
MERGE, aka UPSERT, is a useful operation to combine two datasets if records identity is preserved. It appears then as a natural candidate for idempotent operations. Although it's true, there will be some challenges when things go wrong and you need to reprocess the data.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The MERGE operation is a universal data combination action that you can use to add, update, or even remove rows. The next snippet shows a query that, depending on the MATCHED outcome, does one of these 3 things:
MERGE INTO devices_output AS target USING devices_input AS input ON target.type = input.type AND target.version = input.version WHEN MATCHED AND input.is_deleted = true THEN DELETE WHEN MATCHED AND input.is_deleted = false THEN UPDATE SET full_name = input.full_name WHEN NOT MATCHED AND input.is_deleted = falseTHEN INSERT (full_name, version, type) VALUES (input.full_name, input.version, input.type);
However, behind this apparent simplicity, MERGE hides some operational challenges. At the end of the day, you won't run a MERGE alone. Instead, the operation will be part of a more or less complex data processing environment, where things can go wrong. And what to do when things go wrong? It requires more explanation.
Data looks bad
The bad first thing can come from your data provider. If you get a wrong or incomplete dataset, you'll expose these inconsistencies to your downstream consumers. But lucky you, the solution for this problem doesn't require any action on your own. In that case, you should ask your data provider to generate a new dataset that will fix the mistakes introduced by the previous one. Generating new dataset covers two errors categories:
- Incompleteness - if the previous version was incomplete, new rows will simply append with the INSERT part of the MERGE.
- Row issues - If some of the records were wrong in the previous version, the new version will correct them with the UPDATE part of the MERGE.
The single requirement for your provider is to keep the same ids between the buggy and fixed dataset versions. If it's the case, you can simply relaunch the previous job execution. But unfortunately, things are not always that simple and sometimes the issue comes from your side.
Code looks bad
If the problem doesn't come from your provider, you may be in trouble. Why "may be"? It depends whether you do care of the dataset consistency while reprocessing or not. Let me explain it with the picture below where the green box is the last correctly written version and all the red ones are the buggy ones:
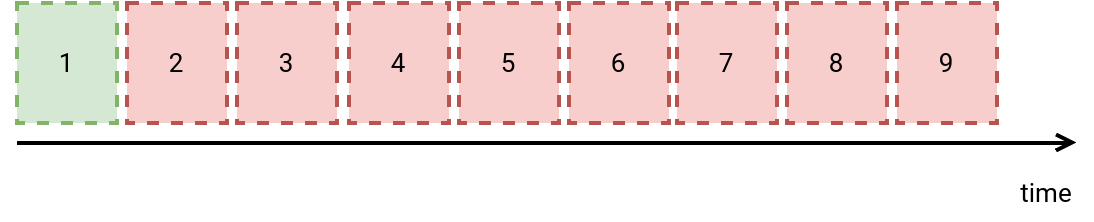
When you decide to fix the bug by reprocessing the dataset for the past wrong executions (2-9), you can approach the problem with two different points of view:
- Incrementally overwrite changes from the most recent version (9 in our example). Here you allow some temporary inconsistencies while reprocessing. Put differently, when you replay the pipeline from the version 2, you will replay the pipeline on top of the dataset generated by the version 9, and not 1! Consequently, your consumers will see all the wrong data between 2 and 9.
- Restore the table to the most recent valid version. Here you don't want to allow temporary inconsistencies exposed to the consumers. In that case, you want to reprocess the pipeline from the last valid version, thus the version 1 in our example.
As the first use case doesn't require any action on your side, in the rest of this blog post let's see how to address the second one with data stores supporting versioning, like Delta Lake.
Version mapping
Even though from our example you could think that each pipeline's run increments the version by 1, it rarely happens that way in real life because between two pipelines runs you might have some housekeeping actions, like compaction in Delta Lake. For that reason, the solution to the second scenario requires some extra implementation effort.
Without this consistency in mind, the pipeline could just run a job running the MERGE statement. However, if consistency is important, the single MERGE won't be enough as you won't be able to figure out the version to restore. For that reason, the MERGE operation needs a mapping table between the pipeline runs and the generated version by each run. The following schemas introduces the state table and extra steps in the pipeline:
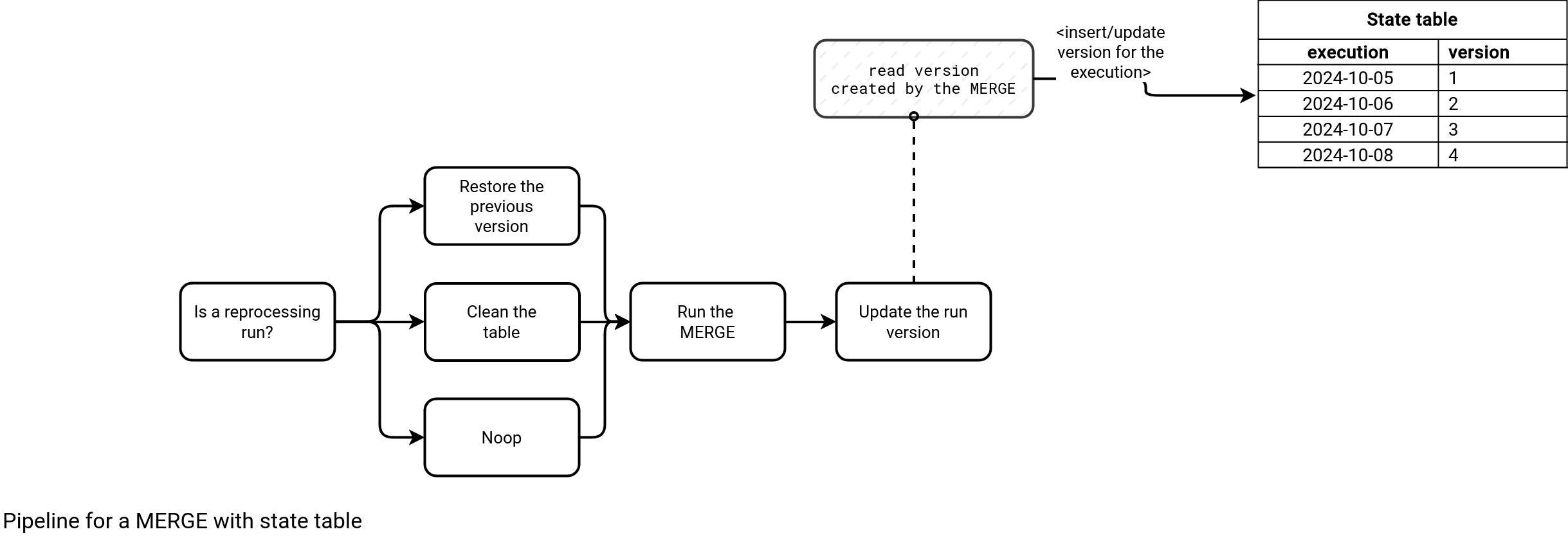
These extra steps control the behavior of the workflow and have the following responsibilities:
- The Is a reprocessing run? task verifies whether the execution should be reprocessed or not. The decision depends on the version written for the previous execution, thus:
- If there is no version written for the previous execution, it means we're reprocessing the first pipeline run ever. In that case, we need to delete all rows, for example with a TRUNCATE TABLE statement.
- If there is a previous version and the version is the same as the most recent version written by a MERGE operation, then we have nothing to do (Noop task).
- If the previous version is lower than the most recent version written by a MERGE operation, then it means we're reprocessing the data. In that case, the pipeline needs to restore the table to the previous version.
- The Run the MERGE task performs the MERGE operation top of the eventually restored table. Put differently, it executes on top of a consistent environment.
- The Update the run version reads the most recent version created by a MERGE statement and updates the state table for the corresponding execution time.
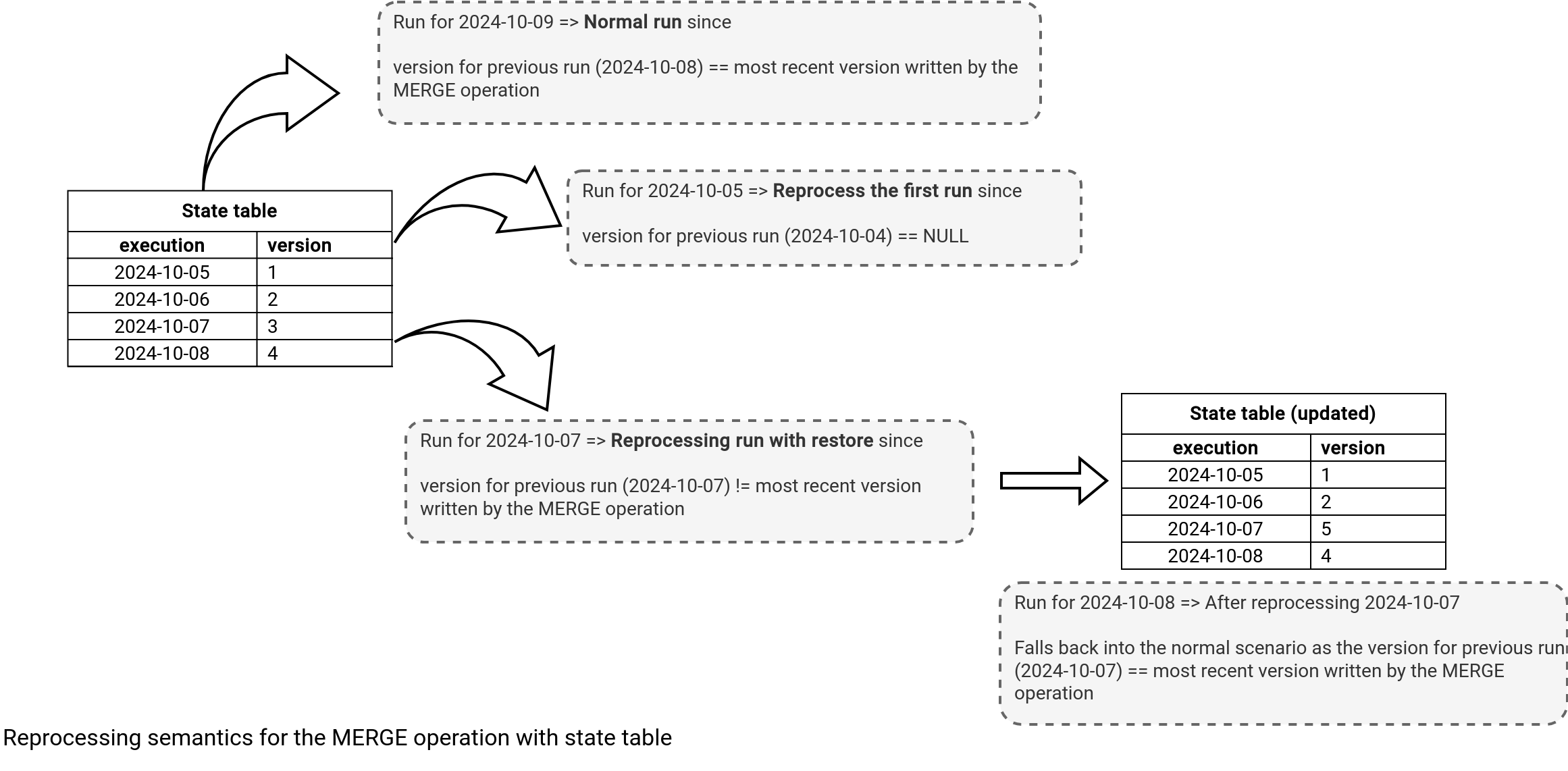
Before going into implementation details, let's see if it works. In the next schema you can see three different scenarios that I explained before. The pipeline needs to deal with normal run, reprocessing for the first run, or reprocessing for any other run. As you can notice, the restore action in case of the last scenario happens only once, for the first reprocessed date:
Code
Let's see now some code that might be helpful to implement this design pattern with Delta Lake. First, the code responsible for determining the strategy (restore, noop, truncate). This code needs to interact with the table's history and with the state table:
maybe_previous_job_version = spark_session.sql(f'SELECT delta_table_version FROM versions WHERE job_version = "{previous_execution_date}"').collect()
if maybe_previous_job_version:
previous_job_version = maybe_previous_job_version[0].delta_table_version
versions_history = spark_session.sql('DESCRIBE HISTORY default.numbers_letters')
last_merge_version = (versions_history.filter('operation = "MERGE"')
.selectExpr('MAX(version) AS last_version').collect()[0].last_version)
if previous_job_version == last_merge_version:
return "NOOP"
else:
return "RESTORE"
else:
return "TRUNCATE"
Once the pipeline knows the path to follow, various things happen. As the "NOOP" and "TRUNCATE" tasks are self-explanatory, let's focus on the "RESTORE" action because it has some special behavior when the table was impacted by other operations than MERGE. For example, our table might have been compacted or reordered. In that case, the versions between two MERGE operations won't increase by 1. Instead, the state table might be looking like in the next picture:
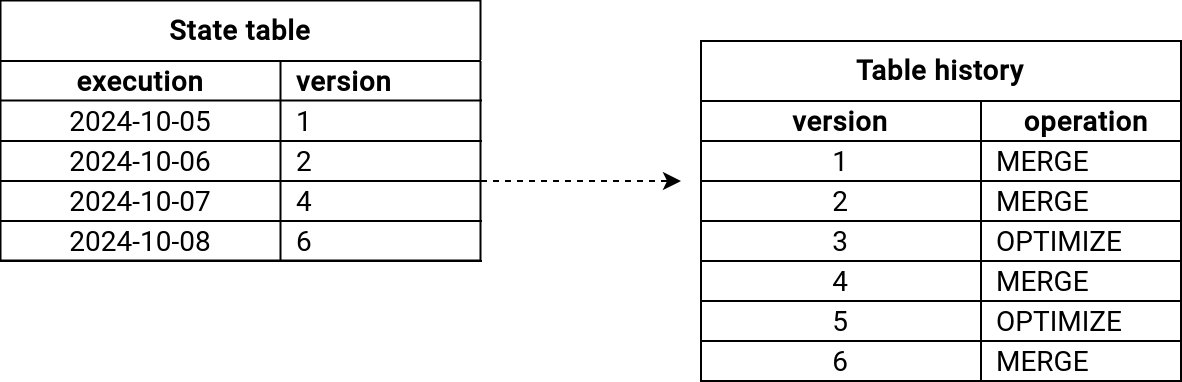
You might already see the formula to get the version to restore, don't you? Yes, the version to restore is equal to the version created by the current run minus 1. If you do care only about the MERGE operations, you should restore the table to the version created by the previous run (previous_job_version in the snippet before).
However, the overall solution has some gotchas.
Gotchas
First, you should be aware that the MERGE itself is not a 100% idempotent operation. For example, if your merging logic involves an auto-incremented counter or blindly appended items to a list, the idempotency will be broken in a kind of fan-out processing like this and automatic job retries in case of a failure:
apply_merge_on_dataset(...) write_additional_records_to_side_output(...)
For that reason you shouldn't consider the MERGE as a magic solution to all the problems. Always keep in mind the type of the operations the MERGE performs and the execution context, such as other writing processes within a job.
Second, the query retrieving the last MERGE doesn't distinguish between the pipeline's MERGE and other MERGEs. Although it's a good practice to have only a single writer for the sake of simplicity, the architectures and solutions evolve. Today's single-writer may be replaced in the future. In that case, to distinguish between MERGE origins you can use the userMetadata attributes defined at each commit.
Finally, the VACUUM and compaction operations can break the recoverability. Simply speaking, you may not be able to recover the vacuumed versions. To mitigate this, you can try to align the data retention with the max reprocessing period. For example, if you configured the retention to 2 months and you will never reprocess data older than 2 months, the VACUUM gotcha doesn't apply to you.
MERGE with snapshot
If you need a shorter retention policy than the allowed reprocessing period, or if you are regularly spotting bugs after the retention period, there is another option for the MERGE. But again, it also has gotchas so if you're looking for a perfect solution in this blog post, sorry, it won't be here.
The idea here is to replicate the table every x runs and use this copy as initial snapshot to restore the last valid version. For example, if we configure the pipeline to snapshot every 3 runs, it would create 3 clones, as in the next image:
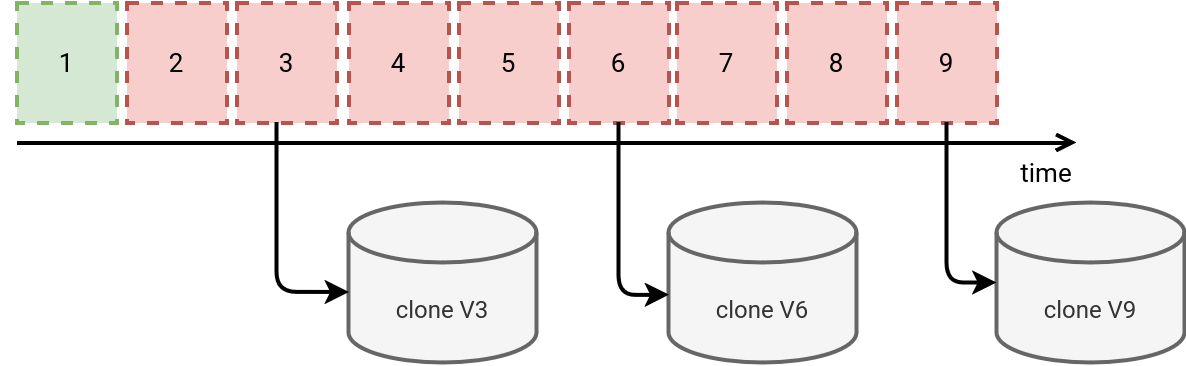
As you can see, whenever you need to replay a version, you need to rollback the table to the previous valid snapshot. For example, reprocessing version 5 would mean rollbacking to clone V3.
The modified pipeline replaces the state table actions by the clone-related ones, as shows the next schema:
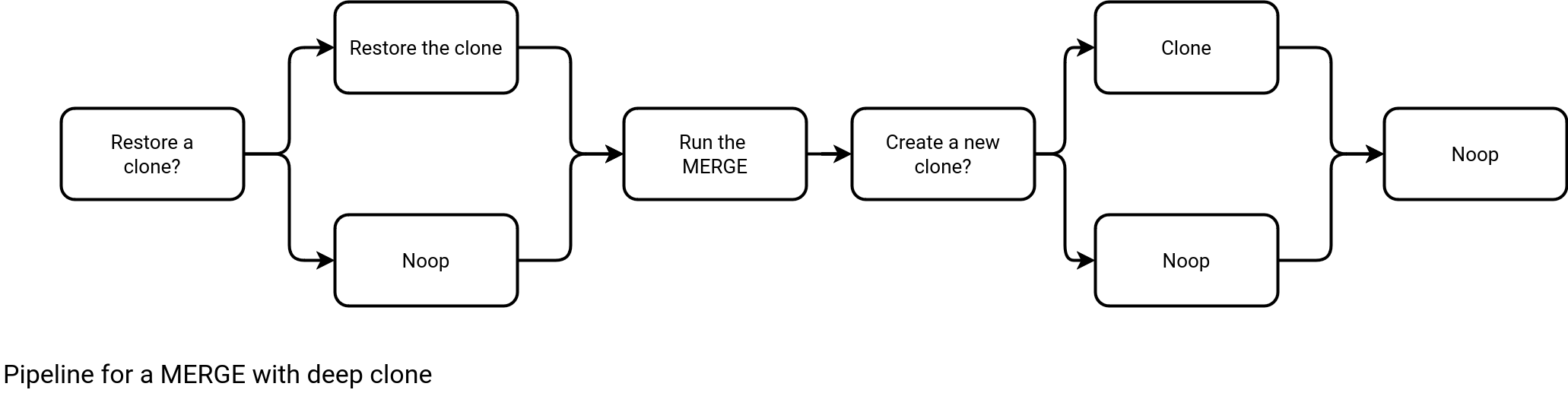
Although this approach is not impacted by the missing transaction files issue, it also has some drawbacks:
- Creating a snapshot requires copying the data. It may be a costly operation for big tables. To mitigate the issue you could reduce the cloning frequency, but the risk would be having more pipeline runs to reprocess.
- The reprocessing logic can't target a specific version as it always needs to find the closest snapshot. Put differently, if you create snapshots every 100 runs and you need to replay the data from the 99th execution, you will have to restore the version 1, thus to reprocess 98 additional runs.
- If your replica creation overwrites a table, you will deal with data retention as well. If you don't want to do this, increase the retention duration or write each replicated dataset as a part of a partition, such as v1/, v3/, v6/, etc. where the number corresponds to the commit version from the original table.
- Housekeeping may be challenging as well. If you reprocess the MERGEd table, you'll need to clean irrelevant replicates as well.
With all that said, the mitigation strategy using the snapshot is not all roses either. Consequently, it might be much easier just to increase the retention period on the MERGEd table and pay more for storage, instead of adopting this replica-based approach which in the end also impacts the storage costs (and besides, looks more challenging).
Despite the gotchas, MERGE is still a great way to process incremental changes in datasets. The operation reduces the data volume to process and at the same time, guarantees idempotency if the changes don't involve any side effects. But you should use it with caution and be aware of the shortcomings presented by the end of this blog post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩