
Thanks to the most recent data regulation policies, we can ask a service to delete our personal data. Even though it seems relatively easy in a Small Data context, it's a bit more challenging for Big Data systems. Hopefully - under the authorization of your legal department - there is a smart solution to that problem called crypto-shredding.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
TL;TR: I'm not a lawyer and since I found some contradictory information whether crypto-shredding really solves the "right to be forgotten" problem ([1], [2]), it's better to check this with your legal department. Nonetheless, the concept is so fascinating and I decided to decrypt it in the following 4 sections.
Right to be forgotten
In a nutshell, one of GDPR's points is the "right to be forgotten". In other words, you can ask the website you're using to remove any data related to you. In case of Small Data systems, like the ones using few data stores with relatively small volume, a simple DELETE ... FROM ... WHERE customer_id = ${user_to_forget}-like query should do the job. But what if our system is more complex and the volume of data a way bigger?
We can still write the delete queries for each database or even launch a distributed data processing job overwriting the files containing the user's data in our data lake storage. It's a valid approach from a technical standpoint, but it also has some drawbacks. First, what if the removal query came from a hacked account? The physically removed data is hard to recover. What if we have a lot of data to process and every removal query ran on our data lake takes 7 days to be fully executed? And worse, we're getting more and more of such "removal" demands? It can have a significant impact on our billing (cloud) or workload capability (on-premise).
Crypto-shredding addresses these 2 issues but, of course, not without sacrificing anything. As with a lot of things in software engineering, using it or not will be a matter of trade-offs!
Implementation design
The main idea behind crypto-shredding is to encrypt all personal attributes with a unique encryption key for every user. When the data arrives in your system, it's already encrypted, and the "right to be forgotten" action is just a matter of removing the encryption key of the user from the encryption keys store. And it also works for the streaming brokers if the data producers send the encrypted data. The whole architecture could look like in the following schema:
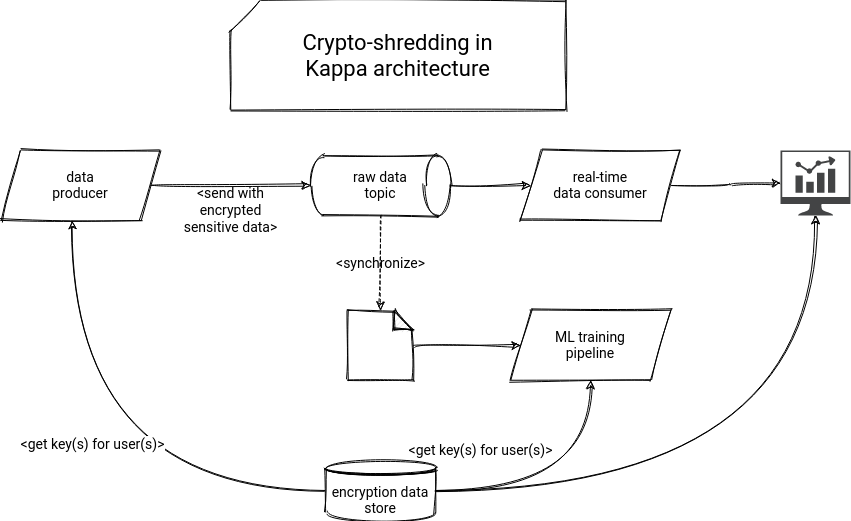
You can even go further with this approach and implement temporary protection against malicious actions on behalf of the user by encrypting the encryption key with a passphrase received by one of the official communication channels. Thanks to that, if for whatever reason the data removal demand didn't come from the real user, there is still a possibility to recover the data, unless the communication channel was hacked too.
Technical implementation
Regarding technical implementation, sensitive data can be encrypted and decrypted with various programming languages. In the demo below, I'm focusing on SQL, Scala, and Python, which in my opinion, are the most data engineering-friendly. However, I'm pretty sure you can find corresponding implementations in other languages because, remember, the data you generate may be exposed in different ways - not only from a static database but maybe also from a micro-services architecture implemented in Ruby or NodeJS:
Cons
Crypto-shredding looks great on the paper. It deals with data in-rest and data in-motion, it considerably reduces data removal costs, but it's not all rosy. The first drawback is the complexification of all pipelines using the encrypted attributes. ML pipelines have to decrypt any data needed for training, and reporting tools have to do the same before preparing data visualization queries or displaying the dashboards.
Also, this complexified data retrieval will have an impact on the performances. Every processed user will require an extra step to retrieve the encryption key and decrypt the values (CPU impact).
Can we do better? I started to type that we could use the cache layer, but the encryption table only contains the encryption keys! And thanks to this reflection, you will read the second blog post from "the right to be forgotten" series next week.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Right to be forgotten patterns: crypto-shredding here:
- Crypto shredding: How it can solve modern data retention challenges Handling GDPR with Apache Kafka: How does a log forget?
Related blog posts:
- Data Engineering Design Patterns: Dynamic Data Overwriter
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
Today I would like to share a pattern called crypto-shredding that I discovered while preparing for GCP Data Engineer certification from the "Google BigQuery: The Definitive Guide..." book ? https://t.co/wvARdushqZ
— Bartosz Konieczny (@waitingforcode) April 4, 2021