
Sometimes metadata is disregarded but very often it helps to retrieve the information easier and faster. One of such use cases are the headers of Apache Parquet where the stats about the column's content are stored. The reader can, without parsing all the lines, know whether what is he looking for is in the file or not. The metadata is also a part of one of Big Data patterns called automated processing metadata insertion.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The series about Big Data patterns continues and this post covers the metadata insertion. Like for the previous posts, this one will also start with a short theoretical explanation of the concept. The next part will contain its simple implementation with Apache Spark.
Metadata and big data
The goal of the automated processing metadata insertion pattern is to facilitate the tracking of the data pipeline execution. Let's take the following example:
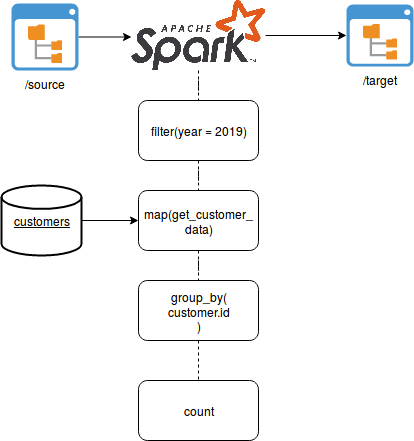
As you can see, the pipeline starts by reading several files from a distributed file system and filtering the input entries. Later it enriches them with some external information and finally makes some aggregations. Therefore, the volume of the data decreases at every step. But how can you be sure that the filtering isn't too aggressive or the enrichment step doesn't miss a lot of extra data resulting in much fewer aggregates than usually? You should be able to control that from the unit tests but since the data source may evolve, you should also be able to say that something goes wrong by looking directly at the data pipeline execution. And that's the place where the metadata may be useful. Very basic metadata can track the volume of the data produced at every step. And our previous pipeline could be redesigned as:
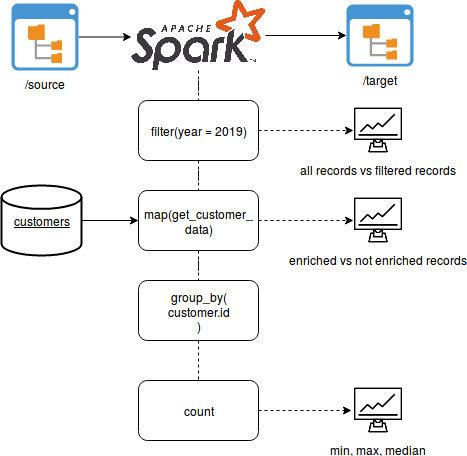
Among the metadata you can include not only the global number of elements but also provide more fine-grained details, like for instance the details of applied filters or the reasons for not enriched data.
Automated processing metadata insertion with Apache Spark
In Apache Spark you can handle the metadata in different ways. For instance, you can generate partial, executor-based results and send them directly to your monitoring layer. Potentially you will need to add there an aggregation layer. On the other side, you can provide this aggregation layer directly with the computation logic and use accumulators, exactly as I do in the following example:
"metadata" should "be automatically inserted after each step" in {
val InputOrders = Seq(
(1L, 1L, 2018), (2L, 1L, 2019), (3L, 2L, 2019), (4L, 3L, 2018), (5L, 3L, 2019), (6L, 3L, 2019)
).toDF("order_id", "customer_id", "year")
val filteredAccumulator = new LongAccumulator()
val allOrdersAccumulator = new LongAccumulator()
sparkSession.sparkContext.register(filteredAccumulator)
sparkSession.sparkContext.register(allOrdersAccumulator)
val filteredOrders = InputOrders.filter(order => {
val is2019Order = order.getAs[Int]("year") == 2019
if (!is2019Order) filteredAccumulator.add(1L)
allOrdersAccumulator.add(1L)
is2019Order
})
import org.apache.spark.sql.functions.udf
val resolveCustomerName = udf(EnrichmentService.get _)
val mappedOrders = filteredOrders.withColumn("customer_name", resolveCustomerName($"customer_id"))
val notEnrichedCustomersAccumulator = new LongAccumulator()
val enrichedCustomersAccumulator = new LongAccumulator()
sparkSession.sparkContext.register(notEnrichedCustomersAccumulator)
sparkSession.sparkContext.register(enrichedCustomersAccumulator)
val ordersPerCustomer = mappedOrders.groupByKey(order => order.getAs[Long]("customer_id"))
.mapGroups {
case (customerId, orders)=> {
var counter = 0L
orders.foreach(order => {
// We suppose the same customer_name value for all rows
if (counter == 0) {
if (order.getAs[String]("customer_name") == null) {
notEnrichedCustomersAccumulator.add(1L)
} else {
enrichedCustomersAccumulator.add(1L)
}
}
counter += 1
})
(customerId, counter)
}
}.select($"_1".alias("customer_id"), $"_2".alias("orders_number"))
ordersPerCustomer.show()
filteredAccumulator.value shouldEqual 2
allOrdersAccumulator.value shouldEqual 6
notEnrichedCustomersAccumulator.value shouldEqual 2
enrichedCustomersAccumulator.value shouldEqual 1
}
}
object EnrichmentService {
private val EnrichmentData = Map(3L -> "User 3")
def get(userId: Long) = EnrichmentData.get(userId)
}
Adding the metadata management is generally straightforward thanks to the extensibility of Apache Spark's accumulators. However, as you can see in the above snippet, it's not always easy to include in the code. It was quite fine for filtering operation but when I needed some unicity after the grouping operation, I had to complexify the simple count which normally should be written as mappedOrders.groupByKey(order => order.getAs[Long]("customer_id")).count(). I could also add another processing branch for mappedOrders.filter("customer_name IS NULL").groupBy("customer_id").count() but it would be a little bit against the global architecture of this pattern. Also, any failure of such additional metadata logic could fail the whole job and that's not what we want here - the most of the cases, the metadata should be optional. It helps to monitor the processing but if it contains a bug, it shouldn't invalidate the generated output because both parts are independent in the sense of correctness.
The metadata is quite important the data processing logic. Alongside the monitoring layer, it helps to get meaningful insight into the efficiency of that logic. Simply by comparing the number of, for instance, filtered items or not enriched records, you can figure out whether something went wrong with our pipeline or not.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Big Data patterns implemented - automated processing metadata insertion here:
Related blog posts:
- Big Data patterns implemented - fan-in ingress
- Big Data patterns implemented - automated dataset execution
In the second post about #data engineering patterns implemented I present automated processing metadata insertion with #ApacheSpark accumulators example https://t.co/lrkapv6KKG
— Bartosz Konieczny (@waitingforcode) April 17, 2019