
Some time ago I found a site listing Big Data patterns (link in "Read also" section). However, that site describes them from a very general point of view and it's not always obvious to figure out the what, why and how. That's why I decided to start a new series of posts where I will try to describe these patterns and give some more technical context.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post starts with the explanation of the pattern called Automated dataset execution. Please notice that like described in the pattern page from "Read more" section, the pattern seems to be more about an ETL technology like Apache Airflow, AWS Glue or GCP Dataprep. But instead of detailing each of these tools, which could be difficult to do well in one blog post, I'll focus here on one of the aspects shared by them, on data ingestion methods.
Automated dataset execution explained
The pattern addresses the problem of automatization of data processing pipeline. As stated in the definition, a not automatized task in data processing is very inefficient. Nowadays, the data comes often at high velocity and requiring a human intervention to process it would be a big step back in the evolution.
The solution proposed in this pattern is a tool enabling automatic data processing and it's used in everything related to the data processing automatization, like for instance an orchestration tool.
The implementation of the pattern consists of creating a workflow, either from a GUI or from the code. The latter approach is much better. By using purely graphical interfaces, you won't be able to automate your deployment process. It's not the case of the code which is deployable much more easily.
Once defined, the workflow is later submitted to the workflow engine. The engine, according to the trigger conditions, automatically starts the data processing steps. And in this post I'll focus on different solutions you can use as the trigger conditions in nowadays data architectures.
Data ingestion patterns
Very often the first task of automated dataset execution workflows is the data ingestion. There are different ways to create them. The first and the easiest one uses cron triggers. That means you'll execute given workflow at a regular temporal (daily, weekly or monthly) interval. If you've already done some applications in early 2000's web domain, you've certainly worked with cron jobs to do some website background processing at some specific time. In the data context, cron trigger is exactly the same - we define the time and the logic to execute. However, you should always take care of the data presence. That said, the cron shouldn't trigger the workflow when its input data is missing.
Another ingestion method uses event-based architecture, like the one proposed by AWS. Here you don't need to plan the workflow execution. Instead, your processing logic executes when some specific events happen. For instance, an event can be the fact of writing a new file on S3. The event-based data ingestion has the advantage to be executed only when there is the data to process. In the flip side, event-driven jobs are more difficult to orchestrate. Adding some dependency between consecutive events and monitoring everything is more difficult than doing the same in a classical ETL batch-based pipeline. Nevertheless, you can find a sample implementation of event-based data ingestion in the following schema:
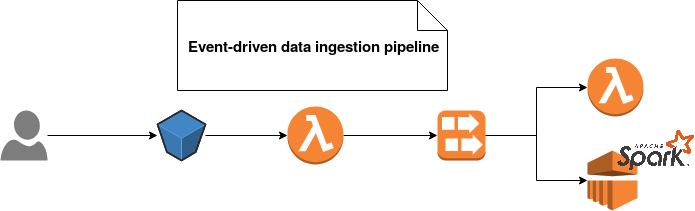
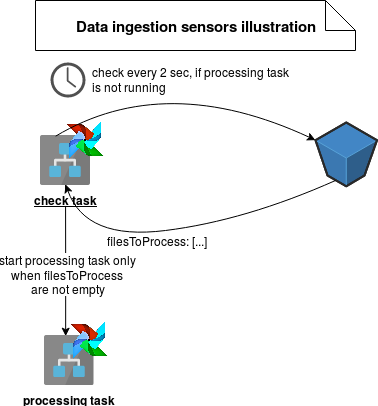
The third ingestion pattern is very similar to the previous one but it uses less reactive concept called sensors. You can find its implementation in Apache Airflow framework. Like event-based one, this method also executes only when the data to process is present. However, it doesn't start as soon as the event is observed. Instead, the workflow engine is listening to a specific place (a bucket, a table in a database, ...) and it executes the pipeline only when it discovers an unprocessed element. With an extra mechanism to remember the creation time of the last processed element, it's much easier to orchestrate than the event-based one. On the other side, it's also much less reactive - it enforces synchronous processing. You can find its illustration below:
The final method uses messaging technique. It can be either a stream or publish/subscribe solution. The former one reads all data arriving continuously. In the latter, the ingestion step can subscribe only to the messages it wants to process (eg. topic exchange in RabbitMQ). Usually, the amount of data is much smaller than for the streaming case. But the drawback is the volatility of messages. By default, they're lost when the reader acknowledges their successful processing. On the other side, streaming solutions are often based on append-only logs where you can make a seek for any position as long as the TTL of the message doesn't expire. But on the other side, your consumer must read all messages.
The patterns are everywhere and very often they help to not reinvent the wheel. Automated dataset execution is one of the first Big Data patterns coming from the "Read also" section's link, described in this blog. As we could see, the pattern addresses mostly jobs execution problematic and since it's hard to summarize in a single post, I decided to cover one of the problems that the pattern tries to solve - data ingestion. As you can see, there are 4 main data ingestion methods: from pretty static cron-based rule to more dynamic even-based one. Each of them has its own advantages and drawbacks but always at least one of them should fit to any data ingestion problematic.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Big Data patterns implemented - automated dataset execution here:
Related blog posts:
- Big Data patterns implemented - fan-in ingress
- Big Data patterns implemented - automated processing metadata insertion
Today I start a new series of post about #data engineering patterns, inspired by Arcitura Big Data patterns listing. The first post post talks about data ingestion method that I linked to the Automated Dataset Execution pattern https://t.co/VW1EY69fyy
— Bartosz Konieczny (@waitingforcode) April 11, 2019