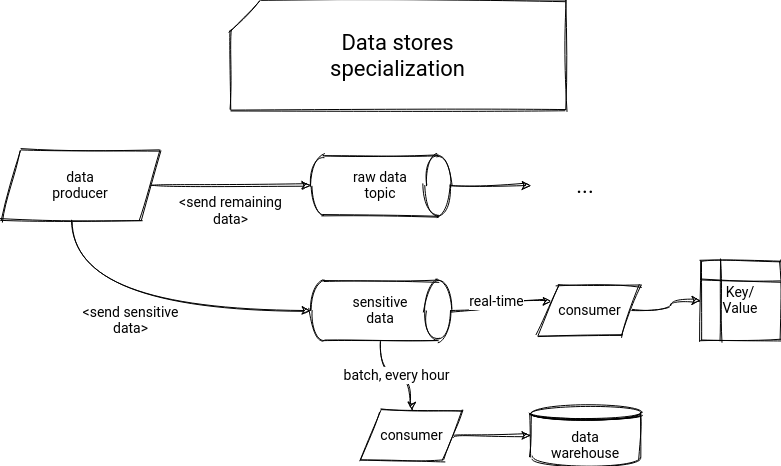
However, we still have a risk, but not related to the performance this time. The "specialized" data stores used by the customer service team can desynchronize, and for example, the web app querying the Key/Value store can miss some sensitive data that was correctly written to the data warehouse used by the BI team.
Finally, in this scenario, the sensitive part becomes a real data pipeline where we have to manage changes (e.g., with Slowly Changing Dimensions). As a result, we increase the complexity of the whole system.
However, like many other things, choosing vertical partitioning or not will be the story of trade-offs. Maybe for your case, you will need only one sensitive data store, and the complexity of such a solution will be smaller than running the "right to be forgotten" job to remove user data from all places of the system? Maybe data consistency is not negotiable, and you can't risk having many data stores to synchronize? Anyway, I hope that the article already provides a few thought-points to consider or not this approach. Thanks for reading!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data Engineering Design Patterns: Dynamic Data Overwriter
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
Horizontal partitioning is probably the most commonly used one to organize big datasets. But it also has alternative versions like vertical partitioning that I described in the new blog post ? https://t.co/JR1LCJUPiz
— Bartosz Konieczny (@waitingforcode) April 11, 2021